







写Java或Android代码的同学,有没有苦恼,自己辛辛苦苦写出的代码,轻轻松松被人逆向,由于代码没做混淆,导致程序流程清晰可见。如果你想保护好自己的代码,下面跟我一起学习一款简单、常用的代码混淆工具:Proguard。
0x1 概述
ProGuard是一个混淆代码的开源项目。它的主要作用就是混淆,当然它还能对字节码进行缩减体积、优化等,但那些对于我们来说都算是次要的功能。详见官网:http://proguard.sourceforge.net/
0x2 ProGuard语法
| 输入输出选项 -include {filename} 从给定的文件中读取配置参数 -basedirectory {directoryname} 指定基础目录为以后相对的档案名称 -injars {class_path} 指定要处理的应用程序jar,war,ear和目录 -outjars {class_path} 指定处理完后要输出的jar,war,ear和目录的名称 -libraryjars {classpath} 指定要处理的应用程序jar,war,ear和目录所需要的程序库文件 -dontskipnonpubliclibraryclasses 指定不去忽略非公共的库类。 -dontskipnonpubliclibraryclassmembers 指定不去忽略包可见的库类的成员。
保留选项 -keep {Modifier} {class_specification} 保护指定的类文件和类的成员 -keepclassmembers {modifier} {class_specification} 保护指定类的成员,如果此类受到保护他们会保护的更好 -keepclasseswithmembers {class_specification} 保护指定的类和类的成员,但条件是所有指定的类和类成员是要存在。 -keepnames {class_specification} 保护指定的类和类的成员的名称(如果他们不会压缩步骤中删除) -keepclassmembernames {class_specification} 保护指定的类的成员的名称(如果他们不会压缩步骤中删除) -keepclasseswithmembernames {class_specification} 保护指定的类和类的成员的名称,如果所有指定的类成员出席(在压缩步骤之后) -printseeds {filename} 列出类和类的成员-keep选项的清单,标准输出到给定的文件
压缩选项 -dontshrink 不压缩输入的类文件 -printusage {filename} -whyareyoukeeping {class_specification}
优化选项 -dontoptimize 不优化输入的类文件 -assumenosideeffects {class_specification} 优化时假设指定的方法,没有任何副作用 -allowaccessmodification 优化时允许访问并修改有修饰符的类和类的成员
混淆选项 -dontobfuscate 不混淆输入的类文件 -printmapping {filename} -applymapping {filename} 重用映射增加混淆 -obfuscationdictionary {filename} 使用给定文件中的关键字作为要混淆方法的名称 -overloadaggressively 混淆时应用侵入式重载 -useuniqueclassmembernames 确定统一的混淆类的成员名称来增加混淆 -flattenpackagehierarchy {package_name} 重新包装所有重命名的包并放在给定的单一包中 -repackageclass {package_name} 重新包装所有重命名的类文件中放在给定的单一包中 -dontusemixedcaseclassnames 混淆时不会产生形形色色的类名 -keepattributes {attribute_name,...} 保护给定的可选属性,例如LineNumberTable, LocalVariableTable, SourceFile, Deprecated, Synthetic, Signature, and InnerClasses. -renamesourcefileattribute {string} 设置源文件中给定的字符串常量
常规选项 --verbose 记录处理过程中的详细信息 -dontwarn { class_specification } 不能解析的引用或其他重要的出错不给出提示 -ignorewarnings 打印不能解析的引用或其他重要的出错信息,但是处理不中断 |
0x3 ProGuand混淆实例
在Eclipse中新建SSO的Android工程,里面有以下几个类:

这里对这几个做个说明:其中BaseActivity/LoginActivity/MainActivity直接或间接继承Activity,MyBcReceiver/PhoneReceiver直接或间接继承BroadcastReceiver,而ActivityCollector是自定义的类。
实验目的:
只对ActivityCollector这个类混淆,保留直接或间接继承Activity或BroadcastReceiver的类,并且保留android.v4包的内容。
实验步骤:
Step1:首先打开“project.properties”文件,然后在文件中添加一行:proguard.config=./proguard-project.txt。文件中之前就有一行,不过是被注释掉了。这句话的意思是:使用当前目录下的proguard-project.txt作为混淆配置文件。
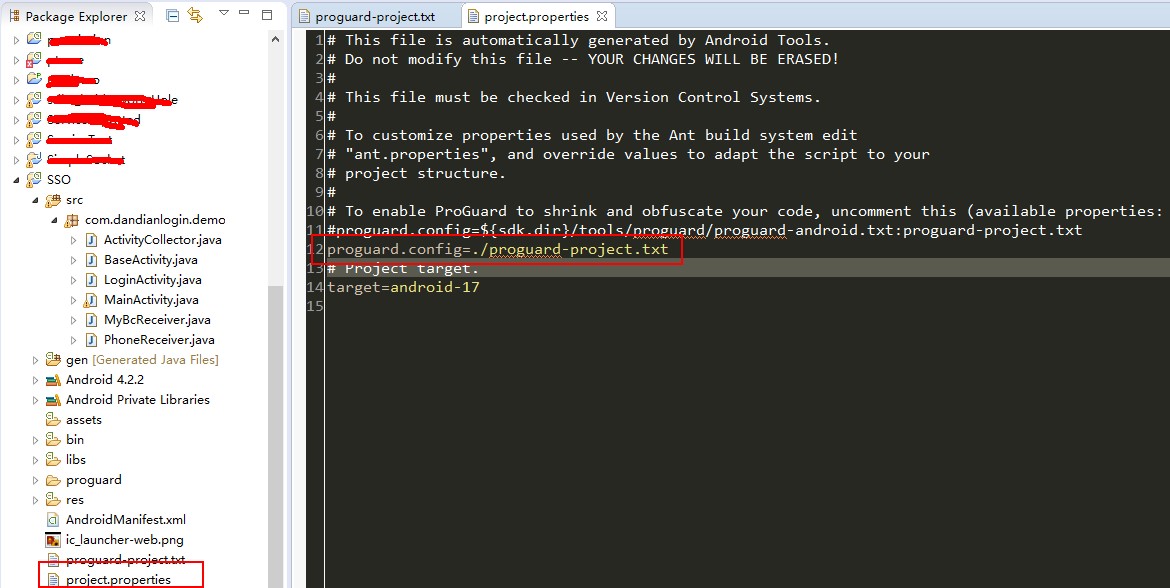
Step2:打开“proguard-project.txt”文件,配置混淆规则
因为只对ActivityCollector混淆,其他类或第三方库应该保护,对应的规则如下:
| -ignorewarnings # 忽略警告,避免打包时某些警告出现 -optimizationpasses 5 # 指定代码的压缩级别 -dontusemixedcaseclassnames # 是否使用大小写混合 -dontskipnonpubliclibraryclasses # 是否混淆第三方jar -dontpreverify # 混淆时是否做预校验 -verbose # 混淆时是否记录日志 -optimizations !code/simplification/arithmetic,!field/*,!class/merging/* # 混淆时所采用的算法
-dontwarn android.support.v4.** #缺省proguard 会检查每一个引用是否正确,但是第三方库里面往往有些不会用到的类,没有正确引用。如果不配置的话,系统就会报错。 -dontwarn android.os.**
-keep class android.support.v4.** { *; } # 保持哪些类不被混淆 -keep class android.os.**{*;} -keep public class * extends android.support.v4.** -keep public class * extends android.app.Fragment -keep public class * extends android.app.Activity -keep public class * extends android.app.Application -keep public class * extends android.app.Service -keep public class * extends android.content.BroadcastReceiver -keep public class * extends android.content.ContentProvider -keep public class * extends android.support.v4.widget -keep interface android.support.v4.app.** { *; } #保护哪些接口不被混淆 |
Step3: 使用Eclipse的导出功能将SSO.apk导出(直接运行的方式是不能应用proguard的)在工程上右键->"Export..."->“Export AndroidApplication”,导出apk包。可以使用Eclipse默认的keystore。
Step4:将导出的SSO.apk拖入到jeb中查看混淆结果
从下图结果可看出,ActivityCollector这个类被混淆了。

0x4 混淆后的文件说明
用eclipse export命令打包,会在<project_root>/proguard目录下产生4个文件。
mapping.txt
表示混淆前后代码的对照表,这个文件非常重要。如果你的代码混淆后会产生bug的话,log提示中是混淆后的代码,希望定位到源代码的话就可以根据mapping.txt反推。每次发布都要保留它方便该版本出现问题时调出日志进行排查,它可以根据版本号或是发布时间命名来保存或是放进代码版本控制中。

dump.txt
描述apk内所有class文件的内部结构。

seeds.txt
列出了没有被混淆的类和成员。

usage.txt
列出了源代码中被删除在 apk 中不存在的代码。
















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









