







conceptNet 下载
http://openkg.cn/dataset/conceptnet5-chinese
https://github.com/commonsense/conceptnet5/wiki/Downloads
conceptNet 读取
下载到的数据是 csv 格式的,用 utf8 格式读取
data = pd.read_csv(FILE, delimiter='\t')
data.columns = ['uri', 'relation', 'start', 'end', 'json']
表中内容看起来一团乱麻,实际含义很明确:
| 符号 | 含义 |
|---|---|
| /r | 关系,relation,边 |
| /c | 概念,concept,节点 |
| /zh | 中文 |
| /fr | 法语 |
| uri | 把(关系,起点,终点)三元组拼接成字符串,可作为索引 |
| json | 附加信息 |
删除不只含中文节点的关系(边)
data = data[data['start'].apply(lambda row: row.find('zh')>0) & data['end'].apply(lambda row: row.find('zh')>0)]
data.index = range(data.shape[0])
从 json 列中提取边的权重信息
import json
weights = data['json'].apply(lambda row: json.loads(row)['weight'])
data.pop('json')
data.insert(4,'weights',weights)
中文繁简体转换
from langconv import *转换繁体到简体
def cht_to_chs(line): line = Converter('zh-hans').convert(line) line.encode('utf-8') return line转换简体到繁体
def chs_to_cht(line): line = Converter('zh-hant').convert(line) line.encode('utf-8') return line
查询
只查询起始节点
def search(words, n=20):
result = data[data['start'].str.contains(chs_to_cht(words))]
topK_result = result.sort_values("weights", ascending=False).head(n)
return topK_result
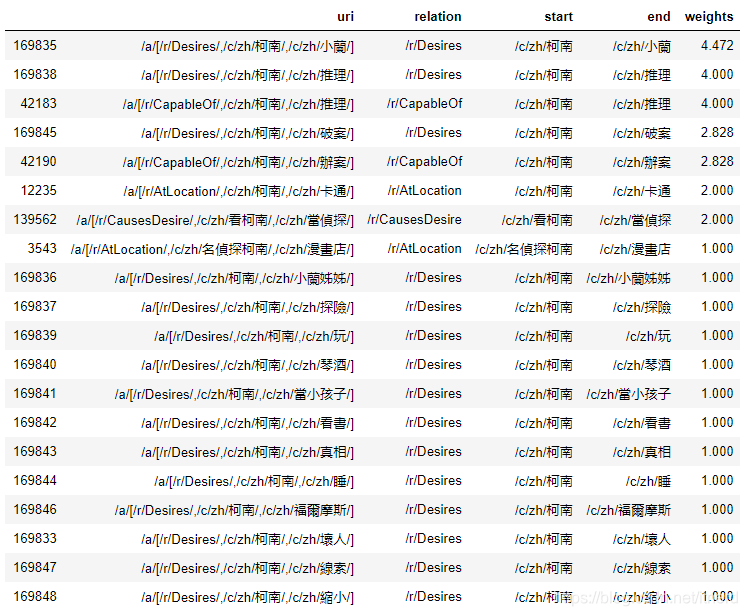
search("柯南")
格式化输出结果
template = {
'/r/RelatedTo':'和{}相关',
'/r/FormOf':'的形式为{}',
'/r/IsA':'是{}',
'/r/PartOf':'是{}的一部分',
'/r/HasA':'具有{}',
'/r/UsedFor':'用来{}',
'/r/CapableOf':'可以{}',
'/r/AtLocation':'在{}',
'/r/Causes':'导致{}',
'/r/HasSubevent':',接下来,{}',
'/r/HasFirstSubevent':',紧接着,{}',
'/r/HasLastSubevent':'的最后一步是{}',
'/r/HasPrerequisite':'的前提为{}',
'/r/HasProperty':'具有{}的属性',
'/r/MotivatedByGoal':'受到{}的驱动',
'/r/ObstructedBy':'受到{}的影响',
'/r/Desires':'想要{}',
'/r/CreatedBy':'被{}创造',
'/r/Synonym':'和{}同义',
'/r/Antonym':'和{}反义',
'/r/DistinctFrom':'和{}相区别',
'/r/DerivedFrom':'由{}导致',
'/r/SymbolOf':'象征着{}',
'/r/DefinedAs':'定义为{}',
'/r/MannerOf':'',
'/r/LocatedNear':'和{}相邻',
'/r/HasContext':'的背景是{}',
'/r/SimilarTo':'和{}相似',
'/r/EtymologicallyRelatedTo':'',
'/r/EtymologicallyDerivedFrom':'',
'/r/CausesDesire':'',
'/r/MadeOf':'由{}制成',
'/r/ReceivesAction':'',
'/r/ExternalURL':''
}
def strip(str):
return str.split('/')[3]
案例:柯南
topK_result = search("柯南",20)
for i in topK_result.index:
i = topK_result.loc[i]
if len(template[i['relation']]) > 0:
print(strip(i['start'])+template[i['relation']].format(strip(i['end'])))
'''
柯南想要小蘭
柯南想要推理
柯南可以推理
柯南想要破案
柯南可以辦案
柯南在卡通
名偵探柯南在漫畫店
柯南想要小蘭姊姊
柯南想要探險
柯南想要玩
柯南想要琴酒
柯南想要當小孩子
柯南想要看書
柯南想要真相
柯南想要睡
柯南想要福爾摩斯
柯南想要壞人
柯南想要線索
柯南想要縮小
'''

柯南真刺激


















 7965
7965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











