









编写不易如果觉得不错,麻烦关注一下~
一、WordNet 与Concept Net
(想看Visual Genome请看另一篇文章:
https://blog.csdn.net/u012211422/article/details/114315024?spm=1001.2014.3001.5502)
1.wordnet 非常优质的使用方式:
【1】https://blog.csdn.net/xieyan0811/article/details/82314042
【2】https://blog.csdn.net/weixin_30483495/article/details/96020731
【3】https://www.cnblogs.com/wodexk/p/10292947.html
【4】https://www.cnpython.com/qa/375974
pip install nltk
import nltk
nltk.download('wordnet')
from nltk.corpus import wordnet as wn
print(wn.synsets('published')) # 打印publish的多个词义
dog = wn.synset('dog.n.01') # 狗的概念
print(dog.hypernyms()) # 狗的父类(上位词)
print(dog.hyponyms()) # 狗的子类(下位词)
wn.synset('car.n.01').lemma_names
print(wn.synset('car.n.01').lemma_names())
wn.synset('car.n.01').definition()
wn.synset('car.n.01').examples
![]()
词组可以用_ 横线连接 查询~ So perfect!
2.Concept 数据集可能的正确打开方式,下面过滤的都是英语:
参考链接:
【1】https://blog.csdn.net/zhyacn/article/details/6704340 官网:https://wordnet.princeton.edu/download
【2】https://blog.csdn.net/itnerd/article/details/103478224 https://www.cnblogs.com/TheTai/p/14393737.html
感谢大佬提供的过滤出英文的代码:https://pastebin.com/gPHNnuQ2
"""
1) read & parse in csv
2) filter eng-only & edge weight = 1 assertions
3) save into json format
{"
"""
import csv
import json
import os
def filter_edges(row):
return json.loads(row[-1])["weight"] == 1
def filter_english(row):
return "/en/" in row[2] and "/en/" in row[3]
def find_start_end(row):
start = row.find('/en/') + len('/en/')
end = row.find('/', start)
if end == -1:
end = None
return start, end
def filter_json(filename='assertions.csv'):
with open('assertions.csv') as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
output_dict = dict()
for row in csv_reader:
if filter_edges(row) & filter_english(row):
src_start, src_end = find_start_end(row[2])
source = row[2][src_start:src_end]
target_start, target_end = find_start_end(row[3])
target = row[3][target_start:target_end]
relation = row[1][2:]
meta_data = row[-1]
if relation not in output_dict.keys():
output_dict[relation] = dict()
output_dict[relation][str((source, target))] = {"source": source, "target": target,
"meta_data": meta_data}
with open("filtered_assertions.json", "w") as write_file:
json.dump(output_dict, write_file)
def filter_csv(filename='assertions.csv', filtered_path='filtered_assertions.csv'):
if os.path.isfile(filtered_path):
os.remove(filtered_path)
with open(filename) as csv_file:
csv_reader = csv.reader(csv_file, delimiter='\t')
row_count = 0
for row in csv_reader:
if filter_edges(row) & filter_english(row):
with open(filtered_path, 'a') as filtered_file:
csv_writer = csv.writer(filtered_file, delimiter='\t')
csv_writer.writerow(row)
row_count += 1
# with open("filtered_row_count.txt", 'w') as row_count_file:
# os.write(row_count_file, row_count)
if __name__ == '__main__':
filter_csv('assertions.csv')最后处理成862.16MB
文件内容 如下:


最终共筛选出39个关系及关系下的三元组个数:2848025三元组
Antonym : 12491
AtLocation : 19848
CapableOf : 20074
Causes : 14562
CausesDesire : 4119
CreatedBy : 203
DefinedAs : 1985
DerivedFrom : 300227
Desires : 2662
DistinctFrom : 1034
EtymologicallyDerivedFrom : 71
EtymologicallyRelatedTo : 1
ExternalURL : 57868
FormOf : 353908
HasA : 4956
HasContext : 217569
HasFirstSubevent : 3085
HasLastSubevent : 2586
HasPrerequisite : 19190
HasProperty : 7603
HasSubevent : 21815
InstanceOf : 2
IsA : 117469
LocatedNear : 47
MadeOf : 440
MannerOf : 13
MotivatedByGoal : 8378
NotCapableOf : 300
NotDesires : 2496
NotHasProperty : 314
PartOf : 2004
ReceivesAction : 5704
RelatedTo : 1514896
SimilarTo : 8888
SymbolOf : 4
Synonym : 86744
UsedFor : 34467
dbpedia/genre : 1
dbpedia/influencedBy : 1
二、分词小助手
1.在一个单词里进行分割,其实可以看作一堆单词没有空格的情况,进行分割~(参考连接:https://blog.csdn.net/herosunly/article/details/105513582) 该库github代码连接(https://github.com/mammothb/symspellpy/tree/v6.5.2)
import pkg_resources
from symspellpy.symspellpy import SymSpell
sym_spell = SymSpell(max_dictionary_edit_distance=0, prefix_length=7)
dictionary_path = pkg_resources.resource_filename(
"symspellpy", "frequency_dictionary_en_82_765.txt")
sym_spell.load_dictionary(dictionary_path, term_index=0, count_index=1)
# a long long sentence
input_term = "thequickbrownfoxjumpsoverthelazydog"
result = sym_spell.word_segmentation(input_term)
print("{}, {}, {}".format(result.corrected_string, result.distance_sum,
result.log_prob_sum))
![]()
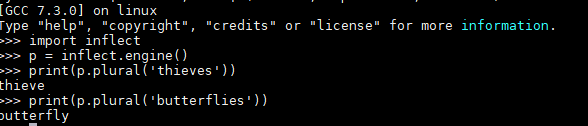
2.进行单词的各种形式转换(想看看是否能查到任意单词的最初原形)
NAME
inflect.py - Correctly generate plurals, singular nouns, ordinals, indefinite articles; convert numbers to words.
pip install inflect
很多例子参看官网: https://pypi.org/project/inflect/
下面列出我关心的需求:(题外话,前面还以为只有pattern 库可以,发现inflect 也可以还方便python3)
3.找出所有名词
import nltk
nltk.download('punkt')
from nltk import word_tokenize, pos_tag
s = "this is my problem , i need help for a function like this one "
nouns = [(word,pos) for word, pos in pos_tag(word_tokenize(s)) if pos.startswith('NN')]
print(nouns)
nouns_part = []
for i in range(len(nouns)):
nouns_part.append(nouns[i][0])
print(nouns)
![]()
![]()
4.词形还原
https://blog.csdn.net/jclian91/articl
from nltk.stem import WordNetLemmatizer
wnl = WordNetLemmatizer()
print(wnl.lemmatize('cars', 'n'))
print(wnl.lemmatize('men', 'n'))
print(wnl.lemmatize('running', 'v'))
print(wnl.lemmatize('ate', 'v'))
print(wnl.lemmatize('saddest', 'a'))
print(wnl.lemmatize('fancier', 'a'))
















 6781
6781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









