







Iterable:
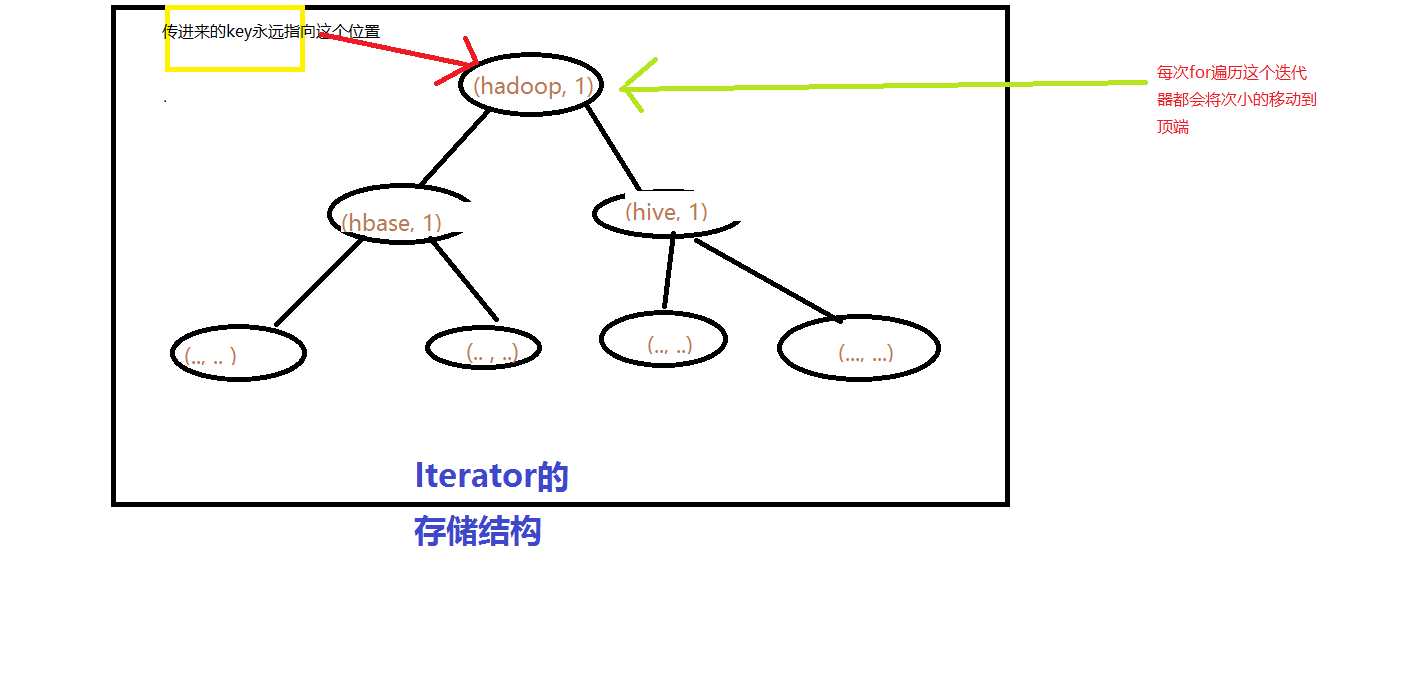
1.集合里边的每个数值在内存中是用完全二叉树存储的形式存储的(小顶堆)
2.小顶堆的顶端(根节点)存储着按排序后的最大或最小值(小顶堆的特性)
(到底是最大还是最小根据你的排序规则确定)
3.每次循环一次,小顶堆的堆顶数值都会改变,但是不变的是顶堆的数一定是最大或最小值(小顶堆的特性)
4.当第一次调用这个reduce(Text,Iterable,Context){。。。}方法时,传过来的Text(key引用)指向了(小顶堆那组的key值)
5.当循环发生时引用(key)不变但是key存储的key发生变化是因为小顶堆的特性决定的,它会调整这个结构顶堆的数一定是最大或最小值
job.setSortComparatorClass设置的key比较函数类对所有数据对排序。然后开始构造一个key对应的value迭代器。这时就要用到分组,使用jobjob.setGroupingComparatorClass设置的分组函数类。















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









