







spark上下文对象,是spark程序的主入口点,负责连接到spark cluster。
一旦有了上下文,就可以创建RDD,子集群上创建累加器和广播变量
每个jvm只能激活一个sparkcontext,创建新的时候必须停止前一个
sparkcontext需要传入sparkconf ,用来设置spark参数,参数是kv对
RDD:是不可变的,可分区的元素集合,可进行并行操作。该类包含了用于所有RDD之上的基本操作
在RDD内部,每个RDD有5个特征:
1有一个分区列表
2每个split都有一个计算函数
3存放是parent的依赖列表
4(可选)基于kv对的分区器
5(可选)首选的位置列表
val lines(就是RDD)=textFile()用来读取hdfs内容,或者本地文件 file:///home/ddd.txt lines.first lines.take(2)提取前两行
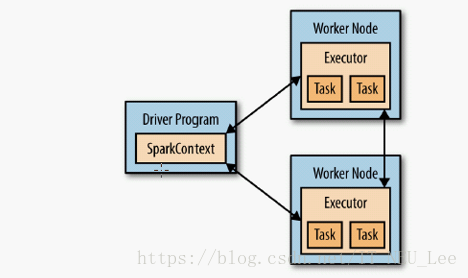
每个spark程序应由driver构成,由他启动各种并行操作。driver含有main函数和分布式数据集,并对他们应用
各种操作,如:spark-shell本身就是一个driver(包含main方法 )
Driver通过sparkContext访问spark 代表spark和集群的连接,运行程序时候,驱动程序需要管理一些叫做executor的节点
spark-shell 默认使用local模式运行spark程序,并没有用到spark集群,类似于hadoop的本地模式
sparkshell可以带参数 --master local[2] 在本地开启两个线程模拟spark集群
独立应用程序:standalone application
写好Scala文件后 先使用Scalac命令进行编译:scalac -cp /usr/apps/spark/lib/spark-assembly-2.2.1-hadoop-2.7.1.jar: `hadoop classpath`: . -d target wcApp.scala 然后用Scala命令运行
或者使用maven进行编译:mvn clean && mvn compile && mvn package 然后就会生成相应的jar包
每个RDD被切分成不同的分区,每个分区在不同的节点上计算
持久化:persist() 用来重用 不用重复计算结果 只用计算一次 如执行rdd.count
spark默认持久化对象到jvm heap中 没有串行化 或者串行化到磁盘或者离堆区中
创建RDD有两种方式:1 textFile读取文件 和 2 parallelize(1 to 100)
伪集合操作:
1.rdd1=tom tomas tomasLee rdd2 = tomas tomasLee jerry bob
2. rdd.distinct()去重
3. union 联合
4. intersection 交集
5.substract
笛卡尔积:
rdd1.cartesion(rdd2)
rdd.sample(false,0.8) (某个元素是否可以被采样多次,采样比)
Action:
rdd.reduce((x,y)=>x+y) 即x+y=>x 然后用新的x+下一个y (1,2,3,4,5)变成 1+2+3+4+5
fold() 有一个初始值 和reduce类似 如初始值10 则:10+1+3+4+5
聚合:aggregate(): https://blog.csdn.net/huanbia/article/details/51436822
collect()返回所有元素
countByValue() rdd中每个元素出现的次数
top(n)提取末尾的n个元素
takeOrdered()
mean() 平均值
操作key-value:
PairRDD (1,2)
reduceByKey() groupByKey() combinByKey() mapValues(x=>x+1)
flatMapValues(x=>{x to 5}) keys()取出key
rdd1.subtractByKey(rdd2) key 一样 就减去
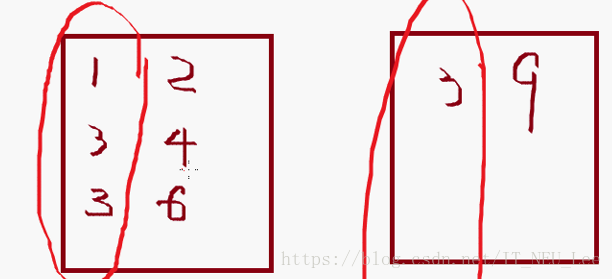
rdd1.join(rdd2)= a:(1,2),(3,4),(3,6) join (3,9) =array((3,(4,9)),(3,(6,9))) 如图:
rdd1.rightOuterJoin(rdd2)
rdd1.fileter{case(key,value)=>value<5} 找出value小于5的
aggregations:聚合
1.

2. rdd.countByValue() 等价于rdd.map(x=>(x,1)).reduceByKey((x,y)=>x+y)
3 combineByKey
调整并发程度
rdd.reduceByKey(f:op,numParitions:Int) (函数,并发程度)
检测rdd分区数
rdd.repartition(4) 用来重新制定分区数 rd.coalesce(4)也可以用来指定分区 数目
rdd.partitions.size
隐式常量

PairRDD可用的action:
countByKey collectAsMap() 转换成map键值对,并且去掉key重复的数据 lookup(key) 找到相同key的value值
data分区;(通信昂贵,需要最小化网络流量)在所有的kv RDD对上,可以进行分区,引发系统
对元素按照key进行分组 这样让同样key的分到同一个节点上去
rdd.partitionBy(new HashPartitioner(100)).persist() 传入hash分区器100个分区然后根据键进行分区
rdd.partitioner 获取分区器 rdd.isDefined 判断分区器是否定义 rdd.get()获得分区对象
分区有益的方法:cogroup() Join() groupByKey() reduceByKey() groupWith() loopup() combineByKey 这些操作都会产生分区
读取文件:textFile() wholeTextFiles()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









