



 本文通过几个实例深入探讨了C/C++语言中的未定义行为,包括变量的副作用、序点规则、不同C标准之间的差异等内容,帮助读者更好地理解和避免这类问题。
本文通过几个实例深入探讨了C/C++语言中的未定义行为,包括变量的副作用、序点规则、不同C标准之间的差异等内容,帮助读者更好地理解和避免这类问题。
译自Deep C (and C++) by Olve Maudal and Jon Jagger,本身半桶水不到,如果哪位网友发现有错,留言指出吧:)
好,接着深入理解C/C++之旅。我在翻译第一篇的时候,自己是学到不不少东西,因此打算将这整个ppt翻译完毕。
请看下面的代码片段:
#include <stdio.h> void foo(void) { int a; printf("%d\n", a); } void bar(void) { int a = 42; } int main(void) { bar(); foo(); }编译运行,期待输出什么呢?
$ cc foo.c && ./a.out 42你可以解释一下,为什么这样吗?
第一个候选者:嗯?也许编译器为了重用有一个变量名称池。比如说,在bar函数中,使用并且释放了变量a,当foo函数需要一个整型变量a的时候,它将得到和bar函数中的a的同一内存区域。如果你在bar函数中重新命名变量a,我不觉得你会得到42的输出。
你:恩。确定。。。
第二个候选者:不错,我喜欢。你是不是希望我解释一下关于执行堆栈或是活动帧(activation frames, 操作代码在内存中的存放形式,譬如在某些系统上,一个函数在内存中以这种形式存在:
ESP
形式参数
局部变量
EIP
)?
你:我想你已经证明了你理解这个问题的关键所在。但是,如果我们编译的时候,采用优化参数,或是使用别的编译器来编译,你觉得会发生什么?
候选者:如果编译优化措施参与进来,很多事情可能会发生,比如说,bar函数可能会被忽略,因为它没有产生任何作用。同时,如果foo函数会被inline,这样就没有函数调用了,那我也不感到奇怪。但是由于foo函数必须对编译器可见,所以foo函数的目标文件会被创建,以便其他的目标文件链接阶段需要链接foo函数。总之,如果我使用编译优化的话,应该会得到其他不同的值。
$ cc -O foo.c && ./a.out 1606415608候选者:垃圾值。
那么,请问,这段代码会输出什么?
#include <stdio.h> void foo(void) { int a = 41; a= a++; printf("%d\n", a); } int main(void) { foo(); }第一个候选者:我没这样写过代码。
你:不错,好习惯。
候选者:但是我猜测答案是42.
你:为什么?
候选者:因为没有别的可能了。
你:确实,在我的机器上运行,确实得到了42.
候选者:对吧,嘿嘿。
你:但是这段代码,事实上属于未定义。
候选者:对,我告诉过你,我没这样写过代码。
第二个候选者登场:a会得到一个未定义的值。
你:我没有得到任何的警告信息,并且我得到了42.
候选者:那么你需要提高你的警告级别。在经过赋值和自增以后,a的值确实未定义,因为你违反了C/C++语言的根本原则中的一条,这条规则主要针对执行顺序(sequencing)的。C/C++规定,在一个序列操作中,对每一个变量,你仅仅可以更新一次。这里,a = a++;更新了两次,这样操作会导致a是一个未定义的值。
你:你的意思是,我会得到一个任意值?但是我确实得到了42.
候选者:确实,a可以是42,41,43,0,1099,或是任意值。你的机器得到42,我一点都不感到奇怪,这里还可以得到什么?或是编译前选择42作为一个未定义的值:)呵呵:)
那么,下面这段代码呢?
#include <stdio.h> int b(void) { puts("3"); return 3; } int c(void) { puts("4"); return 4; } int main(void) { int a = b() + c(); printf("%d\n", a); }第一个候选者:简单,会依次打印3,4,7.
你:确实。但是也有可能是4,3,7.
候选者:啊?运算次序也是未定义?
你:准确的说,这不是未定义,而是未指定。
候选者:不管怎样,讨厌的编译器。我觉得他应该给我们警告信息。
你心里默念:警告什么?
第二个候选者:在C/C++中,运算次序是未指定的,对于具体的平台,由于优化的需要,编译器可以决定运算顺序,这又和执行顺序有关。
这段代码是符合C标准的。这段代码或是输出3,4,7或是输出4,3,7,这个取决于编译器。
你心里默念:要是我的大部分同事都像你这样理解他们所使用的语言,生活会多么美好:)
这个时候,我们会觉得第二个候选者对于C语言的理解,明显深刻于第一个候选者。如果你回答以上问题,你停留在什么阶段?:)
那么,试着看看第二个候选者的潜能?看看他到底有多了解C/C++
可以考察一下相关的知识:
声明和定义;
调用约定和活动帧;
序点;
内存模型;
优化;
不同C标准之间的区别;
这里,我们先分享序点以及不同C标准之间的区别相关的知识。
考虑以下这段代码,将会得到什么输出?
1. int a = 41; a++; printf("%d\n", a); 答案:42 2. int a = 41; a++ & printf("%d\n", a); 答案:未定义 3. int a = 41; a++ && printf("%d\n", a); 答案:42 4. int a = 41; if (a++ < 42) printf("%d\n",a); 答案:42 5. int a = 41; a = a++; printf("%d\n", a); 答案:未定义到底什么时候,C/C++语言会有副作用?
序点:
什么是序点?
简而言之,序点就是这么一个位置,在它之前所有的副作用已经发生,在它之后的所有副作用仍未开始,而两个序点之间所有的表达式或者代码执行的顺序是未定义的!
序点规则1:
在前一个序点和后一个序点之前,也就是两个序点之间,一个值最多只能被写一次;
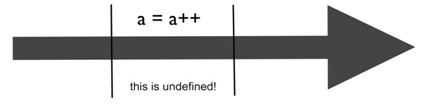
这里,在两个序点之间,a被写了两次,因此,这种行为属于未定义。
序点规则2:
进一步说,先前的值应该是只读的,以便决定要存储什么值。
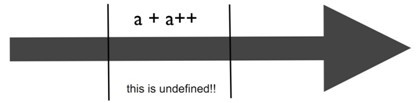
很多开发者会觉得C语言有很多序点,事实上,C语言的序点非常少。这会给编译器更大的优化空间。
接下来看看,各种C标准之间的差别:

现在让我们回到开始那两位候选者。
下面这段代码,会输出什么?
#include <stdio.h> struct X { int a; char b; int c; }; int main(void) { printf("%d\n", sizeof(int)); printf("%d\n", sizeof(char)); printf("%d\n", sizeof(struct X)); }第一个候选者:它将打印出4,1,12.
你:确实,在我的机器上得到了这个结果。
候选者:当然。因为sizeof返回字节数,在32位机器上,C语言的int类型是32位,或是4个字节。char类型是一个字节长度。在struct中,本例会以4字节来对齐。
你:好。
你心里默念:doyouwantanothericecream?(不知道有什么特别情绪)
第二个候选者:恩。首先,先完善一下代码。sizeof的返回值类型是site_t,并不总是与int类型一样。因此,printf中的输出格式%d,不是一个很好的说明符。
你:好。那么,应该使用什么格式说明符?
候选者:这有点复杂。site_t是一个无符号整型数,在32位机器上,它通常是一个无符号的int类型的数,但是在64位机器上,它通常是一个无符号的long类型的数。然而,在C99中,针对site_t类型,指定了一个新的说明符,所以,%sz会是一个不多的选择。
你:好。那我们先完善这个说明符的bug。你接着回答这个问题吧。
#include <stdio.h> struct X { int a; char b; int c; }; int main(void) { printf("%zu\n", sizeof(int)); printf("%zu\n", sizeof(char)); printf("%zu\n", sizeof(struct X)); }候选者:这取决与平台,以及编译时的选项。唯一可以确定的是,sizeof(char)是1.你要假设在64位机器上运行吗?
你:是的。我有一台64位的机器,运行在32位兼容模式下。
候选者:那么由于字节对齐的原因,我觉得答案应该是4,1,12.当然,这也取决于你的编译选项参数,它可能是4,1,9.如果你在使用gcc编译的时候,加上-fpack-struct,来明确要求编译器压缩struct的话。
你:在我的机器上确实得到了4,1,12。为什么是12呢?
候选者:工作在字节不对齐的情况下,代价非常昂贵。因此编译器会优化数据的存放,使得每一个数据域都以字边界开始存放。struct的存放也会考虑字节对齐的情况。
你:为什么工作在字节不对齐的情况下,代价会很昂贵?
候选者:大多数处理器的指令集都在从内存到cpu拷贝一个字长的数据方面做了优化。如果你需要改变一个横跨字边界的值,你需要读取两个字,屏蔽掉其他值,然后改变再写回。可能慢了10不止。记住,C语言很注意运行速度。
你:如果我得struct上加一个char d,会怎么样?
候选者:如果你把char d加在struct的后面,我预计sizeof(struct X)会是16.因为,如果你得到一个长度为13字节的结构体,貌似不是一个很有效的长度。但是,如果你把char d加在char b的后面,那么12会是一个更为合理的答案。
你:为什么编译器不重排结构体中的数据顺序,以便更好的优化内存使用和运行速度?
候选者:确实有一些语言这样做了,但是C/C++没有这样做。
你:如果我在结构体的后面加上char *d,会怎么样?
候选者:你刚才说你的运行时环境是64位,因此一个指针的长度的8个字节。也许struct的长度是20?但是另一种可能是,64位的指针需要在在效率上对齐,因此,代码可能会输出4,1,24?
你:不错。我不关心在我的机器上会得到什么结果,但是我喜欢你的观点以及洞察力J
(未完待续)
静候

















 7609
7609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









