







第十一章YDB场景精选
一、多维检索与探索性分析
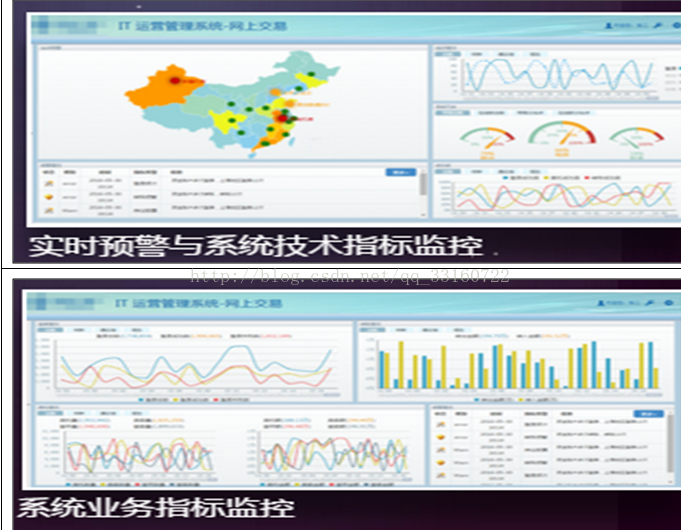
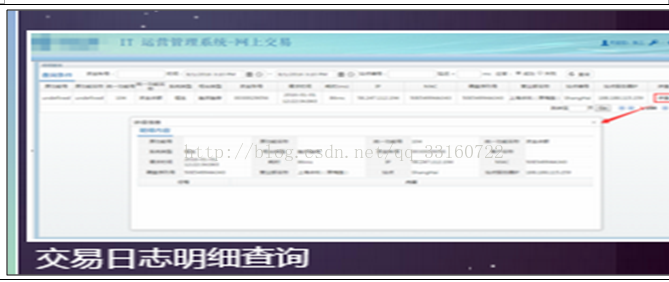
1.IT运维日志、业务日志、交易流水日志的搜索与分析
通过方便灵活的日志搜索分析,帮助用户及时发现问题
l统一日志查询平台,程序故障定位平台
开发与运维人员经常需要登录线上生产系统,通过grep、tail、more、cat等命令去生产系统里查找故障原因,排查效率很慢。且在生产系统运维人员因错误的使用调试命令导致生产系统宕机的情况路见不鲜。
组建一个统一的日志查询管理平台非常重要,开发人员可以像使用百度那样在日志平台里快速的检索与分析日志,快速定位问题。日志分析与生产系统分离,即保障了生产系统的安全,也省去了登录服务器的操作,提高了运维的效率与质量。
一个大型的系统,会有多种不同的业务子系统,这些系统的日志散落在不同的机器的每个角落。在统一日志查询平台可以跨越多个业务子系统进行日志的关联分析,对业务整体进行全局分析。
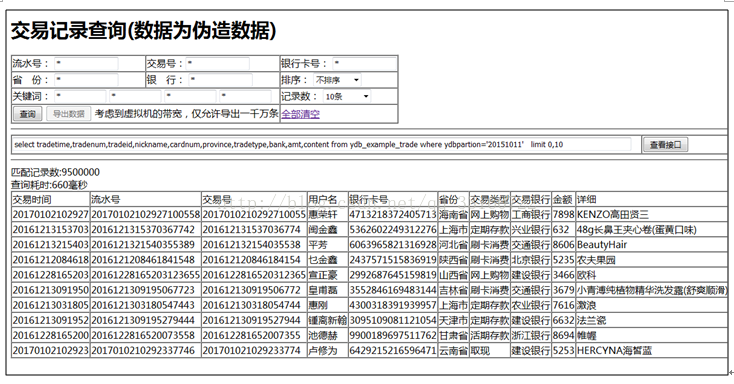
l交易流水搜索
物流系统,网站,运营商,证券交易所,零售商每天有大量的销售,访问日志。会有客户投诉扣费不准确,或者账户资金丢失的问题,需要客服人员对这些日志进行分析、过滤、筛选 从而追踪真实的扣费细节,在那个环境支付出现了异常,如果账户被盗,资金最终流向了哪里,尽量减少用户的损失。
l核心功能根据关键词,ID、时间等快速定位日志
1.系统问题定位 排查系统故障
2.根据日志分析,系统性能与网络瓶颈
3.如果用户投诉可以通过交易号定位用户交易日志,定位哪个环节的支付出现异常
l数据量太大,检索成难题
现如日志分析已经不是什么新鲜事,但是数据量特别庞大,普通的传统数据库已经承受不了这么大规模的日志存储,就更别提日志分析了。以笔者成有幸在在腾讯工作期间,研发并设计了腾讯的Hermes系统,Hermes当时每天存储的日增量为每天3600多亿(截止去年16年10月,为每天7000亿),总的数据存储量在万亿规模。
2.探索性即席分析之棱镜门大数据监听
棱镜计划(PRISM)是一项由美国国家安全局自2007年起开始实施的绝密电子监听计划。
根据斯诺登披露的文件,棱镜"监控的主要有10类信息:电邮、即时消息、视频、照片、存储数据、语音聊天、文件传输、视频会议、登录时间和社交网络资料的细节都被政府监控。通过棱镜项目,国安局甚至可以实时监控一个人正在进行的网络搜索内容
YDB可以为这其中的海量数据提供实时的存储以及即席的搜索服务。
因YDB的数据时效性较高,并且检索速度很快,该领域未来在工信部以及公安系统上会有较大的应用前景。
3.相似近似搜索与近似特征匹配
有些时候,我们只想找到一篇跟当前指定文章类似的文章。可能中间相差几个字不一样无所谓,或者局部的字顺序前后颠倒也无所谓。这个时候可以体验下YDB提供的“近似文本匹配”功能,该功能比较适合大段的文章匹配,如专利相似度匹配、网络舆情相似匹配。
有一种搜索是这样的搜索,我指定一系列的特征,如 高矮,胖瘦,年龄段,性别,时间等一系列目击者看到的嫌疑人特征,但是有可能有些目击者描述的不准确,所以不能进行精确匹配,如果能与大部分的匹配条件都相似,一两个条件没匹配上,但已经足以相似了,那么也要返回匹配结果。
二、机动车缉查布控即席分析
自2012年以来,公安部交通管理局在全国范围内推广了机动车缉查布控系统(简称卡口系统),通过整合共享各地车辆智能监测记录等信息资源,建立了横向联网、纵向贯通的全国机动车缉查布控系统,实现了大范围车辆缉查布控和预警拦截、车辆轨迹、交通流量分析研判、重点车辆布控、交通违法行为甄别查处及侦破涉车案件等应用。在侦破肇事逃逸案件、查处涉车违法行为、治安防控以及反恐维稳等方面发挥着重要作用。
随着联网单位和接入卡口的不断增加,各省市区部署的机动车缉查布控系统积聚了海量的过车数据。截至目前,全国32个省(区、市)已完成缉查布控系统联网工作,接入卡口超过50000个,汇聚机动车通行数据总条数超过2000亿条。以一个中等规模省市为例,每地市每日采集过车信息300万条,每年采集过车信息10亿条,全省每年将汇聚超过200亿条过车信息。如何将如此海量的数据管好、用好成为各省市所面临的巨大挑战。
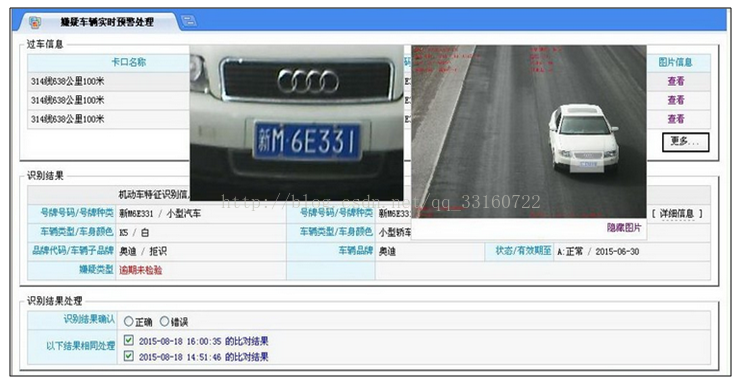
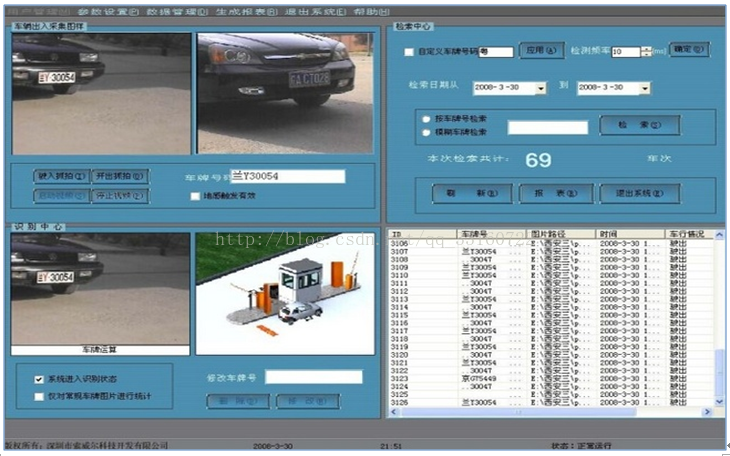
1.典型需求
n行车轨迹查询分析
精确查询:通过号牌种类、号牌号码、时间等条件查询机动车通行数据;模糊查询:通过模糊的号牌号码、卡口、时间、车身颜色、车辆类型等条件查询机动车通行数据。
n嫌疑车辆分析
挖掘在不同地点多次同行的车辆。根据确认的车辆,寻找同行车。挖掘不同时间段通过一个或多个卡口的车辆筛选分析。分析判断在某一区域、某一特定时间段第一次出现的车辆。分析判断部分车辆某个时间点进城后不出城或是晚上某个时间点进城或出城,筛选出有规律性的车辆。
n数据碰撞分析
跨地区的海量机动车过车数据碰撞,分析出假套牌车辆,通过识别车辆品牌、颜色等特征信息,比对车辆登记信息,发现套牌假牌车辆;重点车辆、报废车辆与过车数据的分析碰撞,发现未按照规定时间、线路、已报废仍在路面行驶的车辆信息。
n重点车辆分析
根据统计一定区域范围内的客运、危险品运输、特殊车辆等重点车辆通行数量,研判发现通行规律。对在路段内行驶时间异常的车辆、首次在本路段行驶、预期报废、未年检仍在道路上行驶的重点车辆、2到5点仍在道路上行驶的客运车辆等进行预警提示。
n车辆出入统计分析
挖掘统计一段时间内在某一个区域内(可设定中心城区、地市区域、省市区域、高速公路等区域)、进出区域、主要干道的经常行驶车辆、“候鸟”车辆、过路车辆的数量以及按车辆类型、车辆发证地的分类统计。
2.关键能力
n数据规模
能够承载日均数亿条增量,未来三到五年,数百亿,甚至数千亿条数据总量。
n即席分析
根据不同的城市,往往在逻辑上有较大的区别,不同的案件也会有较大的不同,故一个查询系统要求非常灵活,可以处理复杂的业务逻辑,算法,而不是一些常规的简单的统计。
n高时效性
对数据时效性要求较高,要求某一车辆在经过某一卡口后,可达到分钟级别内系统可查可分析。对检索性能要求很高,以上典型需求均要求能够在秒级内返回结果及明细。
n企业级特性
易于部署,易于扩容,易于数据迁移;
多数据副本保护,无单点故障;
服务自动检测及恢复;
3.备选方案—优缺点分析
l开源大数据系统解决方案(Hadoop、Spark、Hive、Impala)
| 数据规模 | √ | 基于HDFS之上,数据可无限拓展,存储PB级的数据很轻松。 |
| 时效性 | × | HDFS的特性导致数据延迟较大,常规应用均是T+1数据,即延迟一天。 |
| 查询性能与并发 | × | 该类系统并非为即席查询而设计,比较适合离线分析,通常来说一个HiveSQL运行时间从几分钟到几小时不等,如果是百亿规模的数据分析时间可能会达到数个小时,如果以现有XX部门的预算来看,可能需要数天的时间,究其根本原因是该类系统是采用暴力扫描的方式,即如果是100亿条数据,也是采用从头遍历到末尾的方式扫描,性能可想而知, 基本无并发性可言。单并发就需要数小时。 |
| 灵活性 | √ | 1.SQL支持较为齐全。 2.与周边系统的集成非常方便,数据导入导出灵活。 3.支持JDBC方式,可以与常见的报表系统无缝集成。 |
| 运维 | √ | 硬件损坏,机器宕机后可自动迁移任务,不需要人工干预,中间不影响服务。 |
| 扩容迁移容灾 | √ | 1.从一开始设计之初,Hadoop即假设所有的硬件均不可靠,一旦硬件损坏,数据不会丢失,有多份副本可以自动恢复数据。 2.数据迁移以及机器扩容有比较完备的方案,中间不停服务,动态扩容。 |
| 数据规模 | √ | 基于HDFS之上,数据可无限拓展, |
| 时效性 | √ | 时效性非常好,一般与Kafka采用消息队列的方式导入,时效性可达几秒可见。 |
| 查询性能与并发 | √ | 1.预先将需要查询的数据计算好,查询的时候直接访问预计算好的结果,性能非常好。 2.预计算完毕的结果集存储在HBase或传统数据库里,因数据规模并不大故并发性比较好。 |
| 灵活性 | × | 无法查看明细数据,只能看特定粒度的汇总结果,而过车记录是无法先计算出来的,即无法预知那个车有可能会犯罪,那个车会出事故,故无法预计算。 |
| 运维 | √ | 损坏的机器会自动摘除,进行会自动迁移,服务不中断。 |
| 扩容迁移容灾 | √ | 数据迁移,扩容,容灾均有完善的方案,Storm的扩容需要简单的Rebanlance即可。 |
| 数据规模 | × | 1.典型使用场景在千万级别,如果给予较大内存,数据量可上亿。 2.本身系统内存的限定,百亿以上降会是巨大的挑战。 |
| 时效性 | × | 1.支持实时导入,在千万数据规模下导入性能较好。 2.数据过亿后,生产系统实时导入经常会出现OOM,以及CPU负载太高的问题,故过亿数据无法实时导入数据,一般都采用离线创建索引的方式,即数据时效性延迟一天。 |
| 查询性能与并发 | √ | 1.采用倒排索引,直接根据索引定位到相关记录,而不需要采用全表暴力扫描的方式,检索查询性能特别高。 2.在千万级别以下,并且给予较多内存的情况下,并发情况很好。 |
| 灵活性 | × | 1.为搜索引擎的场景而生,分析功能较弱。只有最简单的统计功能,无法满足过车记录复杂的统计分析需求。 2.与周边系统的集成麻烦,数据导入导出太麻烦,甚至不可行,第三方有SQL引擎插件,但均是简单SQL,且由于Merger server是单节点的问题,很多SQL的查询性能很低,不具备通用性。 3.无法与常见的支持jdbc标准的报表系统集成,定制开发代价较大。 |
| 运维 | × | 1.数据规模一旦过百亿,就会频繁的出现OOM,节点调片的情况。 2.一旦调片后无法自动恢复服务,需要运维人员去重启相关服务。 3.系统无过载保护,经常是一个人员做了一个复杂的查询,导致集群整体宕机,系统崩溃。 |
| 扩容迁移容灾 | × | 1.数据存储在本地磁盘,一旦本地将近20T的存储盘损坏,需要从副本恢复后才能继续服务,恢复时间太长。 2.数据迁移不完善,如若夸机房搬迁机器,需要运维人员细心的进行索引1对1复制,搬迁方案往往要数星期,且非常容易出错。 3.数据如若想导出到其他系统很难,超过百万级别的导出基本是不可行的,更别提复杂计算后的导出,没有成型的高可用的导出方案。 |
4.YDB无论是精确查询还是模糊查询都在毫秒级响应
针对上述典型场景,我们最终将多个系统整合,发挥系统的各自优势,扬长避短,深度集成。延云YDB作为机动车缉查布控即席分析引擎,已经在近10个城市的成功部署或测试,取得非常好的效果,有的甚至超过了客户的预期。
YDB是一个基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的万级维度秒级统计分析能力,并具备企业级的稳定可靠表现。
YDB是一个细粒度的索引,精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark直接对YDB检索结果集分析计算,同样场景让Spark性能加快百倍。
| 数据规模 | √ | 在政府某部门:用4~10台普通PC即可支撑百亿规模的数据。 在IBM的小型机上:用10台机器就支持一万亿的数据规模。 在某互联网公司:支撑了每天7000亿,总量几万亿的数据查询。 |
| 时效性 | √ | 结合了Storm流式处理的优点,采用对接消息队列(如Kafka)的方式,数据导入Kafka后大约1~2分钟即可在YDB中查到。 |
| 并发查询性能 | √ | 1.借鉴了Solr与Elastic Search,使用了倒排索引,查询的时候直接定位到相关记录,避免了对数据的暴力扫描。 2.借鉴Spark的process local方式,让同一份数据尽量在同一个进程内重用,以便能够高效的Cache。 3.结合标签技术、不必读取列的值本身,而是只读取其数值字典代号,更小的IO,能够让数据比常规计算能够更快的进行process local级的combine。 4.延迟列加载技术,可以让一些列的值在最终返回给用户的时候在读取,相比Spark的列存储方式通常可以节省该列90%以上的IO。 5.采用列存储计算,列与列之间在存储上分开, 6.百亿规模1秒内响应,万亿规模10台IBM机器3~5秒响应。一般根据数据量,常规查询可支撑200~300个人一起并发查询。 |
| 灵活性 | √ | 1.我们将索引集成到了Spark内部,这样结合Spark可以做很多复杂的计算,但又兼顾了倒排索引的高性能。用户可以写复杂的SQL,可以嵌套、可以join、可以distinct、可以自定义UDF\UDAF\UDTF函数来扩中SQL的功能。 2.因Hive已经成为大数据的实时标准,YDB采用Hive SQL的方式与周边系统的集成非常方便,数据导入导出灵活。 3.Hive本身支持JDBC方式,可以与常见的报表系统无缝集成。 |
| 运维 | √ | 1.采用Spark Yarn的方式,系统宕机,硬件损坏,服务会自动迁移,数据不丢失。 2.延云YDB只需要部署在一台机器上,由Yarn自动分发,不需要维护一堆机器的配置,改参数很方便。 |
| 扩容迁移容灾 | √ | 数据存储在HDFS之上,不存储在本地硬盘,扩容,迁移,容灾与Hadoop一样,稳定可靠。 |
5.行车轨迹查询/重点车辆分析
| 描述 | 一般根据一个车牌号,去搜寻特定车辆的行车轨迹。在XX部门的系统里用于追踪嫌犯的犯罪过程,或者对重点车辆进行分析。 |
| SQL | /*ydb.pushdown('->')*/ select hphm,kkbh,jgsj,jgsk,quyu from ydb_jiaotong where hphm="云NEW336" order by jgsj desc limit 10 /*('<-')pushdown.ydb*/ |
6.同行车辆分析
| 描述 | 可以根据目标车辆过车的前后时间,经过的地点,找到目标车辆的同行车辆。该功能一般用于查询“盯梢”,“跟踪”车辆。如果遇到绑架等案件,可以根据被绑架人的车辆的过车记录,查询出“盯梢”车辆,从而为案件的侦破提供更多的线索。 |
| SQL | select tmp.hphm,count(*) as rows,size(collect_set(tmp.kkbh)) as dist_kkbh,concat_ws('#', sort_array(collect_set(concat_ws(',',tmp.jgsj,tmp.kkbh)))) as detail from ( /*ydb.pushdown('->')*/ select hphm,jgsj,kkbh from ydb_oribit where ydbpartion = '20160619' and ( (jgsj like '([201604290000 to 201604290200] )' and kkbh='10000000') or ( jgsj like '([201604290001 to 201604290301] )' and kkbh='10000001') or (jgsj like '([201604290002 to 201604290202] )' and kkbh='10000002') ) /*('<-')pushdown.ydb*/ ) tmp group by tmp.hphm order by dist_kkbh desc |
7.区域碰撞分析
| 描述 | 根据不同时间段的不同卡口(路段),找出在这些卡口上同时出现的车辆。该功能一般用于破获连环作案的案件,追踪逃犯,如部分城市最近经常在出现抢-劫的行为,就可以根据多个抢-劫的时间与地点,进行碰撞分析,如果多个抢-劫的地点周围均出现该车辆,那么该车为嫌疑车辆的可能性就非常大,从而更有助于连环案件的侦破。 |
| SQL | select tmp.hphm, count(*) as rows, size(collect_set(tmp.quyu)) as dist_quyu, concat_ws('#', sort_array(collect_set(concat_ws(',',tmp.jgsj,tmp.quyu)))) as detail from ( /*ydb.pushdown('->')*/ select hphm,jgsj,quyu from ydb_jiaotong where ( (jgsj like '([201604111454 TO 201604131554] )' and quyu='安义路阁馨') or (jgsj like '([201609041043 TO 201609041050] )' and quyu='恒仁路太阳星城') or (jgsj like '([201609040909 TO 201609040914] )' and quyu='环江路大有恬园' /*('<-')pushdown.ydb*/ ) tmp group by tmp.hphm order by dist_quyu desc limit 10 |
8.陌生车辆分析
| 描述 | 用于搜寻某一地区,在案发期间出现过,并且在这之前没有出现或出现次数较少的车辆。陌生车辆对于小区盗-窃,抢-劫等案件的侦破可以提供较多的侦破线索。 给出一个时间范围【A TO B】,搜寻出一个区域内的所有车辆. 如果在这个时间范围出现过,并且在之前的 C天内出现次数少于N次的车辆
|
| SQL | select * from ( select tmp.hphm, count(*) as rows, max(tmp.jgsk) as max_jgsj, size(collect_set(tmp.jgsk)) as dist_jgsj, size(collect_set(case when ((tmp.jgsk>='20161201153315' and tmp.jgsk<='20161202153315') or (tmp.jgsk>='20161203153315' and tmp.jgsk<='20161204153315')) then 0 else tmp.jgsk end )) as dist_before, concat_ws('#', sort_array(collect_set(concat_ws(',',tmp.jgsk,tmp.kkbh)))) as detail from ( /*ydb.pushdown('->')*/ select hphm,jgsk,kkbh from t_kk_clxx where jgsk like '([20161201153315 TO 20161204153315] )' and kkbh IN('320600170000089780','320600170000000239','320600170000000016','320600170000000018','320600170000002278','320600170000092977','320600170000092097','320600170000092117') /*('<-')pushdown.ydb*/ ) tmp group by tmp.hphm ) tmp2 where tmp2.dist_before<='1' order by tmp2.dist_jgsj asc limit 10
|
9.昼伏夜出、落脚点分析
| 描述 | 可以针对某一车辆,查询其出行规律,分析其日常在每个时段的出行次数,经常出路的地点。通过分析车辆的出行规律,从而可以识别某一量车是否出现异常的出行行为,有助于对案件事发地点出现的车辆进行一起集体扫描,如果有车辆的该次出行行为与平日的出行行为不一致,那么该车极有可能就是嫌疑车辆。 |
| SQL | select tmp.jgsk, count(*) as rows, size(collect_set(tmp.quyu)) as dist_quyu, concat_ws('#', sort_array(collect_set(concat_ws(',',tmp.jgsj,tmp.quyu)))) as detail from ( /*ydb.pushdown('->')*/ select jgsk,jgsj,quyu from ydb_jiaotong where hphm='黑NET458' /*('<-')pushdown.ydb*/ ) tmp group by tmp.jgsk order by dist_quyu desc limit 10 |
10.嫌疑车牌模糊搜索与定位
| 描述 | 因摄像头因夜晚或者天气等原因拍摄到的车牌识别不清,或者交通孽事车辆逃逸,目击证人只记住了车牌号的一部分,但知道车的颜色,是什么车等信息。但是事发路段可能会有多个其他交通探头能识别出该车牌。故可以根据车牌号码模糊检索,在结合车辆颜色,时间,车的型号等综合匹配出最有可能的车牌。从而定位到嫌疑车辆。
注意下面的hphm_search为charlike类型,可以进行号牌号码的模糊检索 |
| SQL | select tmp.hphm,count(*) as rows,size(collect_set(tmp.kkbh)) as dist_kkbh from ( /*ydb.pushdown('->')*/ select hphm,kkbh from ydb_jiaotong where hphm_search='NEW33' /*('<-')pushdown.ydb*/ ) tmp group by tmp.hphm order by dist_kkbh desc limit 10 |
三、OLAP之多维分析,指数分析,人群画像
(注:本节内容出处http://webdataanalysis.net/web-data-warehouse/data-cube-and-olap/)
多维数据模型作为一种新的逻辑模型赋予了数据新的组织和存储形式,而真正体现其在分析上的优势还需要基于模型的有效的操作和处理,也就是OLAP(On-line Analytical Processing,联机分析处理)。
多维分析:可以帮助用户进行多角度、灵活动态的分析。多维分析报表由“维”(影响因素)和 “指标”(衡量因素)组成,能够真正为用户所理解、并真实的反映企业特性信息。
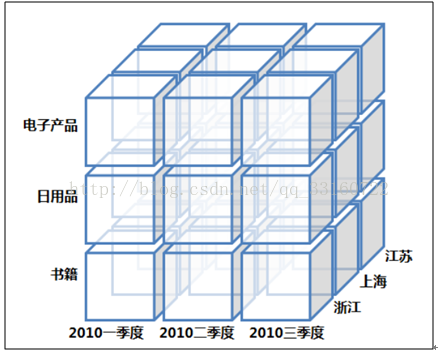
1.数据立方体
关于数据立方体(Data Cube),这里必须注意的是数据立方体只是多维模型的一个形象的说法。立方体其本身只有三维,但多维模型不仅限于三维模型,可以组合更多的维度,但一方面是出于更方便地解释和描述,同时也是给思维成像和想象的空间;另一方面是为了与传统关系型数据库的二维表区别开来,于是就有了数据立方体的叫法。所以本文中也是引用立方体,也就是把多维模型以三维的方式为代表进行展现和描述
2.OLAP
OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合。可以比较下其与传统的OLTP(On-line Transaction Processing,联机事务处理)的区别来看一下它的特点:
3.OLAP与OLTP
| 数据处理类型 | OLTP | OLAP |
| 面向对象 | 业务开发人员 | 分析决策人员 |
| 功能实现 | 日常事务处理 | 面向分析决策 |
| 数据模型 | 关系模型 | 多维模型 |
| 数据量 | 几条或几十条记录 | 百万千万条记录 |
| 操作类型 | 查询、插入、更新、删除 | 查询为主 |
4.OLAP的基本操作
我们已经知道OLAP的操作是以查询——也就是数据库的SELECT操作为主,但是查询可以很复杂,比如基于关系数据库的查询可以多表关联,可以使用COUNT、SUM、AVG等聚合函数。OLAP正是基于多维模型定义了一些常见的面向分析的操作类型是这些操作显得更加直观。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以上面的数据立方体为例来逐一解释下:

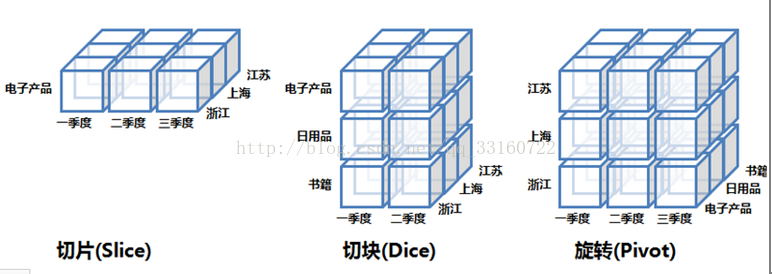
钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
5.OLAP的优势
首先必须说的是,OLAP的优势是基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式,如果脱离的这两点,OLAP将不复存在,也就没有优势可言。
数据展现方式
基于多维模型的数据组织让数据的展示更加直观,它就像是我们平常看待各种事物的方式,可以从多个角度多个层面去发现事物的不同特性,而OLAP正是将这种寻常的思维模型应用到了数据分析上。
查询效率
多维模型的建立是基于对OLAP操作的优化基础上的,比如基于各个维的索引、对于一些常用查询所建的视图等,这些优化使得对百万千万甚至上亿数量级的运算变得得心应手。
分析的灵活性
我们知道多维数据模型可以从不同的角度和层面来观察数据,同时可以用上面介绍的各类OLAP操作对数据进行聚合、细分和选取,这样提高了分析的灵活性,可以从不同角度不同层面对数据进行细分和汇总,满足不同分析的需求。
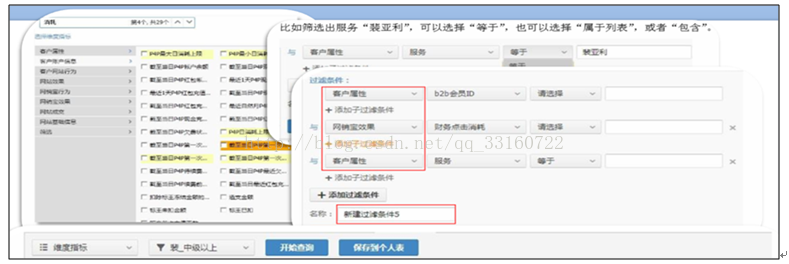
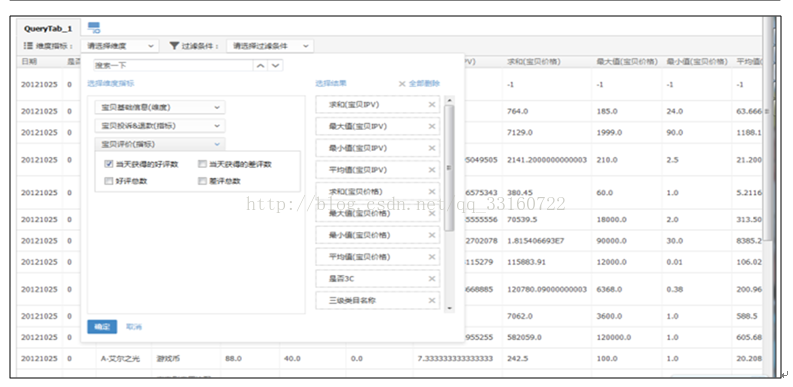
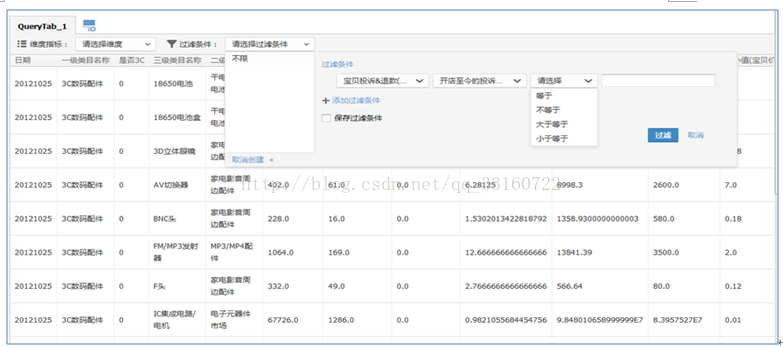
6.OLAP系统示例
多维分析系统示例
指数分析示例
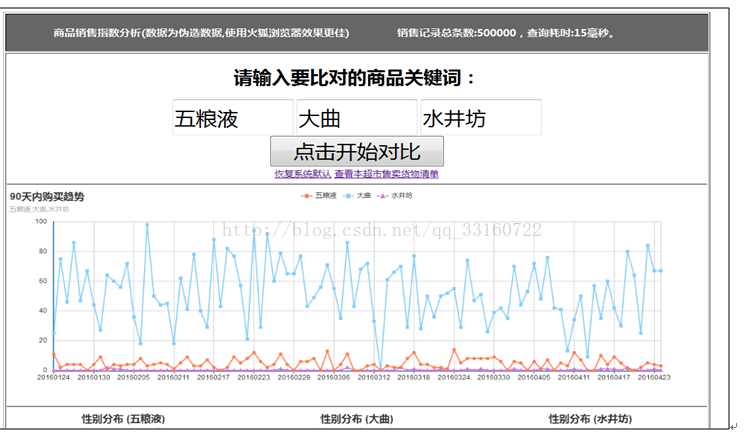
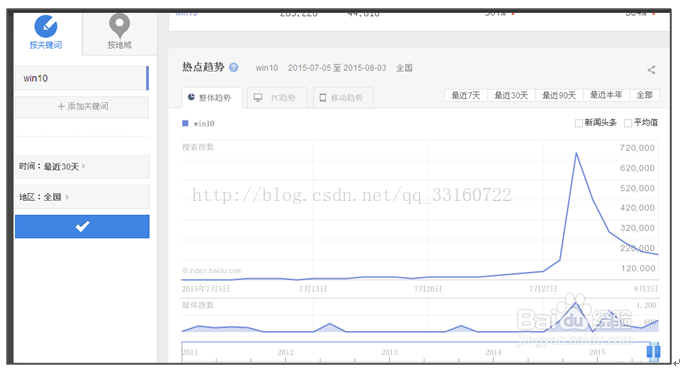
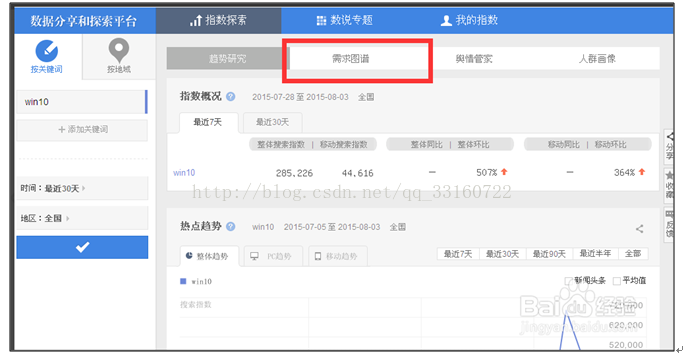
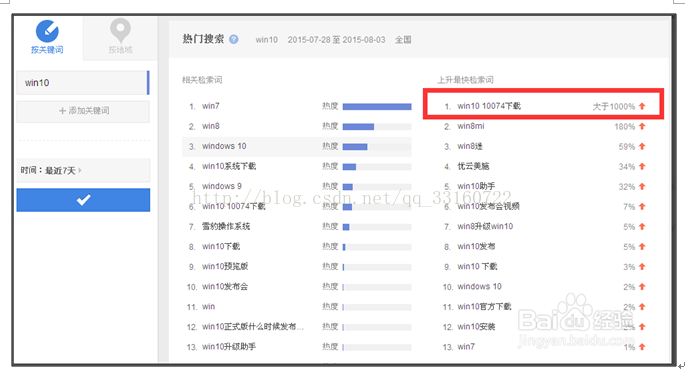
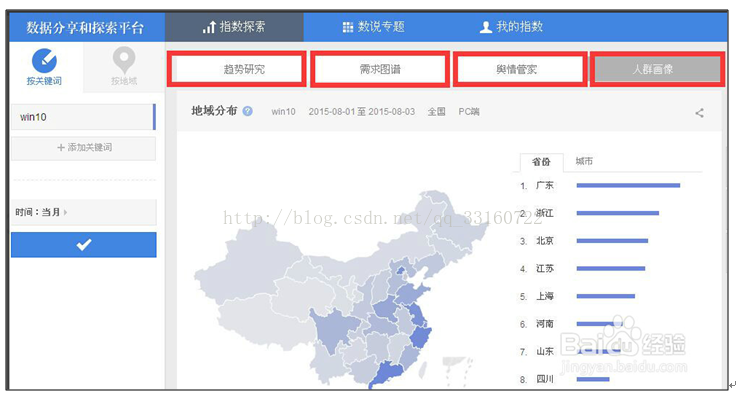
百度的搜索指数分析

淘宝的商品搜索指数分析示例

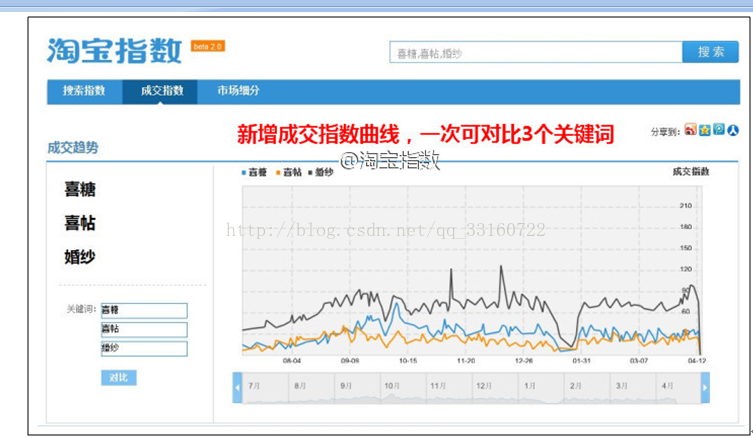
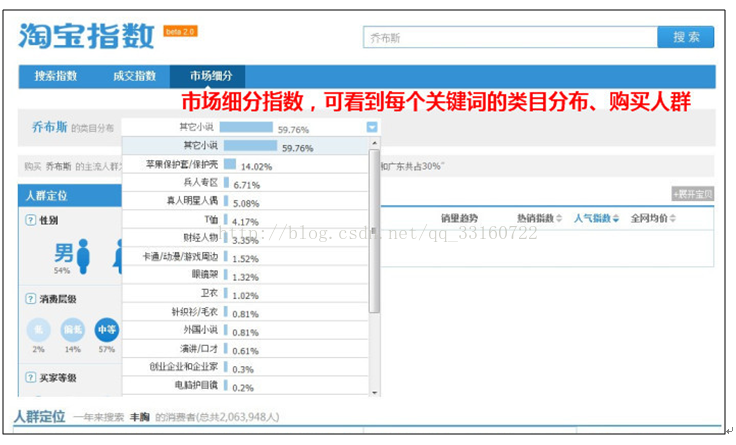
7.数据画像分析
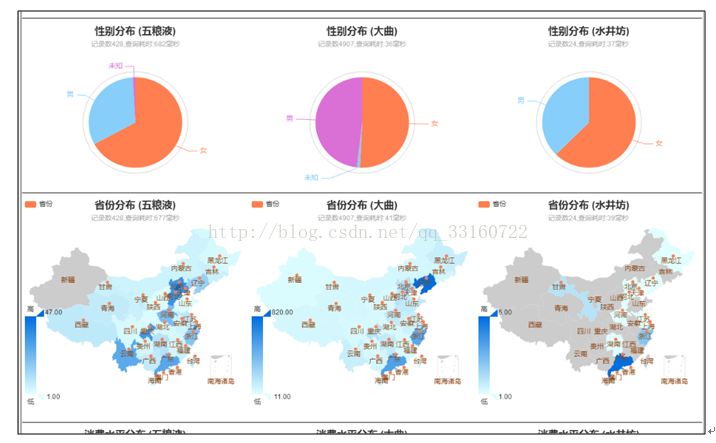
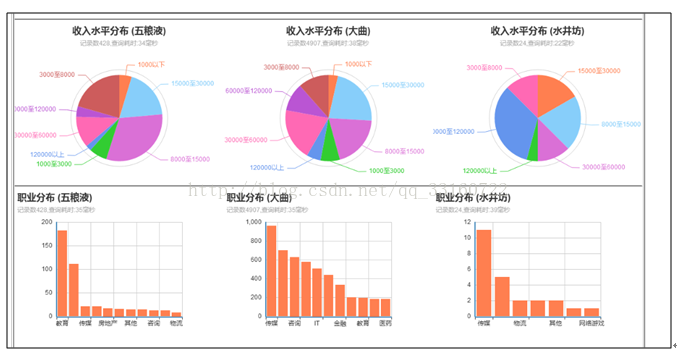
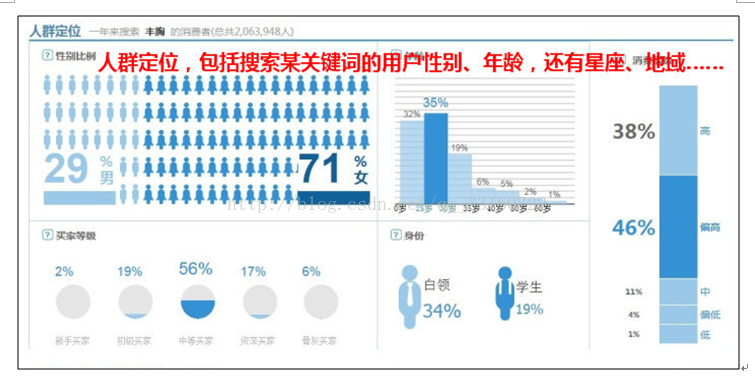
熟话说:知己知彼,百战不殆。用户画像就是在基于大量真实数据的基础上,从多个纬度真实反应用户特征,挖掘用户需求。从而在产品设计、运营策略等环节上,根据目标受总用户的特征进行更符合用户需求的设计和运营方式。具体到不同行业会有不同的应用方式和应用场景。例如:广告行业会进行精准广告推送,交易类平台进行用户个性化推荐,内容类网站进行内容优化和内容推荐。总之用户的特征和需求明确后,所有的活动将具有针对性,有助于提高服务的质量和产品的ROI。
人群画像是指产品消费者群体的性别、年龄、收入、城市、教育、家庭情况、生活态度,价值观念等特征。举个栗子:2011年公布的小米手机调查中显示:小米手机的消费者集中在18到35岁、男性、追逐功能、爱好科技、有一定的经济基础、白领或者学生、大学学历为主、分布在一二线城市。
8.画像示例
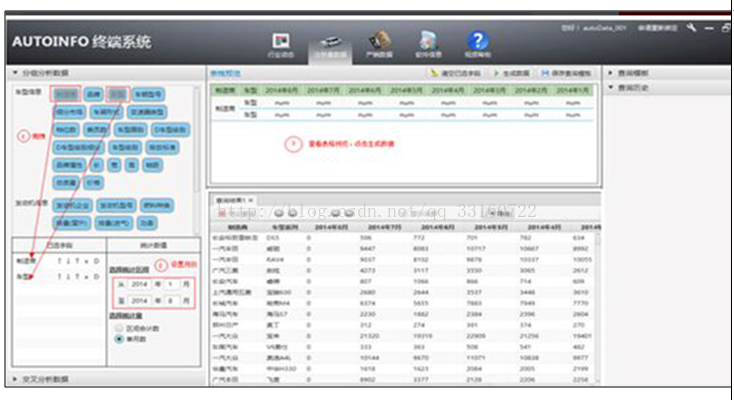
汽车销售数据画像
| |
| |
| |


股票交易数据分析
|
|
|
|
|
|
9.DMP数据管理平台之广告系统
个性化推荐
是否想过有一天当你在地铁上、公交上、电视上、马路上的大型电子显示屏或墙壁广告,他们可以感应到你,播放的广告都是为你量身定制的,都是你真正需要的。
富余服务能力的消化与精准投放
你是一个咖啡店主,当你的店比较清闲的时候,是否想过使用YDB搜索下周围3公里内的小资人群,告诉他们你这里有一个比较雅致的咖啡店,而且给他打5折,而当你的咖啡店人员比较满的时候就不在推送这些折扣服务。
10.DMP使用示例
创建人群与人群推送
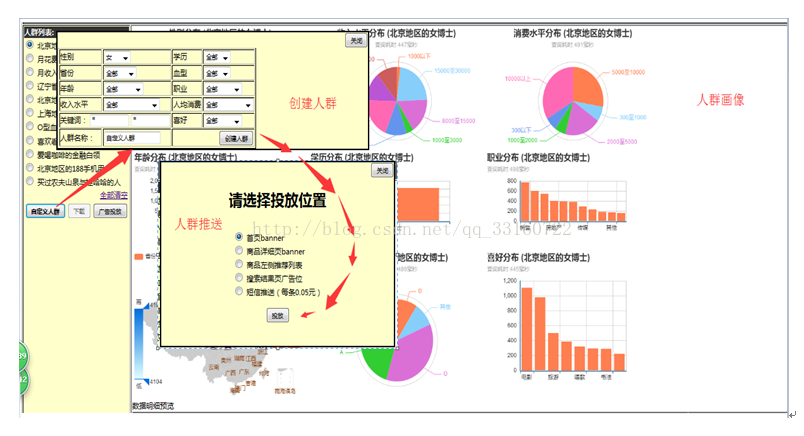
人群画像

商圈分析
|
|


















 4201
4201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









