









一、下载hadoop
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/hadoop-3.3.6/二、配置环境变量
1、配置java环境变量
2、配置hadoop环境变量
export HADOOP_HOME=/usr/local/bigdata/hadoop-3.3.6
export HBASE_HOME=/usr/local/bigdata/hbase-2.5.6
export JAVA_HOME=/usr/local/jdk-11
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=.:$JAVA_HOME/bin:$HBASE_HOME/bin:$HADOOP_HOME/bin:$PATH
3、配置host
192.168.42.142 node4
三、修改hadoop对应的配置文件
3.1、在hadoop目录下创建目录
mkdir logs mkdir datamkdir -p data/namenode/mkdir -p data/datanodemkdir -p data/tmp
3.2、修改hadoop-env.sh
进入etc/hadoop目录下,修改hadoop-env.sh文件
export JAVA_HOME=/usr/local/jdk-11/
export HADOOP_HOME=/usr/local/bigdata/hadoop-3.3.6
3.3、修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node4</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/bigdata/hadoop-3.3.6/etc/hadoop:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/common/lib/*:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/common/*:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/hdfs:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/hdfs/lib/*:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/hdfs/*:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/mapreduce/*:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/yarn:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/yarn/lib/*:/usr/local/bigdata/hadoop-3.3.6/share/hadoop/yarn/*</value>
</property>
3.4、修改 hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>//usr/local/bigdata/hadoop-3.3.6/data/namenode</value> //注意前面部分路径修改为自己的
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>//usr/local/bigdata/hadoop-3.3.6/data/datanode</value> //注意前面部分路径修改为自己的
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.umaskmode</name>
<value>022</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.acls.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.xattrs.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>http://node4:9870</value>
</property>
3.5、修改mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.6、修改core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>//usr/local/bigdata/hadoop-3.3.6/data/tmp</value> //注意前面部分路径修改为自己的
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node4:9000</value>
</property>
<property>
<name>hadoop.http.authentication.simple.anonymous.allowed</name>
<value>true</value>
</property>
<property>
<name>hadoop.proxyuser.hwf.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hwf.groups</name>
<value>*</value>
</property>
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
3.7、在start-dfs.sh,stop-dfs.sh 文件中增加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3.8、在start-yarn.sh 和stop-yarn.sh 中增加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=root
YARN_NODEMANAGER_USER=root
注意:这里是测试环境,所以直接用root,生产需要创建对应的用户和用户组
四、格式化文件
输入hdfs namenode -format格式化
hdfs namenode -format2023-11-09 22:48:25,218 INFO namenode.FSDirectory: XATTR serial map: bits=24 maxEntries=16777215
2023-11-09 22:48:25,229 INFO util.GSet: Computing capacity for map INodeMap
2023-11-09 22:48:25,229 INFO util.GSet: VM type = 64-bit
2023-11-09 22:48:25,229 INFO util.GSet: 1.0% max memory 944 MB = 9.4 MB
2023-11-09 22:48:25,229 INFO util.GSet: capacity = 2^20 = 1048576 entries
2023-11-09 22:48:25,230 INFO namenode.FSDirectory: ACLs enabled? false
2023-11-09 22:48:25,230 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2023-11-09 22:48:25,230 INFO namenode.FSDirectory: XAttrs enabled? false
2023-11-09 22:48:25,231 INFO namenode.NameNode: Caching file names occurring more than 10 times
2023-11-09 22:48:25,235 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2023-11-09 22:48:25,236 INFO snapshot.SnapshotManager: SkipList is disabled
2023-11-09 22:48:25,239 INFO util.GSet: Computing capacity for map cachedBlocks
2023-11-09 22:48:25,239 INFO util.GSet: VM type = 64-bit
2023-11-09 22:48:25,239 INFO util.GSet: 0.25% max memory 944 MB = 2.4 MB
2023-11-09 22:48:25,239 INFO util.GSet: capacity = 2^18 = 262144 entries
2023-11-09 22:48:25,244 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2023-11-09 22:48:25,244 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2023-11-09 22:48:25,245 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2023-11-09 22:48:25,247 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2023-11-09 22:48:25,247 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2023-11-09 22:48:25,248 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2023-11-09 22:48:25,248 INFO util.GSet: VM type = 64-bit
2023-11-09 22:48:25,248 INFO util.GSet: 0.029999999329447746% max memory 944 MB = 290.0 KB
2023-11-09 22:48:25,248 INFO util.GSet: capacity = 2^15 = 32768 entries
Re-format filesystem in Storage Directory root= /usr/local/bigdata/hadoop-3.3.6/data/namenode; location= null ? (Y or N) Y
2023-11-09 22:48:27,082 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1461429317-192.168.42.142-1699541307072
2023-11-09 22:48:27,082 INFO common.Storage: Will remove files: [/usr/local/bigdata/hadoop-3.3.6/data/namenode/current/VERSION, /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/seen_txid, /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage_0000000000000000000.md5, /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage_0000000000000000000]
2023-11-09 22:48:27,093 INFO common.Storage: Storage directory /usr/local/bigdata/hadoop-3.3.6/data/namenode has been successfully formatted.
2023-11-09 22:48:27,129 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
2023-11-09 22:48:27,198 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/bigdata/hadoop-3.3.6/data/namenode/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2023-11-09 22:48:27,206 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-11-09 22:48:27,222 INFO namenode.FSNamesystem: Stopping services started for active state
2023-11-09 22:48:27,222 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-11-09 22:48:27,228 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-11-09 22:48:27,229 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node4/192.168.42.142
************************************************************/
五、启动hadoop单机版
进入sbin目录下输入./start-all.sh
[root@node4 sbin]# ./start-all.sh
Starting namenodes on [node4]
上一次登录:四 11月 9 22:21:08 CST 2023pts/0 上
Starting datanodes
上一次登录:四 11月 9 22:22:49 CST 2023pts/0 上
Starting secondary namenodes [node4]
上一次登录:四 11月 9 22:22:51 CST 2023pts/0 上
Starting resourcemanager
上一次登录:四 11月 9 22:22:55 CST 2023pts/0 上
Starting nodemanagers
上一次登录:四 11月 9 22:23:00 CST 2023pts/0 上
六、查看启动界面
http://192.168.42.142:8088/
http://192.168.42.142:9870/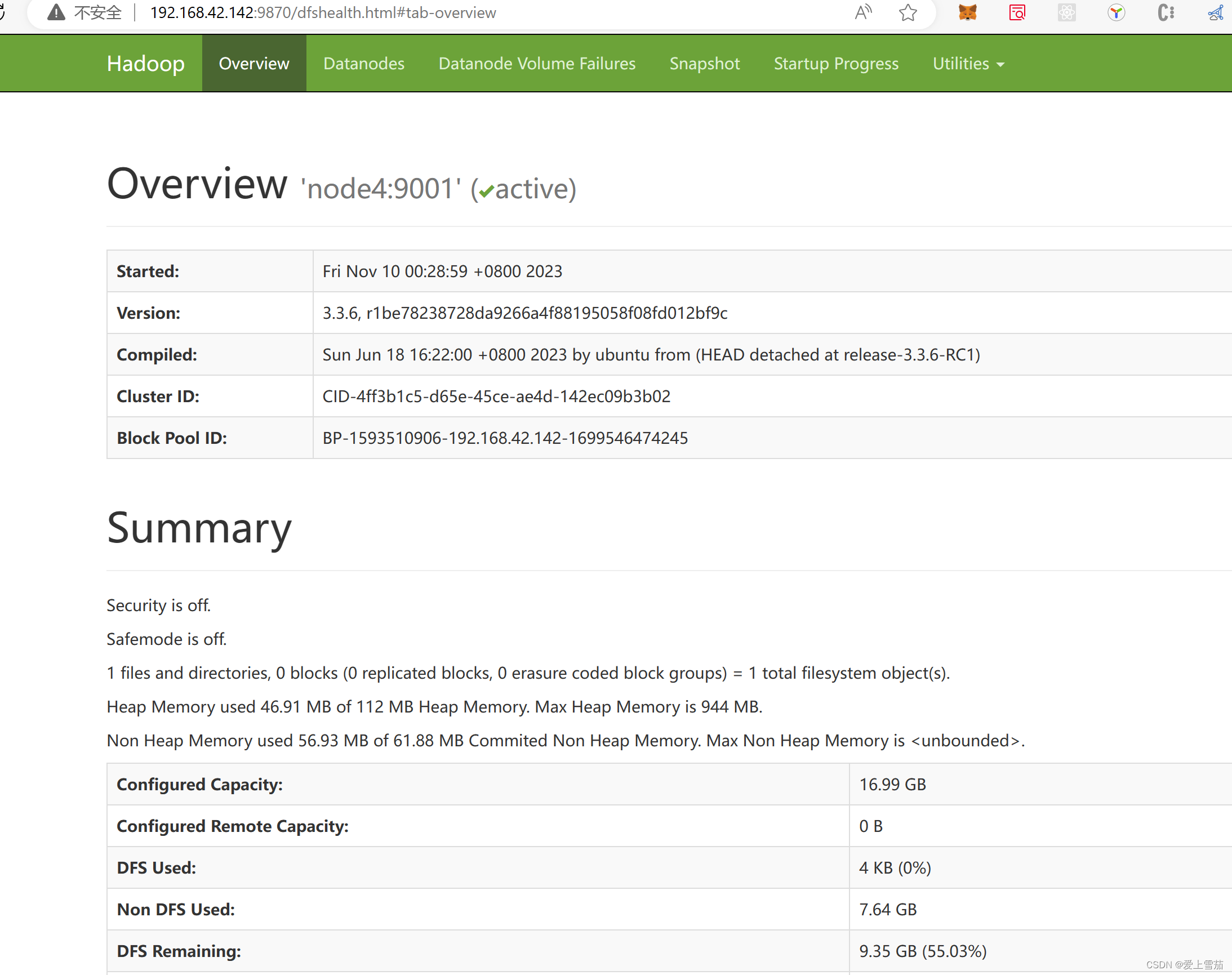














 6025
6025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









