





一、Hash Table和Search Tree
实现dictionary的方法主要有哈希表和搜索树(二叉树、B树、AVL树);
实现哈希表的dictionary的优点:
(1)查询效率O(1);
缺点:
(1)哈希冲突。
(2)不支持模糊查询。
(3)哈希函数需要不断变化以适应需求。
实现搜索树的dictionary的优点:
(1)支持模糊查询。
缺点:
(1)查询效率相对较慢。
(2)树要保持平衡。
二、单个通配符查询
1.尾通配符查询
比如abc*,即通配符出现在尾部的查询就是尾通配符查询,这种查询使用搜索树可以完成,方法就是以a,b,c的顺序遍历树。如下图所示:

如果要查询ab*,则
(1)比较根节点:因为a在a-m中,所以往左走。
(2)因为ab在a-hu之间,因此往左走。
(3)剩下的子节点就是满足要求的结果,遍历并取得他们的posting即可。
2.头通配符查询
如果要进行头通配符查询,则需要引入反向B tree的概念。反向B tree是把B tree查询的顺序反过来。比如要查询*cba,则查询顺序为a,b,c,举例:

查询*ba的步骤:
(1)比较根节点,因为a在a-m之间,则往左走。
(2)因为ba在aa-uh之间,因此往左走。
因此下面的子节点就是满足条件的结果。
3.一般通配符查询
比如abc*cba,只需要分解成abc*和*cba,并分别运用1,2的知识即可。但要注意查询出的结果必须在abc*cba中过滤一遍。因为比如abcba满足abc*和*cba,但是却不满足abc*cba;
三、专用于通配符查询的索引结构
1.permuterm index

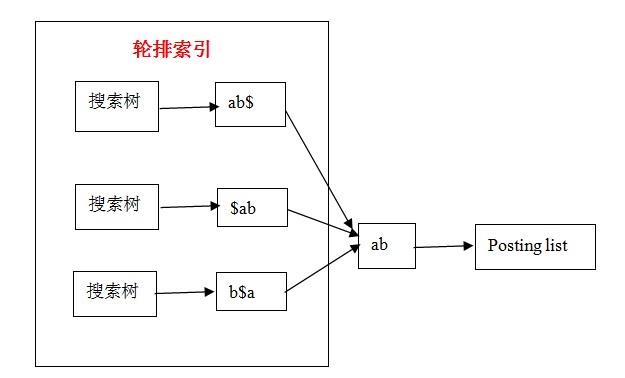
方法:$表示一个词的末尾(正则),即如果ab,则表示成ab$,并进行轮排,形成ab$,$ab,b$a,并指向ab;
在处理单个通配符查询时,如果要查*b,则先添上$,然后旋转,使得*在词的尾端,即b$*,并在搜索树中查找。发现b$a满足要求,则ab满足要求。
在处理多个通配符查询时,如果要查询a*b*,则先添加$即a*b*$,然后旋转为$a*b*,先查询$a*,取得的结果再通过a*b*过滤即可。
缺点:词典会变得很大。
2.K-GRAM index
K-GRAM的定义:k个连续的字母的组合,在第二十章中会讲到k-shingle,意思是k个连续单词的组合。
比如:hello的3-gram是:hel,ell,llo;

索引结构:
k-gram index的dictionary是所有词的k-gram的集合。
k-gram index的posting是匹配k-gram的单词序列。
索引规则:
在建索引之前必须在单词首尾添加$;再进行k-gram indexing;
查询方法:
举例:查找com*;利用3-gram 索引
(0)添加$,即$com*$; 如果是2-gram,则是$c , co , om
(1)先通过3-gram index进行查找匹配的单词;
(2)因为3-gram index查找出的结果并不精确(比如coordcom,匹配$co,com,却不能匹配$com*),因此需要在$com*进行过滤,才能得出结果。
总结:k-gram索引的速度非常慢;因为需要先对k-gram索引取得单词(原本的单层索引变成了两层索引),再进行一次过滤,才能进入普通的倒排索引中查找docID;
而轮排索引不需要后过滤,但是空间消耗很大;
四、拼音校验方法
主要原则:先找邻近度大的词,如果邻近度相同,则找常用词;
1.编辑距离
通过动态规划的方法,把两个单词看成二维矩阵,进行计算。


比如PARIS 和 ALICE

注意:编辑距离有个缺点,就是如果要让查询和每个term计算编辑距离,则效率太差,因为在倒排索引的dictionary中有几千万个term;
2.利用k-gram计算Jaccard系数
Jaccard系数:给定集合A和B,J=(AB)/(A+B-AB);
假设A和B是两个单词,长度为m和n,因此A和B分别有m-1个和n-1个k-gram;
给定一个查询Q,计算出Q所对应的k-gram后,即可对k-gram索引遍历,对每个单词和Q计算Jaccard系数,AB可以理解为有多少个k-gram重叠,而A+B-AB可以理解为合并后一共有多少k-gram(通过A和B的k-gram长度和 减去AB的k-gram overlap的数量),并取得Jaccard系数高出阈值的单词。
总结:可以先进行k-gram索引,然后再进行编辑距离的计算。
当然以上只是适用于单独单词的拼写错误,如果类似于I are happy.这种查询,就检测不出错误,因为单独的单词都是对的。
检测方法:当进行查询后返回的结果很少,则对查询词组有所怀疑,则会对每个单词进行替换,使得找出返回结果多的词组。
3.语音校验
通过把发音类似的单词放在同一个组(通过语音哈希函数),称为soundex算法。















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









