





一段错误的代码
首先看一段错误的代码:#!/bin/bash
SLICE=100;
slppid=1;
pidfile=/var/run/vpnrulematch.pid
# 停止之前的sleep
kill_prev() {
pid=$1;
/bin/kill -0 $pid;exist=$?
ppid=$(/bin/cat /proc/$pid/status|/usr/bin/awk -F ' ' '/PPid/{print $2}');
if [ "$exist" == 0 ] && [ "$ppid" == $$ ]; then
/bin/kill $pid;
fi
}
echo $$ >$pidfile
# 循环处理睡眠
while true; do
NOSTATE=0;
/bin/sleep $SLICE &
slppid=$!;
wait
...
done以上代码的本意是在接收到信号的时候,停止先前的sleep,重新开始新的sleep。看看那个繁杂的kill_prev操作,之所以繁杂是因为做了“防误杀”处理,只有在该进程id指示的进程存在并且是sleep,而且还是本脚本的子进程的时候才进行kill操作。初看起来这没有任何问题,很严密,但是注意那个if判断和kill操作之间的间隙,如果在那段时间sleep完成了,并且系统中有一个新的进程恰好在那时开始运行,并且占据了刚才sleep进程的PID,该进程会马上被误杀!即使Linux的PID分配策略是尽可能的往后递增以防止这种现象,然而这还是受制于允许的PID的总数量,如果PID最大只能是10,那么这就会很容易发生!
那该怎么办?答案就是将该脚本以及它的子进程等相关的PID和系统中其它进程的PID隔离开来,但是Linux可以做到吗?可以做到,使用namespace即可。
关于命名空间
所谓的命名空间其实就是一个编址空间(废话,等于没说!!),一样东西要想被识别必须要被编址,比如快递员按照你的地址找到你的家,这个家庭地址就是一个编址,所有的已有的以及还未使用的潜在家庭地址组成了一个命名空间。一个命名空间一般只服务于一种动作,不同的命名空间之间是不能交互的。一样东西可以在不同的命名空间被命名编址,比如盖乌斯.尤利乌斯.凯撒和Gaius Julius Caesar指的是同一个人,然而却是处在不同命名空间中的,你在意大利找到一个人,对他说盖乌斯.尤利乌斯.凯撒,他可能就不知道你在说什么,这就是说,你不能垮命名空间进行寻址;如果在中国,生了一个小孩,给他取名字Gaius Julius Caesar,那么它和盖乌斯.尤利乌斯.凯撒并没有任何关联,这就是说,不同命名空间的相同名字之间是没有任何关系的;但是如果你精通古罗马历史,并且同时精通中文和意大利语,那么你马上就能将盖乌斯.尤利乌斯.凯撒和Gaius Julius Caesar联系起来,并且可能会有意给自己儿子取名字为自己的偶像Gaius Julius Caesar,这就是说,在更高的层次上,可以做到跨命名空间的交互。
Linux的PID namespace结构以及实现
Linux的2.6内核引入了命名空间namespace,后来将PID也用ns实现了,这也许是为了更好的支持虚拟化吧。本质上一个进程可以属于不同的命名空间。Linux将PID namespace组织成了一个tree,子命名空间对父命名空间是可见的,反过来,父命名空间对子命名空间则不可见,Linux对PID namespace的实现如下图所示: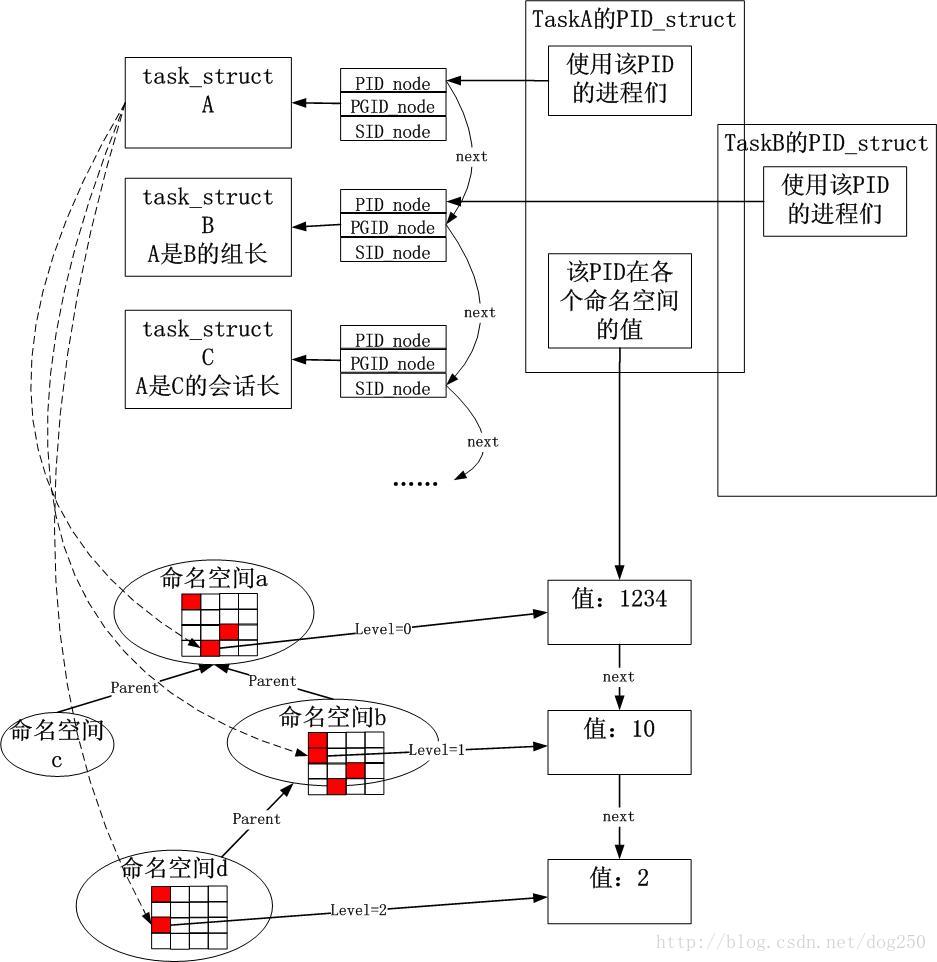
通过引入一个pid结构体和task_struct进行关联,所有的关于PID命名空间的实现全部在这个pid结构体中:
struct pid
{
atomic_t count;
unsigned int level;
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX];
struct rcu_head rcu;
struct upid numbers[1];
};最下面的upid数组就是表示该pid在多命名空间中的值的:
struct upid {
/* Try to keep pid_chain in the same cacheline as nr for find_vpid */
int nr;
struct pid_namespace *ns;
struct hlist_node pid_chain;
};以上的upid结构体包含了pid值本身以及一个namespace的引用,一个pid_namespace中包容了很多和进程控制相关的东西,比如独立的pid分配位图,1号进程引用,proc mount点等等,另外还有和自身组织相关的字段,比如parent指向父命名空间,level指示当前的命名空间深度。这里要说明的就是1号进程的作用,在UNIX中,1号进程非常重要,由于进入新的命名空间后,和父命名空间的1号进程将断绝来往,因此在新的命名空间需要一个新的1号进程,在Linux实现中,使用CLONE_NEWPID clone出来的进程担当1号进程的角色,实际上,它的进程号真的就是1。
可以看一下alloc_pid的实现片断:
for (i = ns->level; i >= 0; i--) {
//tmp为当前遍历到的namespace,使用其独立的位图分配pid值
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}可以看到,一直上溯到默认的pid namespace,每一个经过的pid namespace都会为该新进程分配一个pid值,因此处在独立的pid namespace中的进程会有多个pid值,每一个命名空间一个。
一个实验
终于到了小试牛刀的时候了,首先执行一下下面代码编译的程序:#include <sched.h>
#include <unistd.h>
#include <sys/types.h>
#include <signal.h>
#include <errno.h>
#include <sys/wait.h>
char arg[16] = {0};
int new_ns(void *nul)
{
execl("/bin/bash", "/bin/bash", NULL);
}
int main(int argc, char **argv)
{
int res;
pid_t newid;
long ssize = sysconf(_SC_PAGESIZE);
void *stack = alloca(ssize) + ssize;
pid = clone(new_ns, stack,CLONE_NEWPID |CLONE_NEWNS, NULL);
//由于在属于该进程的内存空间分配的statck上运行,需要等待其结束
waitpid(newid, &res, 0);
}代码超级简单,执行后就会进入新的pid命名空间了吗?试试吧!执行后,ps -e看了一下,发现还是原来的,1号进程依然是init!怎么回事啊?难道有什么不对吗?原来是procfs导致的。我们知道ps命令是解析procfs的内容得到结果的,而procfs根目录的进程pid目录是基于mount当时的pid namespace的,这个在procfs的get_sb回调中体现的。因此只需要重新mount一下proc即可:
mount -t proc proc /proc
不过也可以将以下的代码写入new_ns函数中去:
mount("proc", "/proc", "proc", 0, "");正确的代码
起初的那段错误的代码应该怎么改呢?Linux系统有个命令叫做unshare,然而好像不能unshare pid,于是不得不自己写一个,实际上也不用这么麻烦,直接将上面的代码改一下即可,在new_ns中不再exec bash,而是参数化,执行时,将最初那个脚本作为参数传入即可。然而还有一个问题,那就是既然已经到了新的pid namespace,以下的代码就不对了:echo $$ >$pidfile因为此时脚本的pid明显是1,而不在调用者的pid namespace内,写这个逻辑明显就是想让其它进程找到该脚本进程后给它发信号的,这样pid到了新的namespace,echo $$ >$pidfile写入的pid对于其它进程明显就不对了,然而到了新的namespace之后,脚本将无法自己知道它在父namespace中的pid是多少,因此其它进程只能通过ps -ef的方式去寻找它,因为虽然脚本到了新的namespace,然而它在父namespace中的pid还是有的。
我不知道为何Linux没有提供诸如get_all_pid的系统调用,是因为这样不安全,违背了namespace互相隔离这种初衷?















 1123
1123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









