






本文讲解版本截止到FlinkCDC 2.2
一、概述
1.1 FlinkCDC 简介
Flink CDC (Flink Change Data Capture) 是基于数据库的日志 CDC 技术,实现了全增量一体化读取的数据集成框架。搭配Flink计算框架,Flink CDC 可以高效实现海量数据的实时集成。

1.2 什么是CDC技术
1.2.1 简介
CDC是Change Data Capture(变更数据捕获)的简称。其核心原理是监测并捕获数据库的变动(增删改等),将这些变更按发生的顺序捕获,将捕获到的数据数据仓库或者数据湖,也可以写入到消息队列(例如kafka)供其他服务消费。
1.2.2 机制
实现CDC即捕获数据库的变更数据有两种机制:
- 基于查询的 CDC:
-
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
- 基于日志的 CDC:
-
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
| 比较项 | 基于查询实现CDC | 基于日志实现CDC |
| 典型产品 | Sqoop、DataX等 | Canal、Debezium等 |
| 执⾏模式 | 批处理 | 流处理 |
| 捕获所有数据变化 | NO | YES |
| 低延迟 | NO | YES |
| 不增加数据库负载 | NO | YES |
| 不侵⼊业务(不需要lastUpdate字段) | NO | YES |
| 捕获删除事件 | NO | YES |
| 捕获旧记录的状态 | NO | YES |
1.2.3 常见的CDC方案及比较

1.3 为什么推荐Flink CDC
博主对应1.2.3 中的比较常见的CDC工具大都有过使用经验:
Debezium是国外⽤户常⽤的CDC组件,单机对于分布式来说,在数据读取能力的拓展上,没有分布式的更具有优势,在大数据众多的分布式框架中(Hive、Hudi等)Flink CDC 的架构能够很好地接入这些框架。
DataX无法支持增量同步。如果一张Mysql表每天增量的数据是不同天的数据,并且没有办法确定它的产生时间,那么如何将数据同步到数仓是一个值得考虑的问题。DataX支持全表同步,也支持sql查询的方式导入导出,全量同步一定是不可取的,sql查询的方式没有可以确定增量数据的字段的话也不是一个好的增量数据同步方案。
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。Canal主要支持了MySQL的Binlog解析,将增量数据写入中间件中(例如kafka,Rocket MQ等),但是无法同步历史数据,因为无法获取到binlog的变更。
Sqoop主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递。Sqoop将导入或导出命令翻译成mapreduce程序来实现,这样的弊端就是Sqoop只能做批量导入,遵循事务的一致性,Mapreduce任务成功则同步成功,失败则全部同步失败。
Apache SeaTunnel是一个当前也非常受欢迎的数据集成同步组件。其可以支持全量和增量,支持流批一体。SeaTunnel的使用是非常简单的,零编写代码,只需要写一个配置文件脚本提交命令即可,同时也使用分布式的架构,可以依托于Flink,Spark以及自身的Zeta引擎的分布式完成一个任务在多个节点上运行。其内部也有类似Flink checkpoint的状态保存机制,用于故障恢复,sink阶段的两阶段提交机制也可以做到精准一次性Excatly-once。对于大部分的场景,SeaTunnel都能完美支持,但是SeaTunnel只能支持简单的数据转换逻辑,对于复杂的数据转换场景,还是需要Flink、Spark任务来完成。
Flink CDC 基本都弥补了以上框架的不足,将数据库的全量和增量数据一体化地同步到消息队列和数据仓库中;也可以用于实时数据集成,将数据库数据实时入湖入仓;无需像其他的CDC工具一样需要在服务器上进行部署,减少了维护成本,链路更少;完美套接Flink程序,CDC获取到的数据流直接对接Flink进行数据加工处理,一套代码即可完成对数据的抽取转换和写出,既可以使用flink的DataStream API完成编码,也可以使用较为上层的FlinkSQL API进行操作。
1.4 适用范围
截止到Flink CDC 2.2 为止,支持的连接器:

支持的Flink版本:

二、原理
2.1 Flink CDC 1.x
在 Flink cdc 1.x 版本中,底层选用 debezium 作为采集工具,Debezium 为保证数据一致性,通过对读取的数据库或者表进行加锁,加锁是在全量的时候加锁。
下图是开发者社区的一张全局锁和表锁的过程图
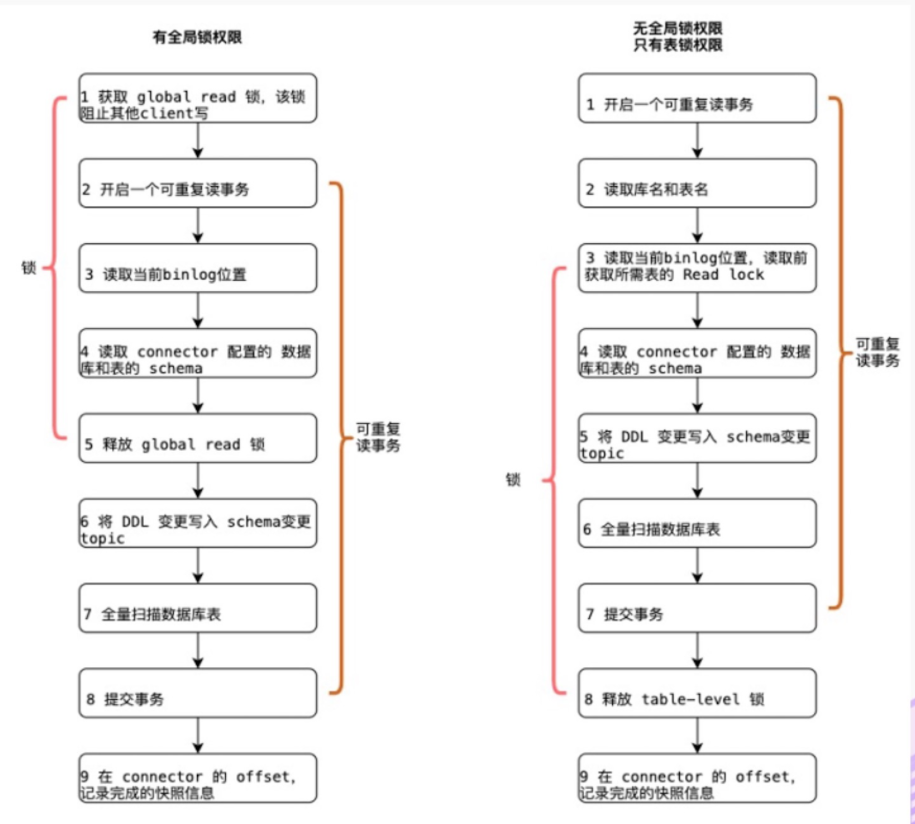
FlinkCDC全量同步时会获取全局读锁,或者表锁。所谓加锁,目的是为了确认Mysql binlog 的起始位置和Mysql 表的Schema,获取到锁后,Mysql所有的ddl,dml操作都会处于wait read lock阶段,如果锁获取时间超时,程序还会抛出异常;而增量同步时,因为是监控binlog的方式,所以对mysql没有影响。
什么是表锁,表锁会自动加锁。查询操作(SELECT),会自动给涉及的所有表加读锁,更新操作(UPDATE、DELETE、INSERT)。如果启动一个CDC任务,而另一个CDC程序也处于初始化阶段,获取不到全局锁,那么那么此程序就会去获取表级锁,表及锁锁的时间会更长,一般是全局读锁的几十倍时长。
Flink CDC 1.x 可以不加锁,能够满足大部分场景,但牺牲了一定的数据准确性。Flink CDC 1.x 默认加全局锁,虽然能保证数据一致性,但存在上述 hang 住数据的风险。
由此可以看来FlinkCDC 1.x 存在着一些不足:
1.由于其锁机制,全量同步阶段之有一个任务在进行同步,不支持并发同步,数据传输会比较慢。
2.锁表时会阻止其他事务提交。
3.不支持断点续传,如果在同步过程中,出现mysql连接超时,或者flink程序快照中断,那么我们无法从断开点开始续传,因为目前暂不支持checkpoint。
记住这三个问题,我们接下来看下FlinkCDC 2.x 的版本。
2.2 Flink CDC 2.x
2.2.1 chunk 切分算法
还记得上一章的锁机制吗?我们先来了解下DBlog paper 论文的 chunk 切分算法。
该算法在数据库中维护了一张watermark(信号)表,记录每个chunk块的区间值位点LW和HW。

每个chunk块只负责自己主键范围内的数据,只要保证每个数据块的数据一致,那么所有数据就都一致,这便是无锁算法的基本原理。
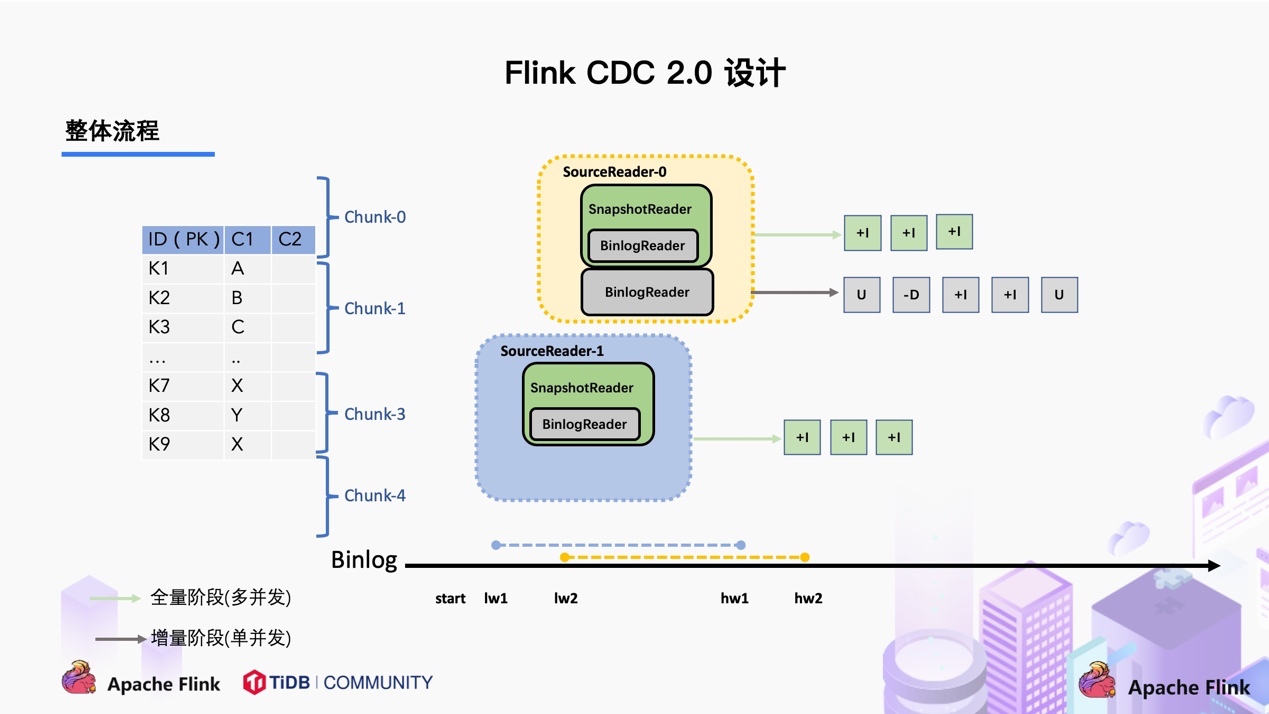
2.2.2 Flink CDC 2.0 设计 ( 以 MySQL 为例)
Flink CDC2.x 并没有维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能。
接下来博主会用自己的语言来解释该设计方案,官方解答请直接访问官网
Flink CDC 2.0 正式发布,详解核心改进-阿里云开发者社区
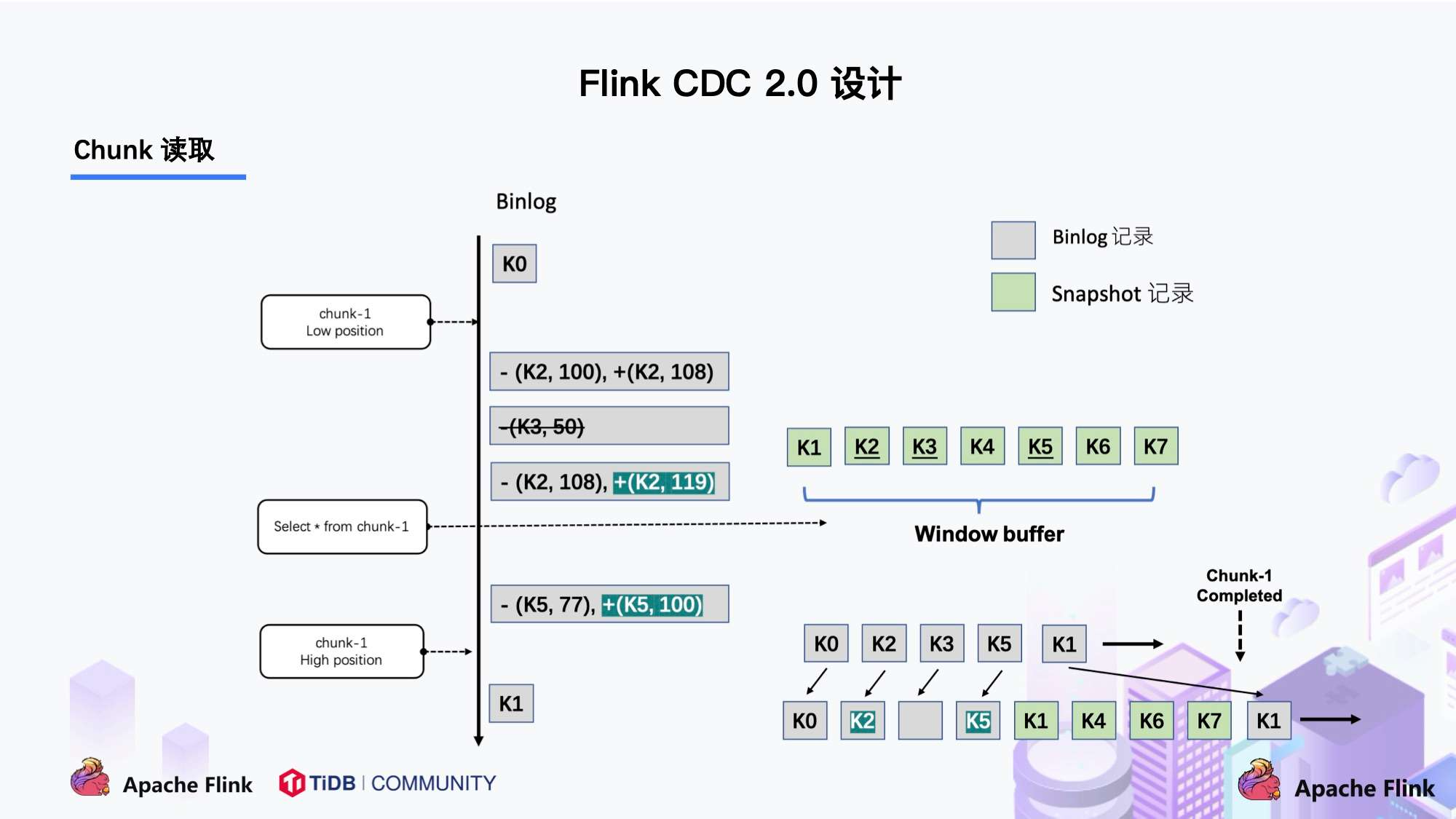
首先,以一个chunk块为例,binlog会捕获到追加,变更以及删除的数据。
上图中:
首先做一个chunk内的快照,里面的数据key为:k1,k2,k3,k4,k5,k6,k7。
没有变更的数据:k1,k4,k6,k7
被修改过的数据:k2,k5
被删除的数据:k3
对于没有改变过的数据k1,k4,k6,k7,可直接将其输出。
对于update过的数据,只保留最终修改后的数据将其输出,即chunk高位点的key数据
对于delete掉的数据,不输出。
上图描述的是单个 Chunk 的一致性读,但是如果有多个表分了很多不同的 Chunk,且这些 Chunk 分发到了不同的 task 中,那么如何分发 Chunk 并保证全局一致性读呢?
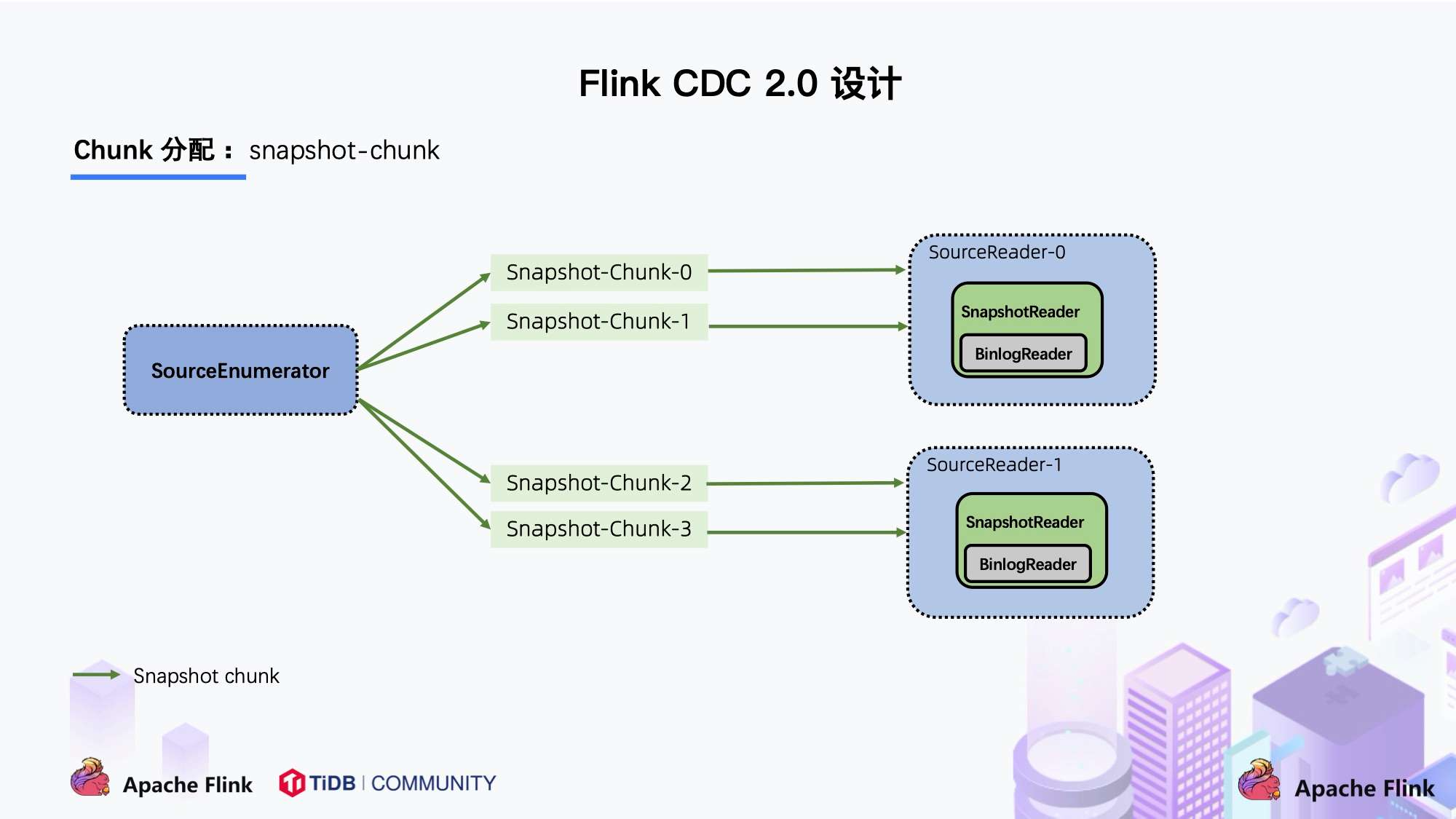
这个就是基于 FLIP-27 来优雅地实现的。图中SourceEnumerator 组件主要用于 Chunk 的划分,划分好的 Chunk 会提供给下游的 SourceReader 去读取,通过把 chunk 分发给不同的 SourceReader 便实现了并发读取 Snapshot Chunk 的过程,同时基于 FLIP-27 我们能较为方便地做到 chunk 粒度的 checkpoint。
当 Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。

汇报的主要目的是为了后续分发 binlog chunk (如下图)。因为 Flink CDC 支持全量 + 增量同步,所以当所有 Snapshot Chunk 读取完成之后,还需要消费增量的 binlog,这是通过下发一个 binlog chunk 给任意一个 Source Reader 进行单并发读取实现的。
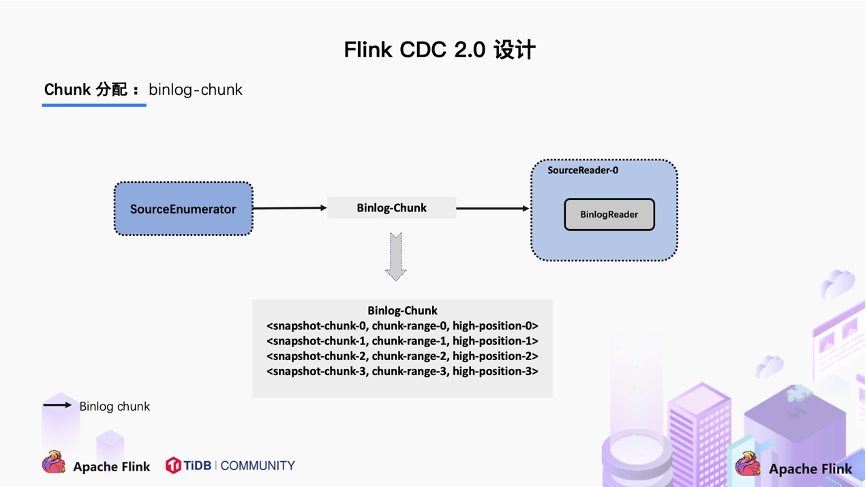
整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有 Snapshot Chunk 读取完成后,下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程,如下图所示:
三、如何使用FlinkCDC
可以使用FlinkSQL API操作,也可以使用DataStream API 进行操作。
3.1 FlinkSQL
3.1.1 FlinksSQL 客户端
所需环境
以Mysql - CDC为例:
(1)配置一个Mysql服务器。
(2)需要Flink集群环境。
(3)下载 flink-sql-connector-mysql-cdc-2.4-SNAPSHOT.jar 到 <FLINK_HOME>/lib/ 目录下。
FlinkSQL客户端:
-- 每 3 秒做一次 checkpoint,用于测试,生产配置建议5到10分钟
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
-- 在 Flink SQL中注册 MySQL 表 'orders' --数据类型与mysql一致
Flink SQL> CREATE TABLE user_info (
user_name STRING,
age INT,
weight DOUBLE,
PRIMARY KEY(user_name) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc', --必填项
'hostname' = 'hadoop102', --必填项
'port' = '3306',
'username' = 'root', --必填项
'password' = '123456', --必填项
'database-name' = 'data_test', --必填项
'table-name' = 'user_info'); --必填项
-- 从订单表读取全量数据(快照)和增量数据(binlog)
Flink SQL> SELECT * FROM orders;FlinkSQL代码:
public class FlinkCDC_mysqlToKafka_Flinksql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);
// 设置状态的TTL 生产环境设置为最大乱序程度
// tableEnvironment.getConfig().setIdleStateRetention(Duration.ofSeconds(905));
tableEnvironment.executeSql("CREATE TABLE user_info_mysql ( " +
" user_name STRING, " +
" age INT, " +
" weight DOUBLE, " +
" PRIMARY KEY(user_name) NOT ENFORCED " +
" ) WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'hostname' = 'hadoop102', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = '123456', " +
" 'database-name' = 'data_test', " +
" 'table-name' = 'user_info')");
//数据处理逻辑
//数据sink连接器选项
| Option | Required | Default | Type | Description |
| connector | required | (none) | String | 指定要使用的连接器, 这里应该是 'mysql-cdc'. |
| hostname | required | (none) | String | MySQL 数据库服务器的 IP 地址或主机名。 |
| username | required | (none) | String | 连接到 MySQL 数据库服务器时要使用的 MySQL 用户的名称。 |
| password | required | (none) | String | 连接 MySQL 数据库服务器时使用的密码。 |
| database-name | required | (none) | String | 要监视的 MySQL 服务器的数据库名称。数据库名称还支持正则表达式,以监视多个与正则表达式匹配的表。 |
| table-name | required | (none) | String | 要监视的 MySQL 数据库的表名。表名还支持正则表达式,以监视多个表与正则表达式匹配。 |
| port | optional | 3306 | Integer | MySQL 数据库服务器的整数端口号。 |
| server-id | optional | (none) | String | 读取数据使用的 server id,server id 可以是个整数或者一个整数范围,比如 '5400' 或 '5400-5408', 建议在 'scan.incremental.snapshot.enabled' 参数为启用时,配置成整数范围。因为在当前 MySQL 集群中运行的所有 slave 节点,标记每个 salve 节点的 id 都必须是唯一的。 所以当连接器加入 MySQL 集群作为另一个 slave 节点(并且具有唯一 id 的情况下),它就可以读取 binlog。 默认情况下,连接器会在 5400 和 6400 之间生成一个随机数,但是我们建议用户明确指定 Server id。 |
| scan.incremental.snapshot.enabled | optional | true | Boolean | 增量快照是一种读取表快照的新机制,与旧的快照机制相比, 增量快照有许多优点,包括: (1)在快照读取期间,Source 支持并发读取, (2)在快照读取期间,Source 支持进行 chunk 粒度的 checkpoint, (3)在快照读取之前,Source 不需要数据库锁权限。 如果希望 Source 并行运行,则每个并行 Readers 都应该具有唯一的 Server id,所以 Server id 必须是类似 `5400-6400` 的范围,并且该范围必须大于并行度。 请查阅 增量快照读取 章节了解更多详细信息。 |
| scan.incremental.snapshot.chunk.size | optional | 8096 | Integer | 表快照的块大小(行数),读取表的快照时,捕获的表被拆分为多个块。 |
| scan.snapshot.fetch.size | optional | 1024 | Integer | 读取表快照时每次读取数据的最大条数。 |
| scan.startup.mode | optional | initial | String | MySQL CDC 消费者可选的启动模式, 合法的模式为 "initial","earliest-offset","latest-offset","specific-offset" 和 "timestamp"。 请查阅 启动模式 章节了解更多详细信息。 |
| scan.startup.specific-offset.file | optional | (none) | String | 在 "specific-offset" 启动模式下,启动位点的 binlog 文件名。 |
| scan.startup.specific-offset.pos | optional | (none) | Long | 在 "specific-offset" 启动模式下,启动位点的 binlog 文件位置。 |
| scan.startup.specific-offset.gtid-set | optional | (none) | String | 在 "specific-offset" 启动模式下,启动位点的 GTID 集合。 |
| scan.startup.specific-offset.skip-events | optional | (none) | Long | 在指定的启动位点后需要跳过的事件数量。 |
| scan.startup.specific-offset.skip-rows | optional | (none) | Long | 在指定的启动位点后需要跳过的数据行数量。 |
| server-time-zone | optional | (none) | String | 数据库服务器中的会话时区, 例如: "Asia/Shanghai". 它控制 MYSQL 中的时间戳类型如何转换为字符串。 更多请参考 这里 . 如果没有设置,则使用ZoneId.systemDefault()来确定服务器时区。 |
| debezium.min.row. count.to.stream.result | optional | 1000 | Integer | 在快照操作期间,连接器将查询每个包含的表,以生成该表中所有行的读取事件。 此参数确定 MySQL 连接是否将表的所有结果拉入内存(速度很快,但需要大量内存), 或者结果是否需要流式传输(传输速度可能较慢,但适用于非常大的表)。 该值指定了在连接器对结果进行流式处理之前,表必须包含的最小行数,默认值为1000。将此参数设置为`0`以跳过所有表大小检查,并始终在快照期间对所有结果进行流式处理。 |
| connect.timeout | optional | 30s | Duration | 连接器在尝试连接到 MySQL 数据库服务器后超时前应等待的最长时间。 |
| connect.max-retries | optional | 3 | Integer | 连接器应重试以建立 MySQL 数据库服务器连接的最大重试次数。 |
| connection.pool.size | optional | 20 | Integer | 连接池大小。 |
| jdbc.properties.* | optional | 20 | String | 传递自定义 JDBC URL 属性的选项。用户可以传递自定义属性,如 'jdbc.properties.useSSL' = 'false'. |
| heartbeat.interval | optional | 30s | Duration | 用于跟踪最新可用 binlog 偏移的发送心跳事件的间隔。 |
| debezium.* | optional | (none) | String | 将 Debezium 的属性传递给 Debezium 嵌入式引擎,该引擎用于从 MySQL 服务器捕获数据更改。 For example: 'debezium.snapshot.mode' = 'never'. 查看更多关于 Debezium 的 MySQL 连接器属性 |
支持的元数据
下表中的元数据可以在 DDL 中作为只读(虚拟)meta 列声明。
| Key | DataType | Description |
| table_name | STRING NOT NULL | 当前记录所属的表名称。 |
| database_name | STRING NOT NULL | 当前记录所属的库名称。 |
| op_ts | TIMESTAMP_LTZ(3) NOT NULL | 当前记录表在数据库中更新的时间。 |
下述创建表示例展示元数据列的用法:
CREATE TABLE products (
db_name STRING METADATA FROM 'database_name' VIRTUAL,
table_name STRING METADATA FROM 'table_name' VIRTUAL,
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL,
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);下述创建表示例展示使用正则表达式匹配多张库表的用法:
CREATE TABLE products (
db_name STRING METADATA FROM 'database_name' VIRTUAL,
table_name STRING METADATA FROM 'table_name' VIRTUAL,
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL,
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = '(^(test).*|^(tpc).*|txc|.*[p$]|t{2})',
'table-name' = '(t[5-8]|tt)'
);| 匹配示例 | 表达式 | 描述 |
| 前缀匹配 | ^(test).* | 匹配前缀为test的数据库名或表名,例如test1、test2等。 |
| 后缀匹配 | .*[p$] | 匹配后缀为p的数据库名或表名,例如cdcp、edcp等。 |
| 特定匹配 | txc | 匹配具体的数据库名或表名。 |
进行库表匹配时,使用的模式是database-name.table-name,所以该例子使用(^(test).*|^(tpc).*|txc|.*[p$]|t{2}).(t[5-8]|tt),匹配txc.tt、test2.test5。
启动模式
配置选项scan.startup.mode指定 MySQL CDC 使用者的启动模式。有效枚举包括:
- initial (默认):在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog。
- earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取
- latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。
- specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。
- timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
例如使用 DataStream API:
MySQLSource.builder()
.startupOptions(StartupOptions.earliest()) // 从最早位点启动
.startupOptions(StartupOptions.latest()) // 从最晚位点启动
.startupOptions(StartupOptions.specificOffset("mysql-bin.000003", 4L) // 从指定 binlog 文件名和位置启动
.startupOptions(StartupOptions.specificOffset("24DA167-0C0C-11E8-8442-00059A3C7B00:1-19")) // 从 GTID 集合启动
.startupOptions(StartupOptions.timestamp(1667232000000L) // 从时间戳启动
...
.build()使用 SQL:
CREATE TABLE mysql_source (...) WITH (
'connector' = 'mysql-cdc',
'scan.startup.mode' = 'earliest-offset', -- 从最早位点启动
'scan.startup.mode' = 'latest-offset', -- 从最晚位点启动
'scan.startup.mode' = 'specific-offset', -- 从特定位点启动
'scan.startup.mode' = 'timestamp', -- 从特定位点启动
'scan.startup.specific-offset.file' = 'mysql-bin.000003', -- 在特定位点启动模式下指定 binlog 文件名
'scan.startup.specific-offset.pos' = '4', -- 在特定位点启动模式下指定 binlog 位置
'scan.startup.specific-offset.gtid-set' = '24DA167-0C0C-11E8-8442-00059A3C7B00:1-19', -- 在特定位点启动模式下指定 GTID 集合
'scan.startup.timestamp-millis' = '1667232000000' -- 在时间戳启动模式下指定启动时间戳
...
)3.2.2 DataStream API
- MySQL source 会在 checkpoint 时将当前位点以 INFO 级别打印到日志中,日志前缀为 “Binlog offset on checkpoint {checkpoint-id}”。 该日志可以帮助将作业从某个 checkpoint 的位点开始启动的场景。
- 如果捕获变更的表曾经发生过表结构变化,从最早位点、特定位点或时间戳启动可能会发生错误,因为 Debezium 读取器会在内部保存当前的最新表结构,结构不匹配的早期数据无法被正确解析。
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".*".
.tableList("yourDatabaseName.yourTableName") // 设置捕获的表
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 3s 的 checkpoint 间隔
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// 设置 source 节点的并行度为 4
.setParallelism(4)
.print().setParallelism(1); // 设置 sink 节点并行度为 1
env.execute("Print MySQL Snapshot + Binlog");
}
}动态加表
扫描新添加的表功能使你可以添加新表到正在运行的作业中,新添加的表将首先读取其快照数据,然后自动读取其变更日志。
想象一下这个场景:一开始, Flink 作业监控表 [product, user, address], 但几天后,我们希望这个作业还可以监控表 [order, custom],这些表包含历史数据,我们需要作业仍然可以复用作业的已有状态,动态加表功能可以优雅地解决此问题。
以下操作显示了如何启用此功能来解决上述场景。 使用现有的 Flink CDC Source 作业,如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.scanNewlyAddedTableEnabled(true) // 启用扫描新添加的表功能
.databaseList("db") // 设置捕获的数据库
.tableList("db.product, db.user, db.address") // 设置捕获的表 [product, user, address]
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.build();
// 你的业务代码如果我们想添加新表 [order, custom] 对于现有的 Flink 作业,只需更新 tableList() 将新增表 [order, custom] 加入并从已有的 savepoint 恢复作业。
Step 1: 使用 savepoint 停止现有的 Flink 作业。
$ ./bin/flink stop $Existing_Flink_JOB_ID
Suspending job "cca7bc1061d61cf15238e92312c2fc20" with a savepoint.
Savepoint completed. Path: file:/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dabStep 2: 更新现有 Flink 作业的表列表选项。
- 更新 tableList() 参数.
- 编译更新后的作业,示例如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.scanNewlyAddedTableEnabled(true)
.databaseList("db")
.tableList("db.product, db.user, db.address, db.order, db.custom") // 设置捕获的表 [product, user, address ,order, custom]
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.build();
// 你的业务代码Step 3: 从 savepoint 还原更新后的 Flink 作业。
$ ./bin/flink run \
--detached \
--fromSavepoint /tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab \
./FlinkCDCExample.jar三、实际使用案例
3.1 FlinkCDC 从mysql读取数据到kafka
3.1.1 准备
-
- Flink集群环境
- kafka开启
- zookeeper开启
- 配置一个Mysql服务器,并将指定库表添加到binlog设置中,这样mysql binlog 就会对指定库表进行监听。
[fallrain@hadoop102 bin]$ sudo vim /etc/my.cnf添加data_test库,对data_test库binlog进行监听。
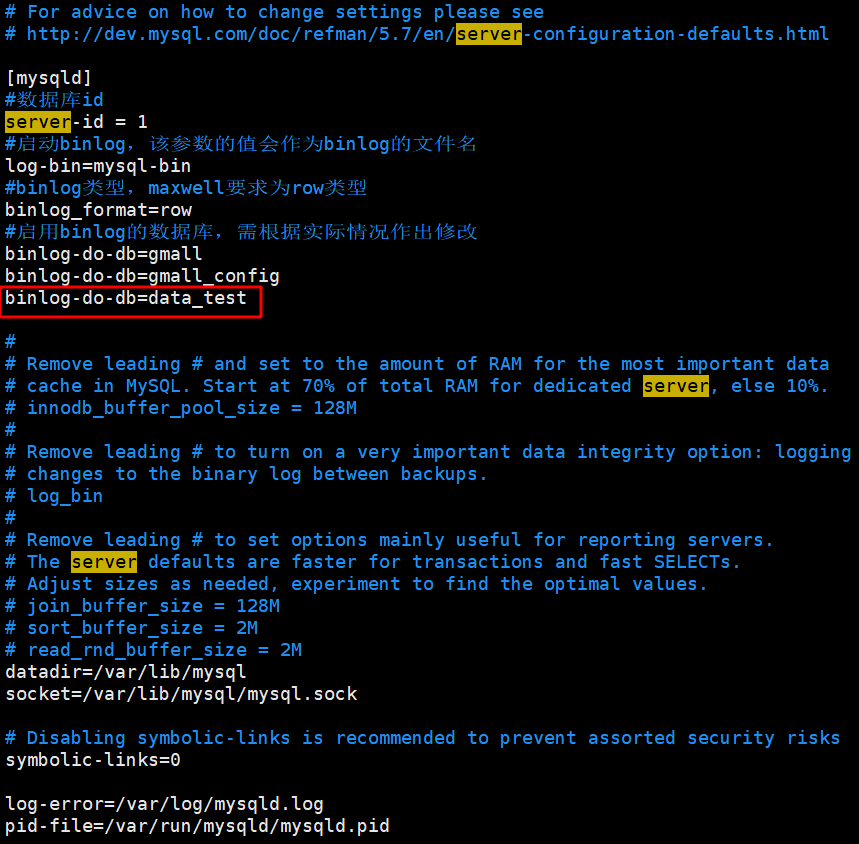
在mysql创建数据库data_test,创建user_info表,设置user_name 作为主键。

3.1.2 测试
pom文件需要添加的依赖:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.1.0</version>
</dependency>
<!-- 如果不引入 flink-table 相关依赖,则会报错:
Caused by: java.lang.ClassNotFoundException:
org.apache.flink.connector.base.source.reader.RecordEmitter
引入如下依赖可以解决这个问题(引入某些其它的 flink-table 相关依赖也可)
-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>代码:
public class FlinkCDC_mysqlToKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
MySqlSource<String> mysqlSource = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("123456")
.databaseList("data_test") //要导哪个数据库
.tableList("data_test.user_info") //要导哪张表中
.startupOptions(StartupOptions.initial()) //从哪里开始读
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
DataStreamSource<String> mysqlSourceDS = env.fromSource(mysqlSource, WatermarkStrategy.noWatermarks(), "MysqlSource");
mysqlSourceDS.print("mysql");
DataStreamSink<String> streamSink = mysqlSourceDS.addSink(FlinkCDC_mysqlToKafka.getKafkaProducer("RookieMaster"))
env.execute();
}
public static FlinkKafkaProducer<String> getKafkaProducer(String topic) {
String kafka_server = "hadoop102:9092";
//三个参数: kafka的节点、topic名称、数据格式
return new FlinkKafkaProducer<String>(kafka_server,topic,new SimpleStringSchema());
}
}开启kafka消费者,观察数据情况
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic RookieMaster初始表
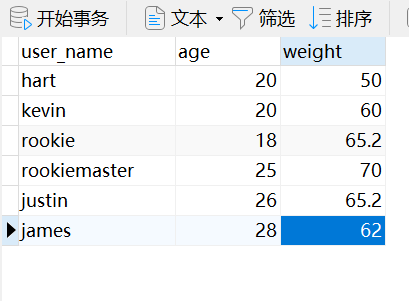
在mysql中添加一条数据
insert into table user_info values("james",28,62.0);
观察一下kafka

在mysql中删除一条数据
kafka中数据变化

在mysql中修改一条数据
update table user_info set age = 20 where user_name = 'rookie';
观察kafka变化情况

3.1.3 FlinkSQL API
用Flinksql 来实现一遍。
import com.atguigu.gmall.realtime.util.FallrainKafkaUtil;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
public class FlinkCDC_mysqlToKafka_Flinksql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);
// 设置状态的TTL 生产环境设置为最大乱序程度
// tableEnvironment.getConfig().setIdleStateRetention(Duration.ofSeconds(905));
tableEnvironment.executeSql("CREATE TABLE user_info_mysql ( " +
" user_name STRING, " +
" age INT, " +
" weight DOUBLE, " +
" PRIMARY KEY(user_name) NOT ENFORCED " +
" ) WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'hostname' = 'hadoop102', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = '970718', " +
" 'database-name' = 'data_test', " +
" 'table-name' = 'user_info')");
tableEnvironment.executeSql("CREATE TABLE user_info_kafka ( " +
" user_name STRING, " +
" age INT, " +
" weight DOUBLE, " +
" PRIMARY KEY(user_name) NOT ENFORCED " +
" ) WITH ( " +
" 'connector' = 'kafka', " +
" 'topic' = 'RookieMaster', " +
" 'properties.bootstrap.servers' = 'hadoop102:9092'," +
// " 'properties.group.id' = 'testGroup'," +
" 'format' = 'debezium-json')");
// tableEnvironment.executeSql("insert into user_info_kafka select * from user_info_mysql");
tableEnvironment.executeSql("insert into user_info_kafka select * from user_info_mysql");
tableEnvironment.sqlQuery("select * from user_info_mysql").execute().print();
}
}注意:如果出现flink mysql cdc 无法监控变动数据的问题,即对数据源进行修改后,下游没有变化,初始数据可以同步,也没有报错。
因为FlinkCDC2.x版本引入了无锁算法,支持并发读取,为了保证全量数据+增量数据的顺序性,依赖flink checkpoint机制,所以作业要配置checkpoint。
env.enableCheckPointing(3000);
或者将并行度设置为1
env.setParallelism(1);
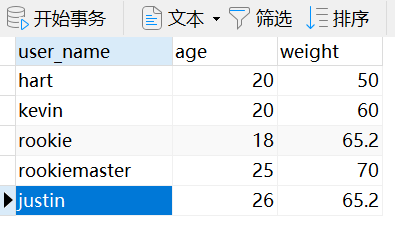
mysql中的数据
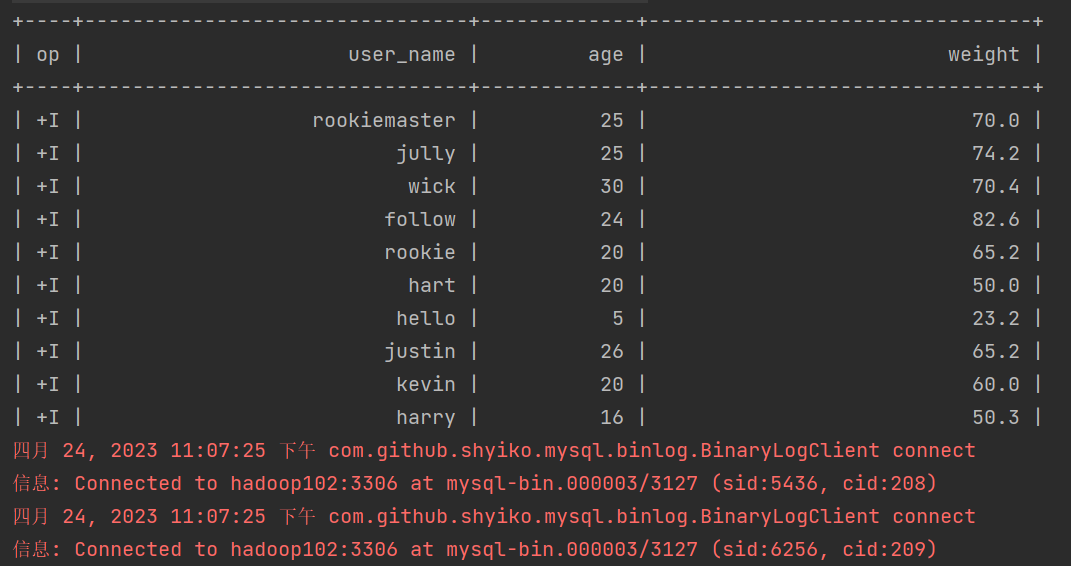
在mysql中添加一条数据
insert into user_info values("john",29,80.5);

观察一下kafka
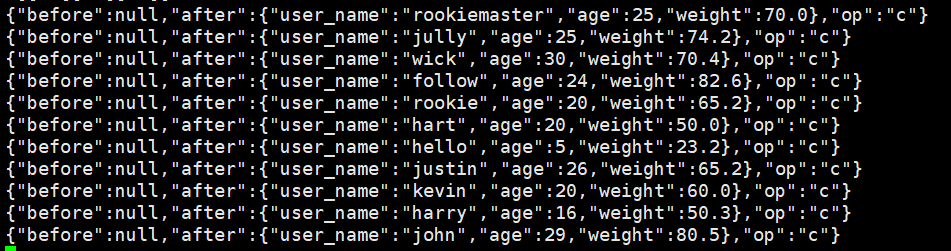
在mysql中修改一条数据
update table user_info set age = 20 where user_name = 'john';
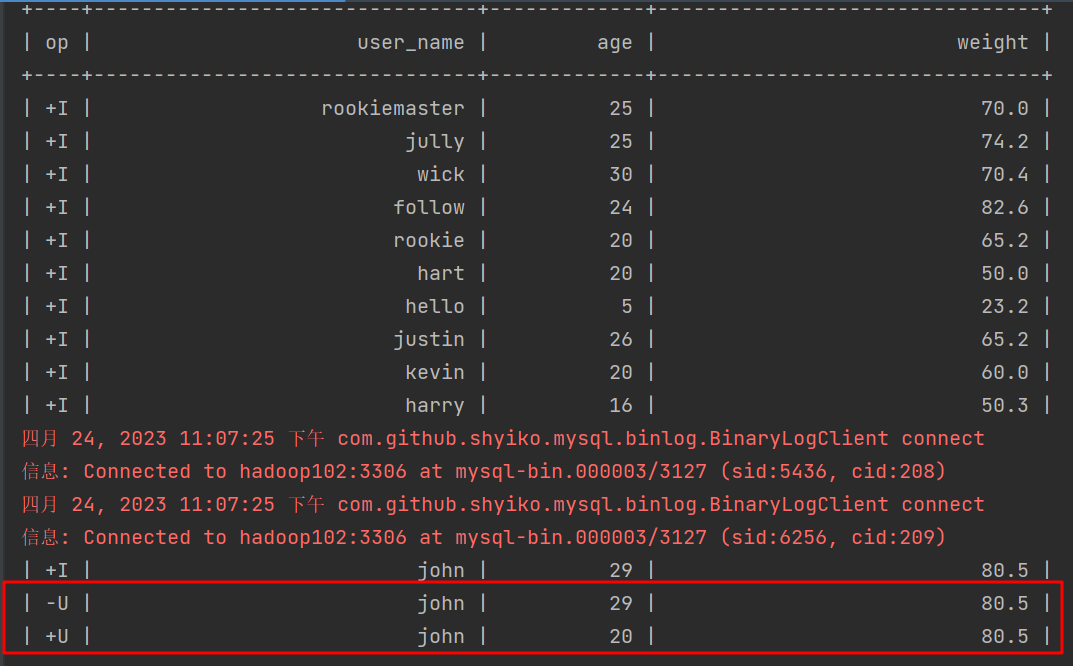
观察一下kafka
删掉了之前那条,又追加了修改后的数据

在mysql中删除一条数据
delete from user_info where user_name = 'john';

观察一下kafka

想关注更多精彩内容 关注公众号大数据菜鸟大师

想与我交流技术 请添加此微信
















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









