







 本文深入介绍了Apache Commons Pipeline工作流框架,包括Pipeline的结构、Stage的使用和StageDriver的角色。Pipeline由可重用的Stages组成,数据在Stage间流动。StageDriver管理Stage的数据输入和通信。此外,文章还提到了使用Digester配置Pipeline的简单方法,以及编写自定义Stage的接口解析。
本文深入介绍了Apache Commons Pipeline工作流框架,包括Pipeline的结构、Stage的使用和StageDriver的角色。Pipeline由可重用的Stages组成,数据在Stage间流动。StageDriver管理Stage的数据输入和通信。此外,文章还提到了使用Digester配置Pipeline的简单方法,以及编写自定义Stage的接口解析。
本系列源于对commons-pipeline 使用的学习:
首先是:翻译官方文档
本文是针对使用 Apache Commons Pipeline工作流程框架的基础介绍,本文档目标读者为需要组装现有stages或编写自己的stages的开发人员。该项目提供了一个Java类库旨在提升使用和重用模块化的stage的易用性。
一、Pipeline结构:
- Stages:stages在Pipeline中代表来处理数据所需的逻辑单元。每一个stage代表一个高层次的处理概念:如查找文件,读取文件格式,从数据计算产品,或者将数据写入到数据库。使用工作流架构并且构建处理单元到Stages的主要优点是提升Stages在其他Pipeline的可重用性。
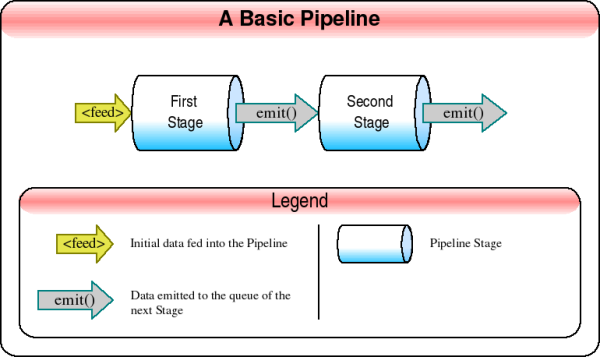
- Pipeline:一个Pipeline由stages构建而成,这些stages可以将数据传递给后续的stages。上图中箭头所标记的“EMIT”表明一个stage的数据输出被传递到下一个stage。从代码层面看,有一个 EMIT() 方法将数据发送到下一个stage。数据流开始于左侧,在那里有一个标为“FEED”的箭头。FEED通常通过一个配置文件开始一个Pipeline,这点在后面讨论。Stage自己不关心输入的数据是来自FEED或前一阶段的EMIT()。
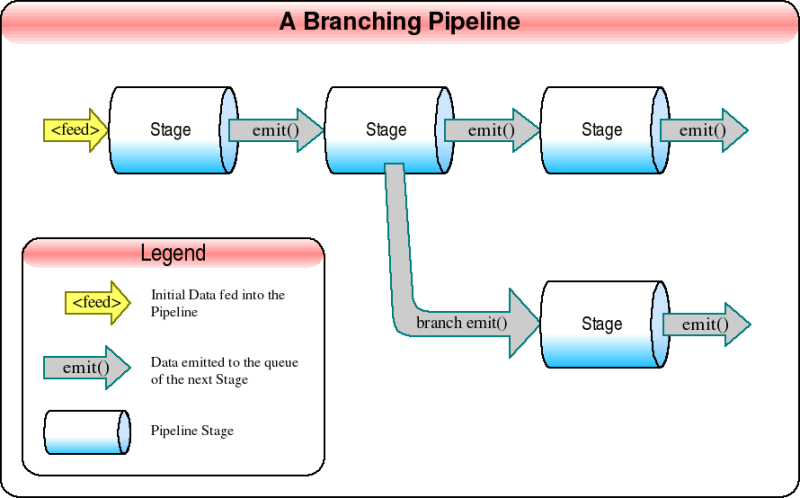
Pipeline也可发送相同或不同的数据到不同的分支(branch),使数据沿不同的处理路线流转。
- 通过Digester 或者 Spring 配置:有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









