







1.1 、ElasticSearch(简称ES)
1.2、应用场景:


1.3、ES核心是Lucene——ElasticSearch与Lucene的关系
ES的底层使用的还是Lucene。
1.4、 ES vs Solr比较
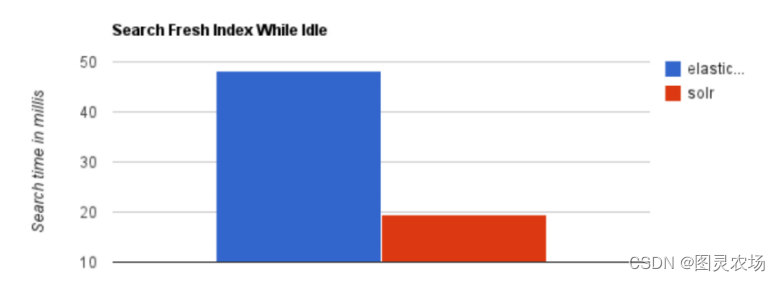
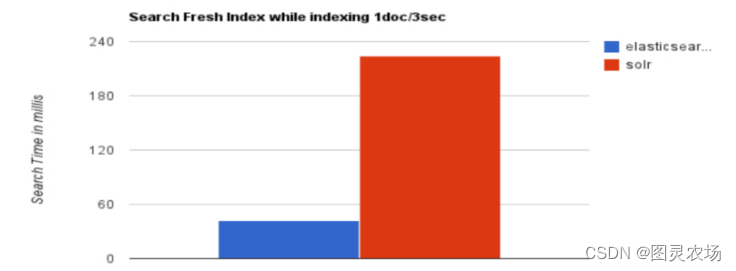
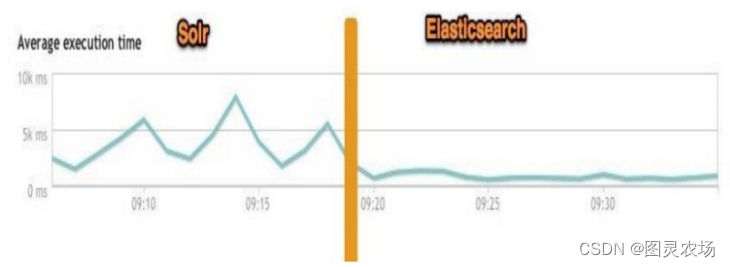
1.5、ES 与关系型数据库 类比
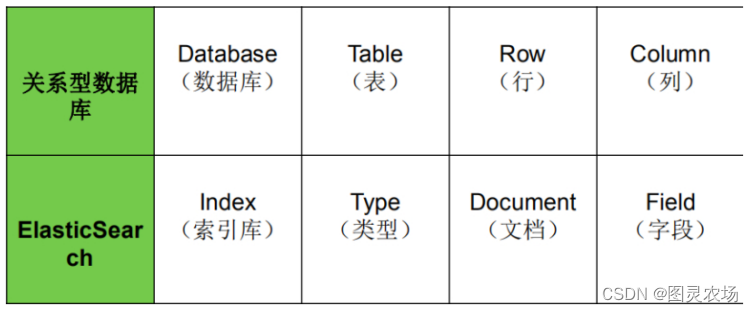
关系型数据库里一行代表一条记录,ES里一个Document代表一条记录。(JSON结构数据)
ES的客户端常用Kibana,参考Kibana是什么,干什么用?详细入门教程_qiandeqiande的博客-CSDN博客_kibana
2.1、Lucene全文检索框架
2.2、分词原理之倒排索引

比方上面三条数据,index对应123,分词记录每个词在哪个index里存在。最后对这个存在进行去重排序保存。

倒排列表里:这个词在第几条数据中存在,并且存在几个。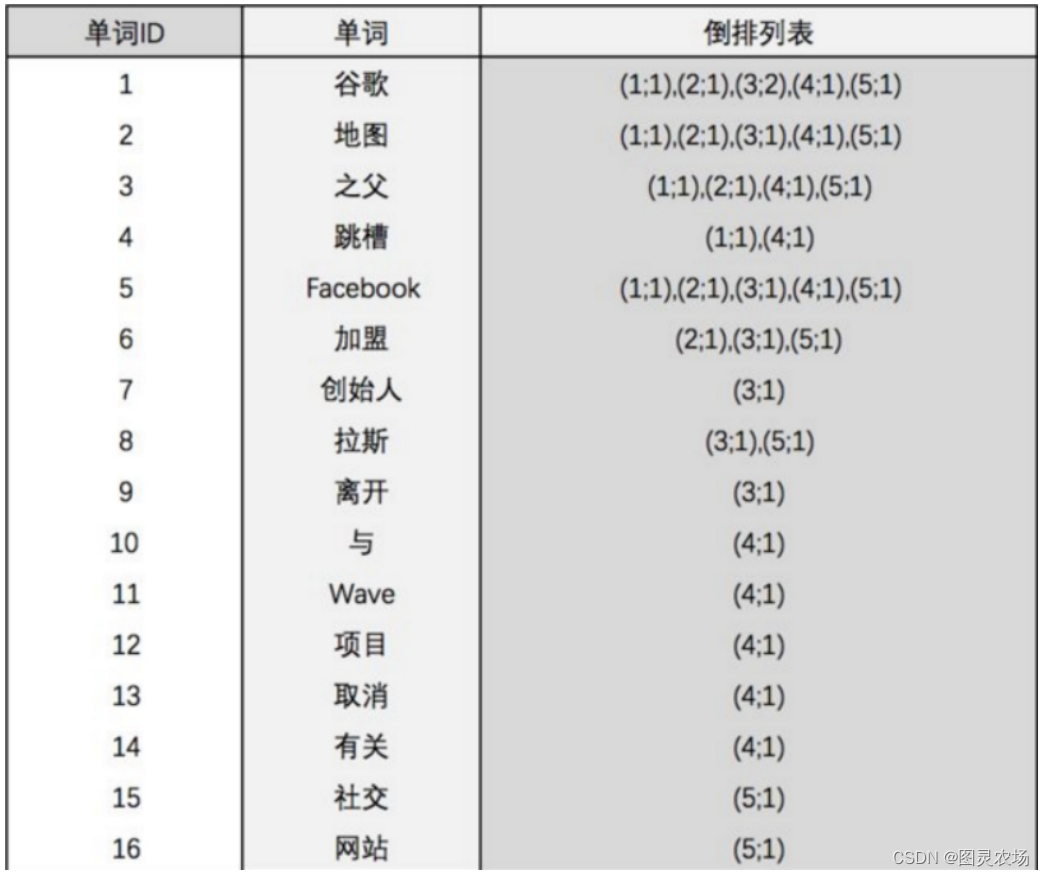
倒排索引总结:
索引就类似于目录,平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引呢,刚好相反,数据对应到主键.这里以一个博客文章的内容为例:
1.索引(正排索引)
| 文章ID | 文章标题 | 文章内容 |
| 1 | 浅析JAVA设计模式 | JAVA设计模式是每一个JAVA程序员都应该掌握的进阶知识 |
| 2 | JAVA多线程设计模式 | JAVA多线程与设计模式结合 |
2.倒排索引(基于正排索引)
假如,我们有一个站内搜索的功能,通过某个关键词来搜索相关的文章,那么这个关键词可能出现在标题中,也可能出现在文章内容中,那我们将会在创建或修改文章的时候,建立一个关键词与文章的对应关系表,这种,我们可以称之为倒排索引,因此倒排索引,也可称之为反向索引.如:
| 关键词 | 文章ID |
| JAVA | 1 |
| 设计模式 | 1,2 |
| 多线程 | 2 |
注:这里涉及中文分词的问题
3. Elasticsearch中的核心概念
3.1 索引 index
3.2 映射 mapping
3.3 字段Field
3.4 字段类型 Type
3.5 文档 document
3.6 集群 cluster
3.7 节点 node
3.8 分片和副本 shards&replicas
3.8.1 分片
3.8.2 副本
4、安装Elasticsearch及使用
4.1、 创建普通用户
先创建组, 再创建用户:
1)创建 elasticsearch 用户组
[root@localhost ~]# groupadd elasticsearch
2)创建用户 tlbaiqi 并设置密码
[root@localhost ~]# useradd tlbaiqi
[root@localhost ~]# passwd tlbaiqi
3)# 创建es文件夹,
并修改owner为baiqi用户
mkdir -p /usr/local/es
4)用户es 添加到 elasticsearch 用户组
[root@localhost ~]# usermod -G elasticsearch tlbaiqi
[root@localhost ~]# chown -R tlbaiqi /usr/local/es/elasticsearch-7.6.1
5)设置sudo权限
#为了让普通用户有更大的操作权限,我们一般都会给普通用户设置sudo权限,方便普通用户的操作
#三台机器使用root用户执行visudo命令然后为es用户添加权限
[root@localhost ~]# visudo
#在root ALL=(ALL) ALL 一行下面
#添加tlbaiqi用户 如下:
tlbaiqi ALL=(ALL) ALL
#添加成功保存后切换到tlbaiqi用户操作
[root@localhost ~]# su tlbaiqi
[tlbaiqi@localhost root]$4.2 、上传压缩包并解压
# 解压Elasticsearch
su tlbaiqi
cd /user/local/
tar -zvxf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/es/4.3 、修改配置文件
cd /usr/local/es/elasticsearch-7.6.1/config
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
rm -rf elasticsearch.yml
vim elasticsearch.yml
cluster.name: baiqi-es
node.name: node1
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["服务器IP"]
cluster.initial_master_nodes: ["节点名"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"cd /usr/local/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g4.4、修改系统配置,解决启动时候的问题
4.4.1、普通用户打开文件的最大数限制
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096此文件修改后需要重新登录用户,才会生效
4.4.2、普通用户启动线程数限制
Centos6
sudo vi /etc/security/limits.d/90-nproc.conf
Centos7
sudo vi /etc/security/limits.d/20-nproc.conf找到如下内容:
* soft nproc 1024#修改为
* soft nproc 40964.4.3、普通用户调大虚拟内存
编辑 /etc/sysctl.conf,追加以下内容:vm.max_map_count=262144 保存后,执行:sysctl -p4.5、启动ES服务
# cd /usr/local/es/elasticsearch‐7.6.1
# ./bin/elasticsearch -d
5、 客户端Kibana安装
6、安装IK分词器
7、指定IK分词器作为默认分词器
ik_smart会将“清华大学”整个分为一个词,而ik_max_word会将“清华大学”分为“清华大学”,“清华”和“大学”,按需选其中之一就可以了。
8.ES数据管理
8.1 ES数据管理概述
8.2 基本操作
注意:POST和PUT都能起到创建/更新的作用
1、需要注意的是==PUT==需要对一个具体的资源进行操作也就是要确定id才能进行==更新/创建,而==POST==是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行==创建==新文档,如果填了id那就针对这个id的文档进行创建/更新
2、PUT只会将json数据都进行替换, POST只会更新相同字段的值
3、PUT与DELETE都是幂等性操作, 即不论操作多少次, 结果都一样。















 3398
3398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









