







MapReduce的工作机制
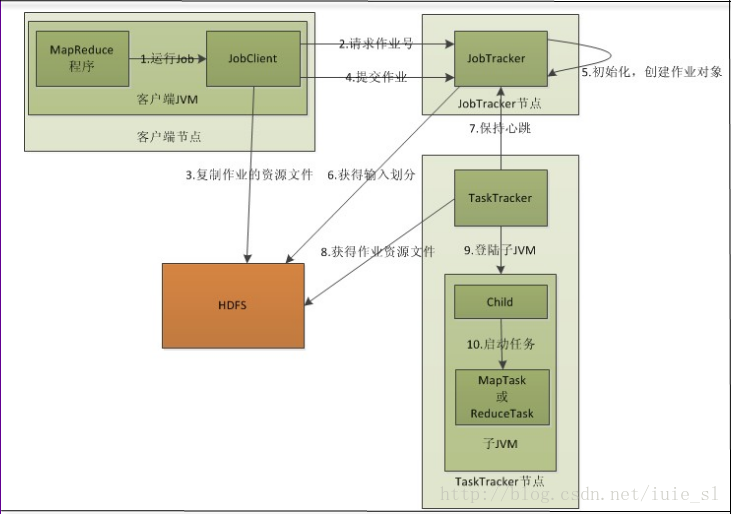
简单分为3部
1)MapReduce作业的提交
- 客户端进行编码运行后,客户端会先向JobTracker请求一个Job ID
- 请求后JobTracker会创建这个Job id,检查job的输入输出目录,检查分片情况,如果出现异常将停止运行抛出异常,
- JobClient将运行作业所需要的资源(Jar文件,配置文件和计算所得输入分片)复制到一个作业ID命名的目录下JobTracker的文件系统中。作业Jar的副本默认为10
- 客户端获取到Job id后开始作业提交
2)初始化作业
- JobTracker接收到提交的作业后,会将作业放在一个队列上,交给作业调度器调度。默认的是JobQueueuTaskScheduler,就是FIFO模式,也可以自己设置抢占模式。
- 重hdfs获取jobClient已经计算好的输入分片信息,为每个分片创建一个map任务,创建reduce任务
3)分配任务
- TaskTracker和JobTracker之间的通行主要由心跳检测来完成。TaskTracker每隔一段时间向JobTracker发送心跳,并且告诉自己任务的状态需不需要分配新的任务,如果TaskTracker需要分配新的任务,JobTracker通过响应将任务返回给TaskTracker
- JobTracker为TaskTracker分配任务时考虑到网络宽带会将map任务数据本地化,他会根据TaskTracker的网络位置选取一个距离这个TaskTracker map任务最近的的文件划分给TaskTracker.
- 对于map,reduce任务,TaskTracker有固定数量的任务槽,获得新的任务时会将新任务放在任务槽中。
4)执行任务
- 通过分布式文件系统将作业的JAR文件复制到TaskTracker所在的文件系统,实现作业JAR文件本地化,
同时将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。 - TaskTracker为任务新建一个本地工作目录,并把JAR文件中的内容解压到这个文件夹下。
- TaskTracker新建一个TaskRunner实例来运行该任务。
TaskRunner启动一个新的JVM来运行每个任务,以便用户定义的map和reduce函数不会影响到TaskTracker实例。不同的任务之间可以重用JVM。子进程通过umbilical接口与父进程进行通信。任务的子进程每隔几秒便告知父进程它的进度,直到任务完成
hdfs
分布式文件系统
特点:处理超大文件
流式的访问数据:读取整个数据集比读取一条记录的效率高
- 运行于廉价的商用机器集群上
- 不适合低延迟数据访问
- 无法高效存储大量小文件
不支持多用户写入及任意修改文件,只能追加不能插入
概念
块:文件块,表示系统读写可操作的最小文件大小,默认是64M,文件被划分块存储,是文件储存处理的逻辑单元,
- NameNode:是Master管理集群中的执行调度,管理文件系统的命名空间,维护整个文件系统的文件目录树及其这些文件的索引目录。重NameNode中可以获得每个文件块所在的DataNode信息。
- DataNode: 是Worker具体任务的执行节点,用来执行任务,储存文件块。通过心跳定时向NameNode发送多存储的文件块信息。
hdfs的读写
度:
客户端调用FileSystem对象中的open()来读取他需要的数据。
FileSystem是HDFS中DistributedFileSystem的一个实例,DistributedFileSystem会通过RPC协议调用NameNode来确定请求文件块所在的位置NameNode只会返回所调用文件块中开始的几个块,而不是全部返回,根据返回的DataNode按照距离客户端的距离排序,
DistributedFileSystem
会向客户端返回一个支持文件定位的输入流对象FSDataInputStream,用于给客户端读取数据。FSDataInputStream包含一个DFSInputStream对象,用于管理DataNode和NameNode之间的I/O客户端会在这个流之上调用read()函数。
一个DataNode读取后他会寻找最近的DataNode,直到客户端完成所有文件的读取,就调用close函数
写
客户端通过调用DistributedFileSystem对象中的ctreat()函数创建一个文件.
NameNode会保证文件在文件系统中不存在,如果创建成功DistributedFileSystem返回一个FSDataInputStream给客户端用来写入数据,FSDataInputStream包含DFSOutputStream,客户端使用它来处理DataNode和NameNode之间的通行
在写入数据时FSDataInputStream会将文件分割成包,然后放入一个队列中.
DataStreamer请求NameNode会DataNode分配副本,DataStreamer然后以流的形式传送给队列中的第一个DataNode,DataNode存储,在推送到第二个DataNode,直到最后一个
FSDataInputStream也会维护一个队列用来确定写入是否成功。
hdfs web界面:
http://NameNodeIP:50070















 2190
2190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









