





Linux内核实现了数据包的队列机制,配合多种不同的排队策略,可以实现完美的流量控制和流量整形(以下统称流控)。流控可以在两个地方实现,分别为egress和ingress,egress是在数据包发出前的动作触发点,而ingress是在数据包接收后的动作触发点。Linux的流控在这两个位置实现的并不对称,即Linux并没有在ingress这个位置实现队列机制。那么在ingress上就几乎不能实现流控了。
虽然使用iptables也能模拟流控,但是如果你就是想用真正的队列实现流控的话,还真要想想办法。也许,就像电子邮件的核心思想一样,你总是能完美控制发送,却对接收毫无控制力,如果吸收了这个思想,就可以理解ingress队列流控的难度了,然而,仅仅是也许而已。
Linux在ingress位置使用非队列机制实现了一个简单的流控。姑且不谈非队列机制相比队列机制的弊端,仅就ingress的位置就能说明我们对它的控制力几乎为0。ingress处在数据进入IP层之前,此处不能挂接任何IP层的钩子,Netfilter的PREROUTING也在此之后,因此在这个位置,你无法自定义任何钩子,甚至连IPMARK也看不到,更别提关联socket了,因此你就很难去做排队策略,你几乎只能看到IP地址和端口信息。
一个现实的ingress流控的需求就是针对本地服务的客户端数据上传控制,比如上传大文件到服务器。一方面可以在底层释放CPU压力,提前丢掉CPU处理能力以外的数据,另一方面,可以让用户态服务的IO更加平滑或者更加不平滑,取决于策略。
2.使用一个非本机的地址,然后修改虚拟网卡的xmit函数,内部使其DNAT成本机地址,这就绕开了local表的问题。
不考虑细节,仅就上述原理图讨论的话,你可以在常规路径的PREROUTING中做很多事情,比如使用socket match关联socket,也可以使用IPMARK。
下面,我们就可以按照上述图示,实际实现一个能用的。首先先要实现一个虚拟网卡。仿照loopback接口做一个用于流控的虚拟接口,首先创建一个用于ingress流控的虚拟网卡设备
接着构建其xmit函数
方案1:如果不想设置arp相关的东西,就要修改内核了。在此我引入了一个路由标志,RT_F_INGRESS_TC,凡是有该标志的路由,全部将其导入到构建的虚拟网卡中,为了策略化,我并没有在代码中这么写,而是改变了RT_F_INGRESS_TC路由的查找顺序,优先查找策略路由表,然后再查找local表,这样就可以用策略路由将数据包导入到虚拟网卡了。
方案2:构建一个Netfilter HOOK,在其target中将希望流控的数据NF_QUEUE到虚拟网卡,即在queue的handler中设置skb->dev为虚拟网卡,调用dev_queue_xmit(skb)即可,而该虚拟网卡则不再符合上面的图示,新的原理图比较简单,只需要在虚拟网卡的hard_xmit中reinject数据包即可。(事实上,后来我才知道,原来IMQ就是这么实现的,幸亏没有动手去做无用功)
方案3:这是个快速测试方案,也就是我最原始的想法,即将目标IP地址从local表删除,然后手动arping,我的测试也是基于这个方案,效果不错。
不管上面的方案如何变化,终究都是一个效果,那就是既然网卡的ingress不能流控,那就在egress上做,而又不能使用物理网卡,虚拟网卡恰好可以自定义其实现,可以满足任意需求。我们可以看到,虚拟网卡是多么的功能强大,tun,lo,nvi,tc...所有这一切,精妙之处全在各自不同的xmit函数。
1.不再需要INPUT这个HOOK点;
2.不再需要FORWARD这个HOOK点;
3.不再需要OUTPUT这个HOOK点,和第1点,第2点一起让Netfilter的整体架构也完全脱离了马鞍面造型;由此,本机发出的数据在DNAT后再也不用reroute了,其实,本来NAT模块中处理路由就很别扭...
4.策略路由可以更加策略化,因为即使目标地址是local表的路由,也可以将其热direct到别的策略表中。
就着以上第3点再做一下引申,我们可以很容易实现N多种虚拟网卡设备,在其中实现几乎任意的功能,比如这个ingress的流控,就可以很容易实现,不需要改内核和做复杂的配置,只要写一个虚拟网卡,配置几条策略路由即可。如此重新实现的协议栈处理逻辑可能某种程度上违背了协议栈分层设计的原则,但是确实能带来很多的好处,当然,这些好处是有代价的。值得注意的是,少了3个HOOK点是一个比较重要的问题,一直以来,虽然OUTPUT在路由后挂载,可是它实际上应该是路由前的处理,INPUT难道不是路由后吗?为何要把POSTROUTING又区分为INPUT和FORWARD,另外FORWARD其实也是路由后的一种...真正合理的是,INPUT和FORWARD应该是挂载在POSTROUTING上的subHOOK Point,可以将它们实现成一个HOOK Operation,对于OUTPUT,直接去除!HOOK点并不区分具体的逻辑,也不应该区分,这种逻辑应该让HOOK Operation来区分。
IMQ补丁,其核心侧重在以下4点:
1.命名。IMQ中的Intermediate,我觉得非常好,明确指出使用一个中间层来适配igress的流控;
2.实现一个虚拟网卡设备。即所谓的Intermediate设备;
3.NF_QUEUE的使用。使用Netfilter的NF_QUEUE机制将需要流控的数据包直接导入虚拟设备而不是通过策略路由间接将数据引入虚拟设备。
4.扩充了skb_buff数据结构,引入和IMQ相关的管理字段。个人认为这是它的不足,我并不倾向于修改核心代码。然而在我自己的虚拟设备实现中,由于ip_local_deliver函数并没有被核心导出(EXPORT),导致我不得不使用/proc/kallsym来查找它的位置,这么做确实并不标准,我不得不修改了核心,虽然只是添加了一行代码:
EXPORT_SYMBOL(ip_local_deliver);
但是还是觉得不爽!
IMQ的总图如下:
虽然使用iptables也能模拟流控,但是如果你就是想用真正的队列实现流控的话,还真要想想办法。也许,就像电子邮件的核心思想一样,你总是能完美控制发送,却对接收毫无控制力,如果吸收了这个思想,就可以理解ingress队列流控的难度了,然而,仅仅是也许而已。
Linux在ingress位置使用非队列机制实现了一个简单的流控。姑且不谈非队列机制相比队列机制的弊端,仅就ingress的位置就能说明我们对它的控制力几乎为0。ingress处在数据进入IP层之前,此处不能挂接任何IP层的钩子,Netfilter的PREROUTING也在此之后,因此在这个位置,你无法自定义任何钩子,甚至连IPMARK也看不到,更别提关联socket了,因此你就很难去做排队策略,你几乎只能看到IP地址和端口信息。
一个现实的ingress流控的需求就是针对本地服务的客户端数据上传控制,比如上传大文件到服务器。一方面可以在底层释放CPU压力,提前丢掉CPU处理能力以外的数据,另一方面,可以让用户态服务的IO更加平滑或者更加不平滑,取决于策略。
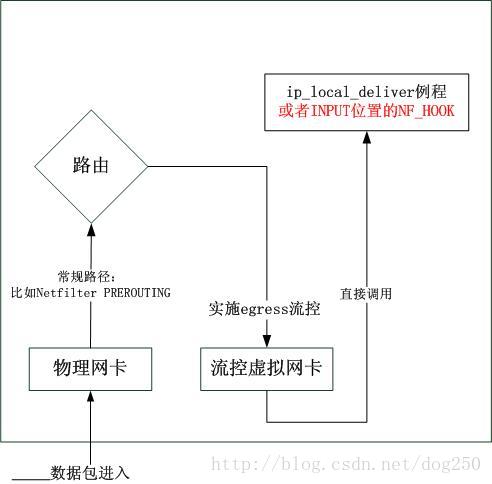
既然有需求,就要想法子满足需求。目前我们知道的是,只能在egress做流控,但是又不能让数据真的outgoing,另外,我们需要可以做很多策略,这些策略远不是仅由IP,协议,端口这5元组可以给出。那么一个显而易见的方案就是用虚拟网卡来完成,图示如下:
以上的原理图很简单,但是实施起来还真有几个细节。其中最关键是路由的细节,我们知道,即使是策略路由,也必须无条件从local表开始查找,在目标地址是本机情况下,如果希望数据按照以上流程走的话,就必须将该地址从local表删除,然而一旦删除,本机将不再会对该地址回应ARP请求。因此可以用几个方案:
1.使用静态ARP或者使用ebtables更改ARP,或者使用arping主动广播arp配置;2.使用一个非本机的地址,然后修改虚拟网卡的xmit函数,内部使其DNAT成本机地址,这就绕开了local表的问题。
不考虑细节,仅就上述原理图讨论的话,你可以在常规路径的PREROUTING中做很多事情,比如使用socket match关联socket,也可以使用IPMARK。
下面,我们就可以按照上述图示,实际实现一个能用的。首先先要实现一个虚拟网卡。仿照loopback接口做一个用于流控的虚拟接口,首先创建一个用于ingress流控的虚拟网卡设备
dev = alloc_netdev(0, "ingress_tc", tc_setup);static const struct net_device_ops tc_ops = {
.ndo_init = tc_dev_init,
.ndo_start_xmit= tc_xmit,
};
static void tc_setup(struct net_device *dev)
{
ether_setup(dev);
dev->mtu = (16 * 1024) + 20 + 20 + 12;
dev->hard_header_len = ETH_HLEN; /* 14 */
dev->addr_len = ETH_ALEN; /* 6 */
dev->tx_queue_len = 0;
dev->type = ARPHRD_LOOPBACK; /* 0x0001*/
dev->flags = IFF_LOOPBACK;
dev->priv_flags &= ~IFF_XMIT_DST_RELEASE;
dev->features = NETIF_F_SG | NETIF_F_FRAGLIST
| NETIF_F_TSO
| NETIF_F_NO_CSUM
| NETIF_F_HIGHDMA
| NETIF_F_LLTX
| NETIF_F_NETNS_LOCAL;
dev->ethtool_ops = &tc_ethtool_ops;
dev->netdev_ops = &tc_ops;
dev->destructor = tc_dev_free;
}接着构建其xmit函数
static netdev_tx_t tc_xmit(struct sk_buff *skb,
struct net_device *dev)
{
skb_orphan(skb);
// 直接通过第二层!
skb->protocol = eth_type_trans(skb, dev);
skb_reset_network_header(skb);
skb_reset_transport_header(skb);
skb->mac_len = skb->network_header - skb->mac_header;
// 本地接收
ip_local_deliver(skb);
return NETDEV_TX_OK;
}方案1:如果不想设置arp相关的东西,就要修改内核了。在此我引入了一个路由标志,RT_F_INGRESS_TC,凡是有该标志的路由,全部将其导入到构建的虚拟网卡中,为了策略化,我并没有在代码中这么写,而是改变了RT_F_INGRESS_TC路由的查找顺序,优先查找策略路由表,然后再查找local表,这样就可以用策略路由将数据包导入到虚拟网卡了。
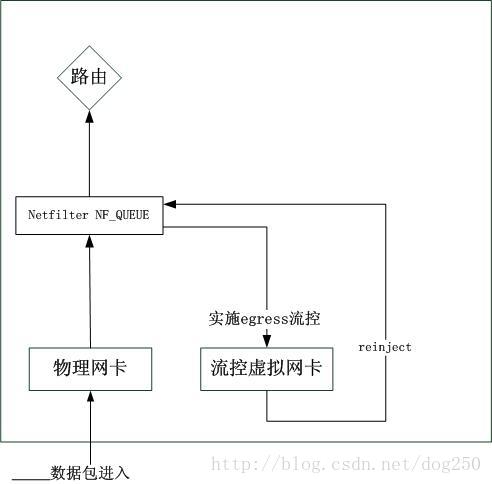
方案2:构建一个Netfilter HOOK,在其target中将希望流控的数据NF_QUEUE到虚拟网卡,即在queue的handler中设置skb->dev为虚拟网卡,调用dev_queue_xmit(skb)即可,而该虚拟网卡则不再符合上面的图示,新的原理图比较简单,只需要在虚拟网卡的hard_xmit中reinject数据包即可。(事实上,后来我才知道,原来IMQ就是这么实现的,幸亏没有动手去做无用功)
方案3:这是个快速测试方案,也就是我最原始的想法,即将目标IP地址从local表删除,然后手动arping,我的测试也是基于这个方案,效果不错。
不管上面的方案如何变化,终究都是一个效果,那就是既然网卡的ingress不能流控,那就在egress上做,而又不能使用物理网卡,虚拟网卡恰好可以自定义其实现,可以满足任意需求。我们可以看到,虚拟网卡是多么的功能强大,tun,lo,nvi,tc...所有这一切,精妙之处全在各自不同的xmit函数。
Linux内核协议栈处理流程的重构
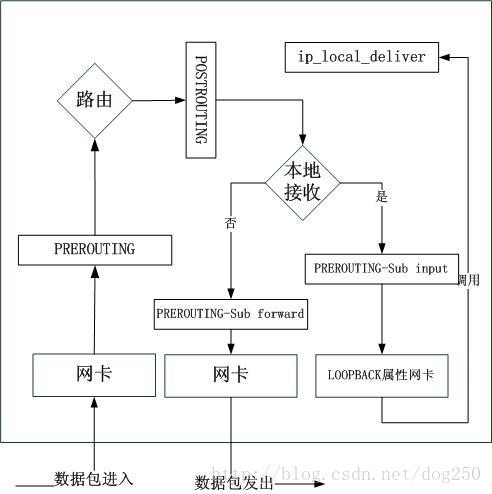
个人觉得,Linux网络处理还有一个不对称的地方,那就是路由后的转发函数,我们知道Linux的网络处理在路由之后有个分叉,根据目的地的不同,处理逻辑就此分道扬镳,如果路由结果带有LOCAL标志,那么就调用ip_local_deliver,反之调用ip_forward(具体参看ip_route_input_slow中对rth->u.dst.input的赋值)。如此一来,LOCAL数据就径直发往本地了,这其实也是RFC的建议实现,它简要的描述了路由算法:先看目标地址是不是本地,如果是就本地接收...然而我认为(虽然总是带有一些不为人知的偏见),完全没有必要分道扬镳,通过一个函数发送会更加好一点,比如发往本地的数据包同样发往一块网卡处理,只是该块网卡是一块LOOPBACK网卡,这样整个IP接收例程就可以统一描述了。类似的,对于本地数据发送也可以统一由一个虚拟的LOOPBACK网卡发送,而不是直接发送给路由模块。整体如下图所示:
1.不再需要INPUT这个HOOK点;
2.不再需要FORWARD这个HOOK点;
3.不再需要OUTPUT这个HOOK点,和第1点,第2点一起让Netfilter的整体架构也完全脱离了马鞍面造型;由此,本机发出的数据在DNAT后再也不用reroute了,其实,本来NAT模块中处理路由就很别扭...
4.策略路由可以更加策略化,因为即使目标地址是local表的路由,也可以将其热direct到别的策略表中。
就着以上第3点再做一下引申,我们可以很容易实现N多种虚拟网卡设备,在其中实现几乎任意的功能,比如这个ingress的流控,就可以很容易实现,不需要改内核和做复杂的配置,只要写一个虚拟网卡,配置几条策略路由即可。如此重新实现的协议栈处理逻辑可能某种程度上违背了协议栈分层设计的原则,但是确实能带来很多的好处,当然,这些好处是有代价的。值得注意的是,少了3个HOOK点是一个比较重要的问题,一直以来,虽然OUTPUT在路由后挂载,可是它实际上应该是路由前的处理,INPUT难道不是路由后吗?为何要把POSTROUTING又区分为INPUT和FORWARD,另外FORWARD其实也是路由后的一种...真正合理的是,INPUT和FORWARD应该是挂载在POSTROUTING上的subHOOK Point,可以将它们实现成一个HOOK Operation,对于OUTPUT,直接去除!HOOK点并不区分具体的逻辑,也不应该区分,这种逻辑应该让HOOK Operation来区分。
Linux的IMQ补丁
在实现了自己的虚拟网卡并配置好可用的ingress流控之后,我看了Linux内核的IMQ实现,鉴于之前从未有过流控的需求,一直以来都不是很关注IMQ,本着什么东西都要先自己试着实现一个或者给出个自己的方案(起码也要有一个思想实验方案)然后再与标准实现(所谓的标准一词并不是那么经得起推敲,实际上它只是“大家都接受的实现”的另一种说法,并无真正的标准可言)对比的原则,我在上面已经给出了IMQ的思想。IMQ补丁,其核心侧重在以下4点:
1.命名。IMQ中的Intermediate,我觉得非常好,明确指出使用一个中间层来适配igress的流控;
2.实现一个虚拟网卡设备。即所谓的Intermediate设备;
3.NF_QUEUE的使用。使用Netfilter的NF_QUEUE机制将需要流控的数据包直接导入虚拟设备而不是通过策略路由间接将数据引入虚拟设备。
4.扩充了skb_buff数据结构,引入和IMQ相关的管理字段。个人认为这是它的不足,我并不倾向于修改核心代码。然而在我自己的虚拟设备实现中,由于ip_local_deliver函数并没有被核心导出(EXPORT),导致我不得不使用/proc/kallsym来查找它的位置,这么做确实并不标准,我不得不修改了核心,虽然只是添加了一行代码:
EXPORT_SYMBOL(ip_local_deliver);
但是还是觉得不爽!
IMQ的总图如下:















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









