





对于Java程序员,在选择数据存储的时候,可能会经常遇到这样的疑惑,究竟该使用JCR引擎,还是直接使用关系型数据库?
有一篇老文章对此作过详尽到位的解释,
https://dev.day.com/content/ddc/blog/2009/01/jcrrdbmsreport/_jcr_content/images/jcrrdbmsreport/jcr_rdbms_report_chapuis.pdf
文中主要提到下面的一些观点:
1、数据模型分为:分层模型(树)、网络模型、关系模型(注:还有现在的key/value键值对),
时至今日,分层/网络模型应用场合逐步萎缩,但仍有价值,如HTML页面DOM结构就是分层模型的典型应用
2、选择数据模型取决于业务的复杂度,是否能提前定义,是否能适应变化
3、数据模型会影响数据处理各个角色的职责(DBA,程序员,用户),对于结构驱动内容的模型,DBA负责结构定义,
对于内容驱动结构的模型,DBA只负责数据完整性、安全、可用、可恢复
4、对于一个house而言,结构是可以清晰定义的,那么关系型数据模型比较适用,
而如果是一个城市,由于一个城市的生态环境很多时候是自然选择、淘汰的过程,其存在很大的变数,所以使用具有动态定义内容结构的模型比较合适
这有点类似于静态语言和动态语言之间的差别,静态语言必须提前定义好类的属性行为,而动态语言ruby/python/php,则可以在运行时动态构造、调用新的属性行为
5、每个模型都有其局限,尽管关系型SQL很强大,但在需要查询整个树状数据时,则需要使用其它模型,另外关系型数据对于版本控制以及访问控制的支持也不好
6、JCR适合数据浏览(Navigation)和版本化信息查询(Versioning),而RDBMS适合复杂联合查询
7、性能不是主要的考虑方面,JCR获取关联数据的复杂度由于其实现是指针浏览,所以为O(1),即和数据量n无关,而关系型数据由于需要从表中匹配某个键值,
所以,理论上如果表中数据为n个,那么复杂度为O(n),但通过建立合适的索引,如b-tree,复杂度可以降低到O(log(n)),还可以再简化索引比较操作,使用合适的hash,达到O(1),(注:由于要建立索引,mysql的数据建立较慢,随机查询则和H2/CRX无多大差别)
下面是比较汇总图:
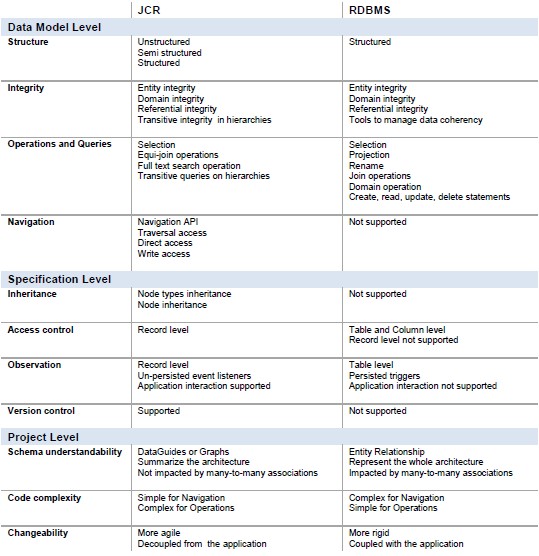
参考链接:
http://stackoverflow.com/questions/1226325/when-should-you-use-jcr-and-when-should-you-use-jpa-rdbms
by iefreer















 5631
5631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









