







Hadoop自学笔记之:reduce端利用辅助排序手动实现连接
1.简述:
hadoop在开发过程中可能需要将输入的数据集像操作数据库时,对关系型数据库表的连接这样的操作,将输入的数据将进行连接操作
2.原文:
MapReduce能够执行大型数据集间的“连接操作”,但是,自己从头写相关代码来执行连接的确非常棘手。除了写MapReduce程序,还可以考虑采用更高级的框架,如Pig、Hive、Caseding、Cruc或Spark等,他们都将连接操作视为整个实现的核心部分
这里我们通过《hadoop权威指南第四版》中P264页的内容及案例进行连接操作的实现的学习,同时,是对P264页内容的理解
3.原文案例简述:
假设有两个数据集:气象站数据库和天气记录数据库集,将气象站记录和天气记录连接演示图:
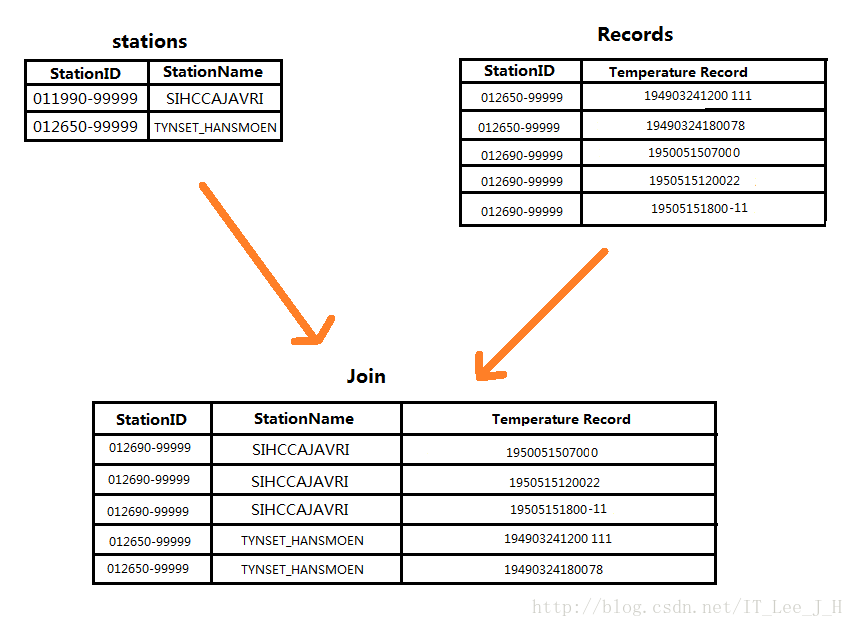
实现连接数据集的连接分为Map端和Reduce端执行连接操作,map端的连接很好理解,这里我们对难理解的reduce端的连接实现(相当于SQL的where连接的效果)进行剖析
4.基本实现思路:
4.1说明:
本例使用一个mapreduce实现只将不同类型的多个数据集进行连接操作,该MapReduce的最终输出结果就是将多个大型数据集连接操作的结果。
4.2步骤:
1. Map为各个记录标记源(原文),气象站信息为0,天气数据为1
2. 使用连接键作为map输出键(原文),格式:“stationID 0/1”
3. 使键相同的记录放在同一个reduce中(原文)
4. (关键)利用辅助排序为连接操作进一步做准备(个人理解)
5. (关键)通过自定义一个reduce分组过程,实现“连接操作”(个人理解)
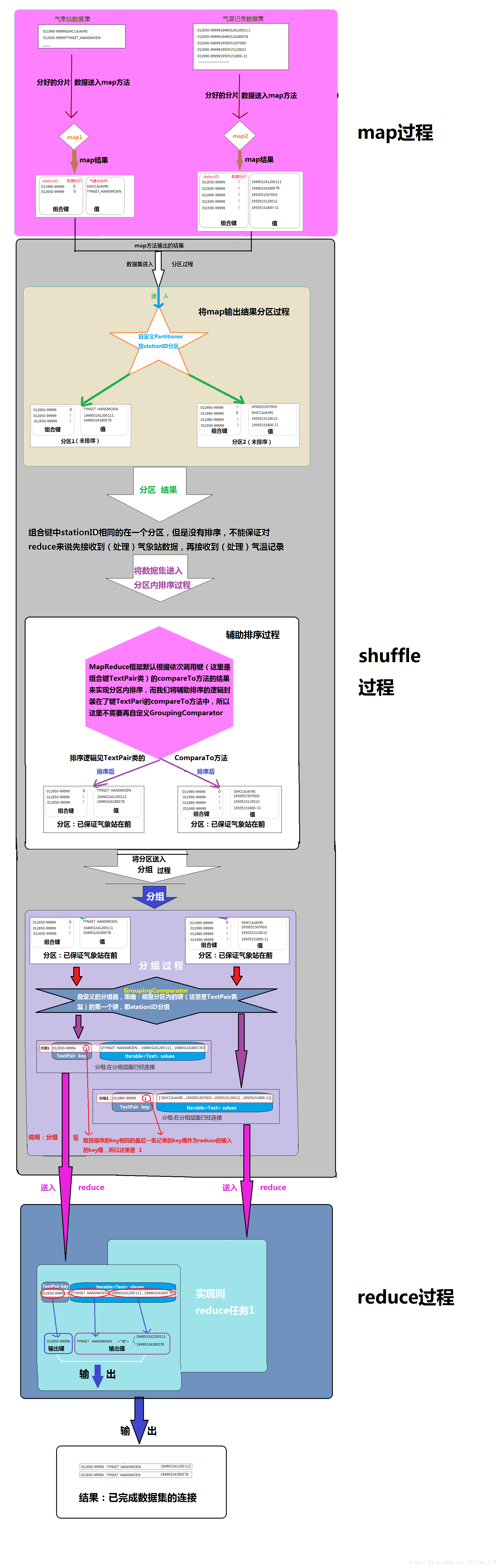
4.3MapReduce分工:
Map:
将目标数据集按照各自的格式处理出来,合理标识数据源(决定类似左连接还是右连接的效果),并将连接条件(stationID)扩展成组合键的形式输出。
Shuffle:
将两个“内容格式”的map输出,stationID相同的分到一个分区内,并将分区排好序,保证reduce先获取(处理)到气象站信息,再获取(处理)到天气记录。
Reduce:
只执行一个将目标分组写出的操作
5.使用技术:
hadoop多输入
MapRuduce辅助排序
自定义Reduce分组
5.1技术阐述:
5.1.1多输入:
5.1.1.1使用原因:
由于此时对大型数据集进行连接操作,需要多个数据集的输入并且每个数据源有自己的格式,默认的单数据源输入将无法满足我们的需要,那么我们需要采用多输入(使用MultipleInputs类)同时为每个不同的格式的数据集写一个map并绑定,来方便地解析和标注各个源。
5.1.1.2操作位置:
在多数据集的不同处理输入的map阶段
5.1.2MapReduce辅助排序
5.1.2.1使用原因:
由于在map的输出结果中,使用了组合键,为了保证对于reduce来说,先收到气象站的数据,再收到气象记录,需要用辅助排序来实现。
5.1.2.2操作位置:
Shuffle过程中,在分区送给reduce处理前的排序阶段。
5.1.3自定义reduce分组
使用原因:
真正实现连接的代码部分,但是注意这里的实现结果只是为了reduce方法直接将“连接后的分组”写出,将同时包含有气象站信息和天气记录两种形式内容的分区数据,转成以气象站id为键的统一内容的“中间数据”。
如图:
操作位置:
reduce内部的分组过程
5.1.4 reduce方法
这里的reduce方法,只是将“连接后的分组”,写成目标格式的数据输出(最终数据的连接)
6. 实现过程代码及效果展示
准备过程:
准备组合键对象Textpair类
代码:
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair>{
private Text first;
private Text second;
public TextPair(){
set(new Text(),new Text());
}
public TextPair(String first,String second){
set(new Text(first),new Text(second));
}
public TextPair(Text first,Text second){
set(first,second);
}
public void set(Text first,Text second){
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if(cmp != 0){
return cmp;
}
return second.compareTo(tp.getSecond());
}
@Override
public String toString() {
return first+"\t"+second;
}
@Override
public boolean equals(Object o) {
if(o instanceof TextPair){
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
@Override
public int hashCode() {
return first.hashCode()*163+second.hashCode();
}
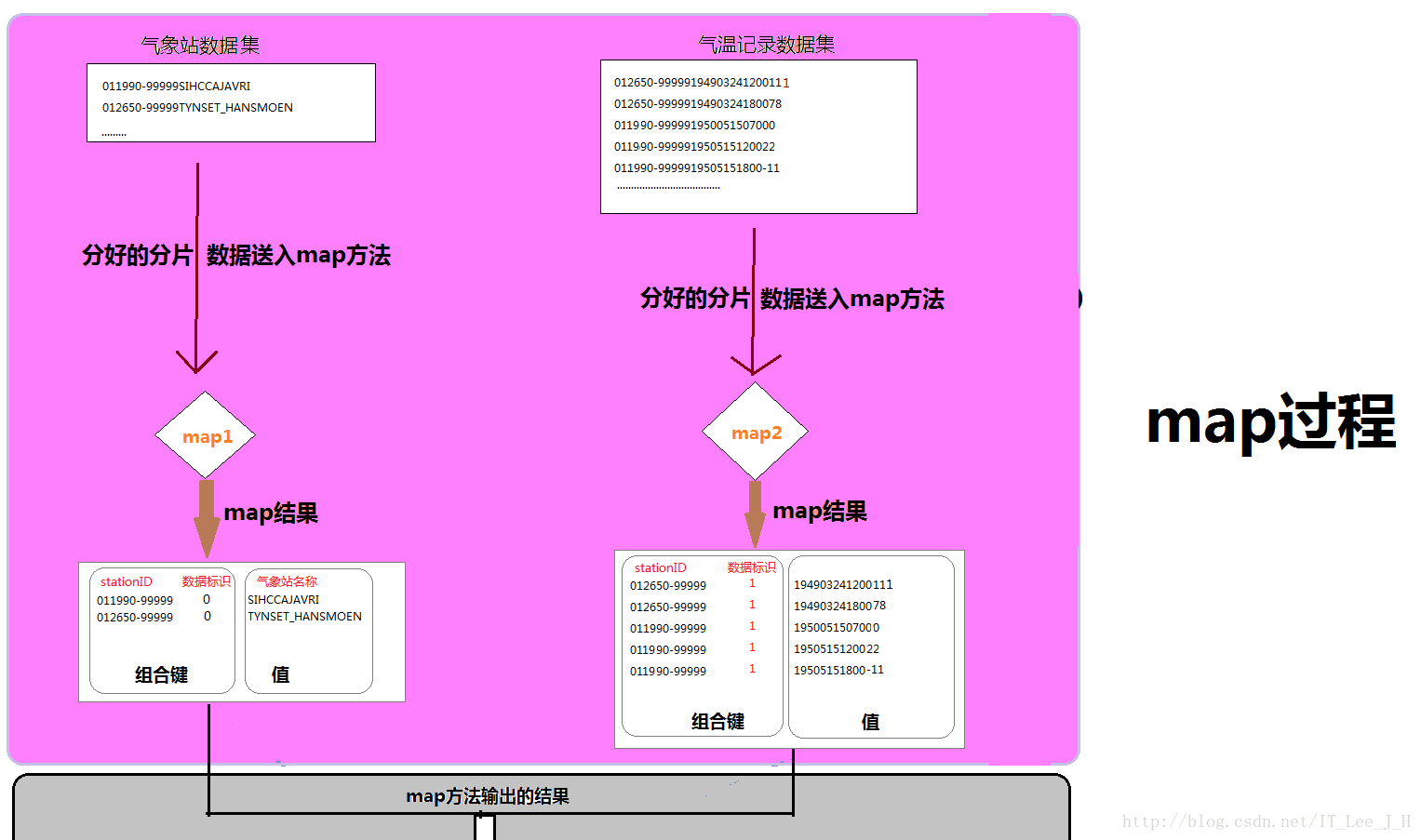
}6.1map的实现:
这里有两种格式的数据集,所以实现两个map
代码:
处理气象站的map ——JoinStationMapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class JoinStationMapper extends Mapper<LongWritable, Text, TextPair, Text> {
private NcdcStationMetadataParser parser = new NcdcStationMetadataParser();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, TextPair, Text>.Context context)
throws IOException, InterruptedException {
if(parser.parse(value)){
context.write(new TextPair(parse.getStationId(),0),new Text(parser.getStationName()));
}
}
}
处理气温记录的map ——JoinRecordMapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class JoinRecordMapper extends Mapper<LongWritable, Text, TextPair, Text> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, TextPair, Text>.Context context)
throws IOException, InterruptedException {
parser.parse(value);
context.write(new TextPair(parser.getStationId(),"1"),value);
}
}实现效果:
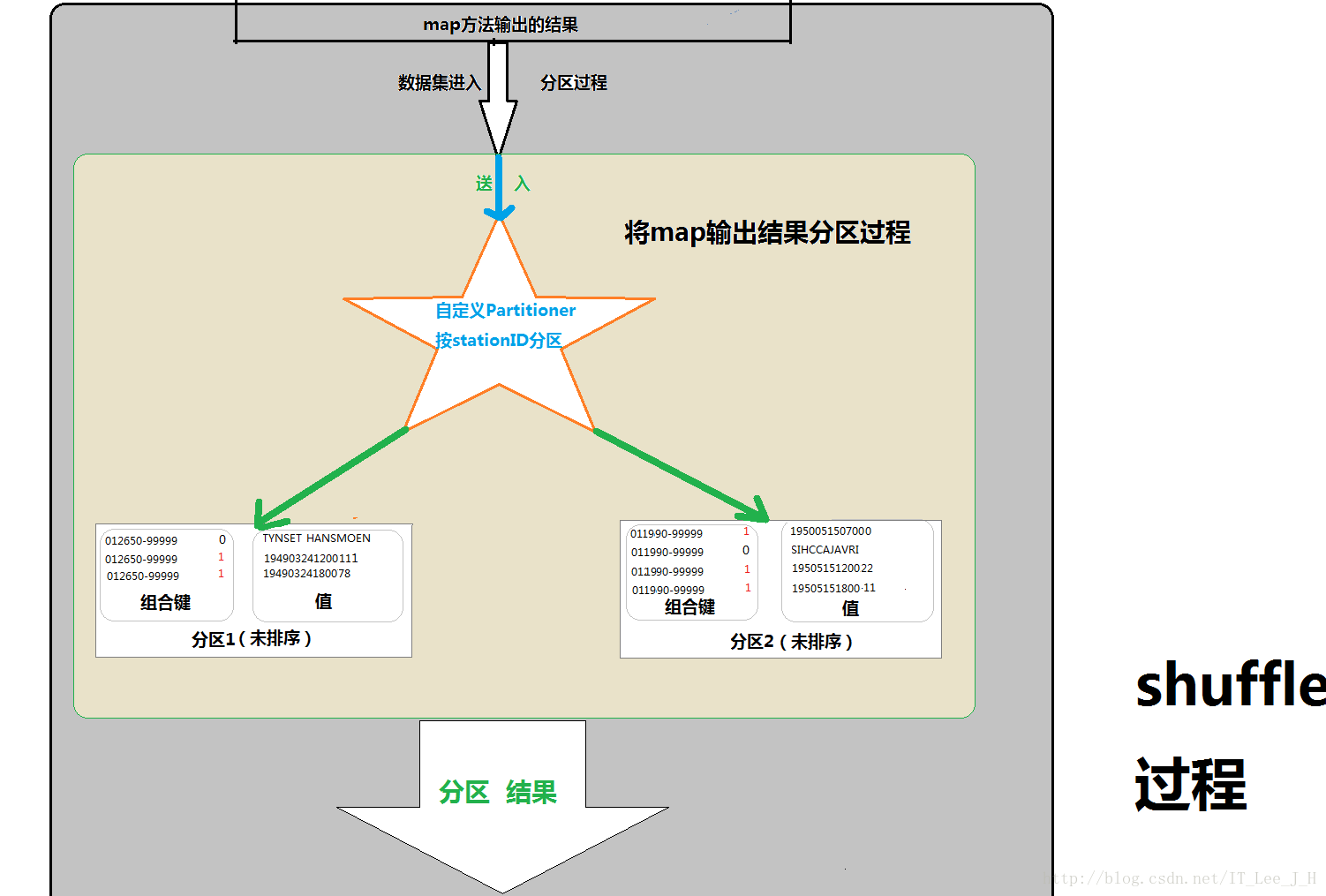
6.2分区partitioner的实现:
将两种map的数据结果按照其中组合键的第一个键(stationID)来进行hashpartitioner的效果
代码:
KeyPartitioner ——JoinRecordWithStationName类的静态内部类
public static class KeyPartitioner extends Partitioner<TextPair, Text>{
@Override
public int getPartition(TextPair key, Text value, int numPartitions) {
return (key.getFirst().hashCode() & Integer.MAX_VALUE) %numPartitions;
}
}实现效果:
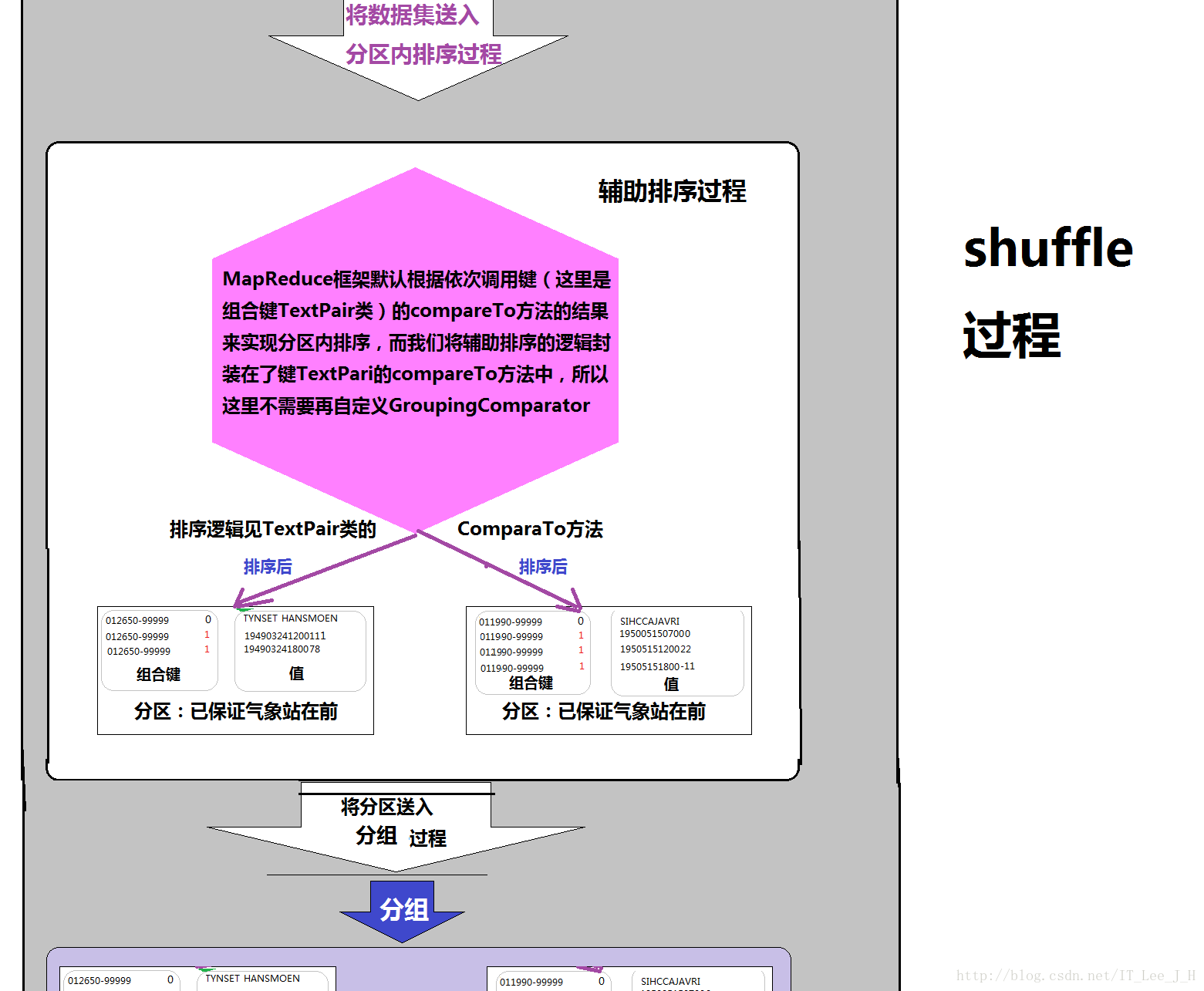
6.3分区排序keyComparator(辅助排序)的实现:
这里为了保证对于reduce来说,先获取(处理)气象站数据,再获取(处理)天气数据,借助默认的排序规则(升序)在stationID排序后的情况下,相同stationID的标识位(气象站的为0,天气数据为1),该步骤决定在不改变reduce的前提下最后输出中气象站位于天气信息的前还是后
注意:这里由于MapReduce的shuffle过程在设计时就会自动调用“键”的comparto()方法来按“键”排序,我们这里将传统意义上的键“扩展为”自定义的组合键类型,所以会自动调用Textpari类的comparto()方法来排序,这个比较大小的效果被我在准备阶段TextPari的comparTo()方法中就实现了,所以这里不需要再自己写一个辅助排序的过程就能实现我们要的辅助排序,这里也不再设置。—有点难理解,结合辅助排序的实现P259和自定义的组合键的comparTo方法实现逻辑来理解!!!!
实现效果:
6.4分组GroupComparator的实现:
将输入的内容格式混乱的数据,按照组合键的第一个键(stationID)来进行分组,保证reduce可以根据从每一个分组中直接遍历就能获取要写出的“元数据”(对于最终输出的数据来说的元数据)。
代码:
FirstComparator
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class FirstComparator extends WritableComparator {
protected FirstComparator(){
super(TextPair.class,true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
TextPair ip1 = (TextPair) w1;
TextPair ip2 = (TextPair) w2;
return ip1.compareTo(ip2);
}
}实现效果:
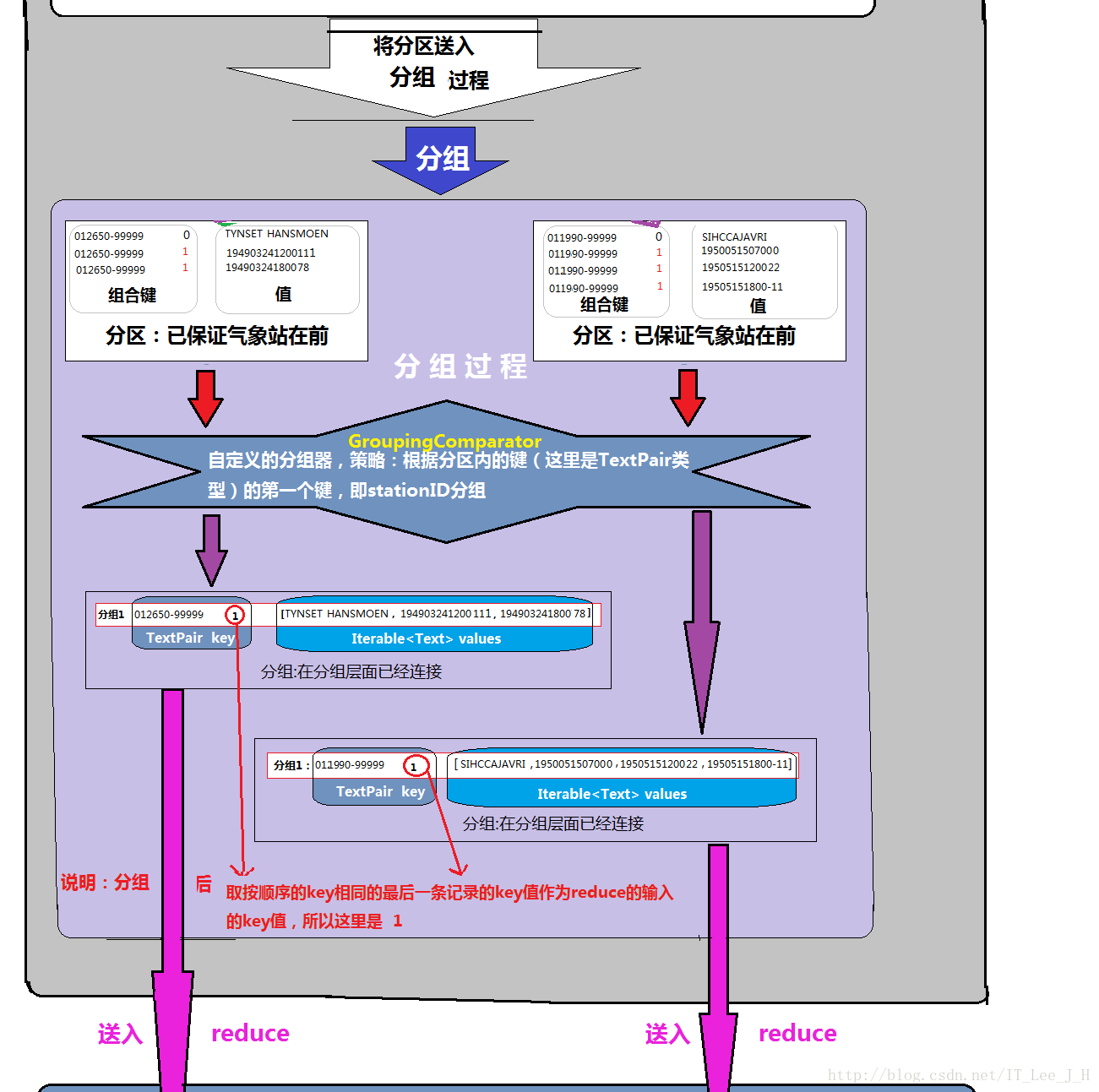
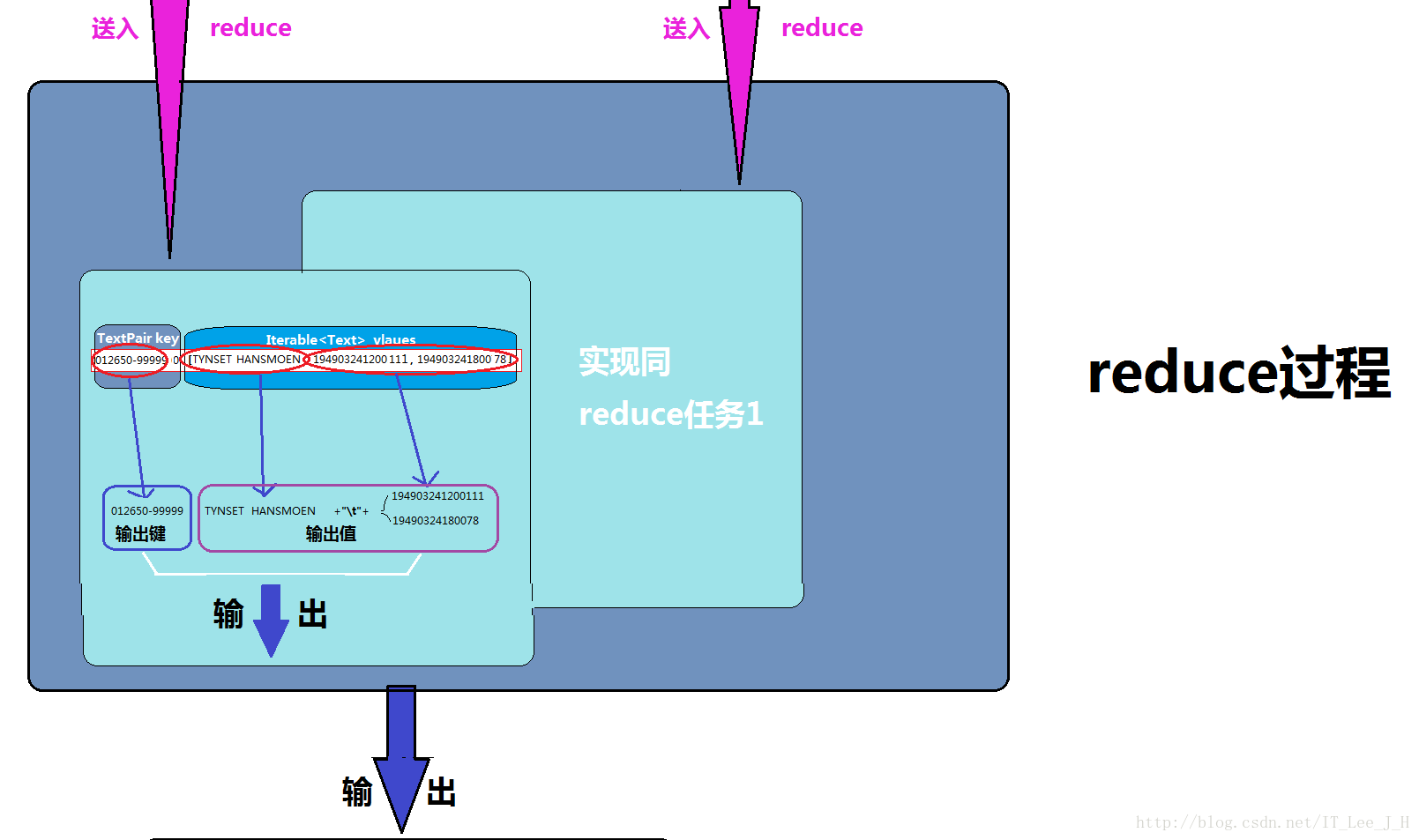
6.5reduce方法的实现:
将“分组格式”的连接后数据,直接写出。
代码:
JoinReducer 类
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class JoinReducer extends Reducer<TextPair, Text, Text, Text>{
@Override
protected void reduce(TextPair key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Iterator<Text> iter = values.iterator();
Text stationName = new Text(iter.next());
while(iter.hasNext()){
Text record = iter.next();
Text outValue = new Text(stationName.toString()+"\t"+record.toString());
context.write(key.getFirst(), outValue);
}
}
}实现效果:














 4212
4212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









