







Logistic Regression
Classification and Representation
Classification
下面的视频中,我们将讲到逻辑回归算法
在分类问题中,我们可以使用线性回归的方法,我们将所有预测值限定为0.5到1和0到0.5类。当然,这个方法并不好,因为分类问题并不是线性回归。
分类问题很像是线性回归问题,除了这个我们想要预测的值只是一些少量的离散值。现在,我们将集中处理二进制的分类问题,也就是只有0和1两类的分类问题。
Hypothesis Representation
这个视频中将给出假设函数的表达式。
我们之前使用的是之前讲过的线性回归方法来进行分类,但是分类问题中取值是离散的。所以只有在特殊的例子中才能将值限定到0到1之间,所以我们要对线性回归方法进行改进,下面就是我们的预测函数。
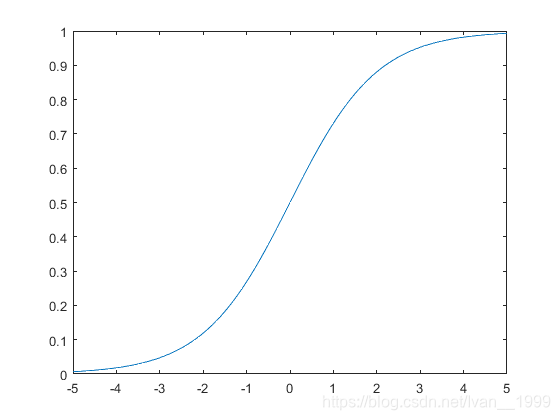
我们的新函数叫做“Sigmoid Function”或者是“Logistic Function”
h
θ
(
x
)
=
g
(
θ
T
x
)
z
=
θ
T
x
g
(
z
)
=
1
1
+
e
−
z
\begin{array}{l} {h_\theta }(x) = g({\theta ^T}x)\\ z = {\theta ^T}x\\ g(z) = \frac{1}{{1 + {e^{ - z}}}} \end{array}
hθ(x)=g(θTx)z=θTxg(z)=1+e−z1
下面是我们的函数图像:
Decision Boundary
这一节中,我们将学到决策变量(Decision Boundary)的概念。
首先我们需要知道的概念;
θ
T
x
≥
0
⇒
y
=
1
θ
T
x
<
0
⇒
y
=
0
\begin{array}{l} {\theta ^T}x \ge 0 \Rightarrow y = 1\\ {\theta ^T}x < 0 \Rightarrow y = 0 \end{array}
θTx≥0⇒y=1θTx<0⇒y=0
所以说,决策变量就是一条用来划分开y=1和y=0的线,当然这条线不一定是直线。
Logistic Regression Model
Cost Function
在这个视频中,我们将学到如何寻找
θ
\theta
θ.
我们不能使用线性回归的代价函数,因为逻辑回归会导致一些局部最优解,也就是说,这不是一个凸函数。
所以,我们的代价函数如下:
J
(
θ
)
=
1
m
∑
i
=
1
m
C
o
s
t
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
−
log
(
h
θ
(
x
)
)
            
i
f
    
y
=
1
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
−
log
(
1
−
h
θ
(
x
)
)
          
i
f
    
y
=
0
\begin{array}{l} J(\theta ) = \frac{1}{m}\sum\limits_{i = 1}^m {Cost({h_\theta }({x^{(i)}}),{y^{(i)}})} \\ Cost({h_\theta }(x),y) = - \log ({h_\theta }(x))\;\;\;\;\;\;if\;\;y = 1\\ Cost({h_\theta }(x),y) = - \log (1 - {h_\theta }(x))\;\;\;\;\;if\;\;y = 0 \end{array}
J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))Cost(hθ(x),y)=−log(hθ(x))ify=1Cost(hθ(x),y)=−log(1−hθ(x))ify=0
现在我们分别画出y=1和y=0时
J
(
θ
)
J(\theta)
J(θ)关于
h
θ
(
x
)
h_\theta(x)
hθ(x)的函数
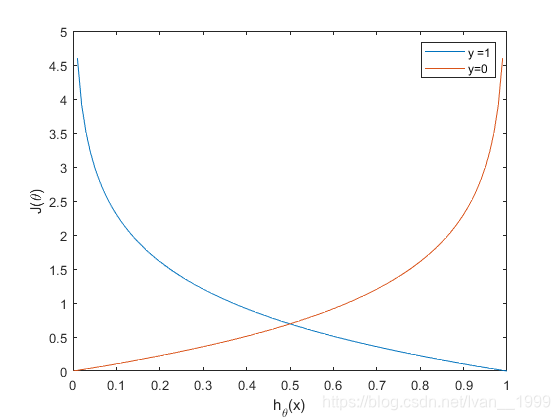
则
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
0
    
i
f
    
h
θ
(
x
)
=
y
C
o
s
t
(
h
θ
(
x
)
,
y
)
→
∞
    
i
f
    
y
=
0
    
a
n
d
    
h
θ
(
x
)
→
1
C
o
s
t
(
h
θ
(
x
)
,
y
)
→
∞
    
i
f
    
y
=
0
    
a
n
d
    
h
θ
(
x
)
→
1
\begin{array}{l} Cost({h_\theta }(x),y) = 0\;\;if\;\;{h_\theta }(x) = y\\ Cost({h_\theta }(x),y) \to \infty \;\;if\;\;y = 0\;\;and\;\;{h_\theta }(x) \to 1\\ Cost({h_\theta }(x),y) \to \infty \;\;if\;\;y = 0\;\;and\;\;{h_\theta }(x) \to 1 \end{array}
Cost(hθ(x),y)=0ifhθ(x)=yCost(hθ(x),y)→∞ify=0andhθ(x)→1Cost(hθ(x),y)→∞ify=0andhθ(x)→1
Simplified Cost Function and Gradient Descent
我们可以将代价函数的两个条件压缩为一个条件:
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
−
y
l
o
g
(
h
θ
(
x
)
)
−
(
1
−
y
)
l
o
g
(
1
−
h
θ
(
x
)
)
Cost({h_\theta }(x),y) = - ylog({h_\theta }(x)) - (1 - y)log(1 - {h_\theta }(x))
Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
随后我们得出完整的代价函数为:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
]
J(\theta ) = - \frac{1}{m}\sum\limits_{i = 1}^m {[{y^{(i)}}log({h_\theta }({x^{(i)}})) + (1 - {y^{(i)}})log(1 - {h_\theta }({x^{(i)}}))]}
J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
向量化后的结果为:
h
=
g
(
X
θ
)
J
(
θ
)
=
1
m
⋅
(
−
y
T
l
o
g
(
h
)
−
(
1
−
y
)
T
l
o
g
(
1
−
h
)
)
\begin{array}{l} h = g(X\theta )\\ J(\theta ) = \frac{1}{m} \cdot ( - {y^T}log(h) - {(1 - y)^T}log(1 - h)) \end{array}
h=g(Xθ)J(θ)=m1⋅(−yTlog(h)−(1−y)Tlog(1−h))
梯度下降
R
e
p
e
a
t
{
θ
J
:
=
θ
j
−
α
∂
∂
θ
j
J
(
θ
)
}
\begin{array}{l} Repeat\{ \\ {\theta _J}: = {\theta _j} - \alpha \frac{\partial }{{\partial {\theta _j}}}J(\theta )\\ \} \end{array}
Repeat{θJ:=θj−α∂θj∂J(θ)}
求导可得:
R
e
p
e
a
t
{
θ
j
:
=
θ
j
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
j
}
\begin{array}{l} Repeat\{ \\ {\theta _j}: = {\theta _j} - \frac{\alpha }{m}\sum\limits_{i = 1}^m {({h_\theta }({x^{(i)}}) - {y^{(i)}}){x^{(i)}}_j} \\ \} \end{array}
Repeat{θj:=θj−mαi=1∑m(hθ(x(i))−y(i))x(i)j}
向量化后可得:
θ
:
=
θ
−
α
m
X
T
(
g
(
X
θ
)
−
y
)
\theta : = \theta - \frac{\alpha }{m}{X^T}(g(X\theta ) - y)
θ:=θ−mαXT(g(Xθ)−y)
Advanced Optimization
这节课中,我们将讲到一些更好的优化方法。
现在我们换一个角度来看一下什么叫做梯度下降,我们有一个代价函数J像要其最小化,那么我们所要做的就是反复的计算
θ
\theta
θ使代价函数最小化,那么我们另一种思路就是计算出代价函数以及其导数,带入到梯度下降的式子中。算完这两项后,我们不一定需要带入梯度下降的式子中,其实还有很多算法可以使用,这些算法在一定程度上要比梯度下降算法更好用一些。比如:
- Conjugate gradient(共轭梯度法)
- BFGS(变尺度法)
- L-BFGS(限制变尺度法)
Advantages
- No need to manually pick α \alpha α
- Often faster than gradient descent
Disadvantages
- More complex
对于这些算法理解起来很有难度,所以我们可以直接使用,下面是代码部分:
function[jVal,gradient]=costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to computer derivative of J(theta)...]
end
options = optimset('GradObj','on','Maxlter','100');
initialTheta = zeros(2,1);
[optTheta,functionVal,exitFlag]=fminunc(@costFunction,initialTheta,options);
Multiclass Classification
Multiclass Classification:one-vs-all
这节课中我们将讲到如何如何使用逻辑回归来计算多类型分类问题,实际上,我想通过一个叫做“一对多”(one-vs-all)的分类算法。
其实很简单,我们先将一种类别拿出来,设置他为正分类,剩下的所有类别设置为负分类,那么我们就可以得到该正分类的在取某值下的概率,那么我们一一进行计算,就会得到每一种类型的概率值。
Solving the Problem of Overfitting
The Problen of Overfitting
这段视频中将讲到什么是过度拟合(Overfitting)。
如果我们做出的预测模型没有很好的拟合我们的数据,我们称其为欠拟合。
如果我们有很多的特征,我们做出的预测模型很好的拟合了所有数据,也就是说代价函数的值基本为零,但我们却不能将其运用于预测其他数据,这就是过度拟合。
在之前一维或者二维问题中我们可以通过画出图像来检测我们的模型是否合适。但是当我们遇到多维的问题时画图就会变得很麻烦。而且当我们遇到很多特征时,过度拟合的问题极容易出现。
对此我们有如下解决方法:
1.Reduce number of features.
- Manually select which features to keep.
- Model selection algorithm.
2.Regularization(正则化)
- Keep all the features,but reduce magnitude/values of parameters θ j \theta_j θj
- Works well when we have a lot of features,each of which contributes a bit to predictin y y y.
Cost Function
Regularization
small values for parameters θ 0 , θ 1 , . . . , θ n \theta_0,\theta_1,...,\theta_n θ0,θ1,...,θn
- “Simpler hypothesis”
- Less prone to overfitting
如果我们有很多的参数值,那我们很难提前选出那些参数是高阶项的参数,也就是不能知道最小化哪些参数,所以我们的代价函数如下所示:
J ( θ ) = 1 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n θ j 2 ] min θ J ( θ ) \begin{array}{l} J(\theta ) = \frac{1}{m}\left[ {\sum\limits_{i = 1}^m {{{\left( {{h_\theta }\left( {{x^{\left( i \right)}}} \right) - {y^{\left( i \right)}}} \right)}^2} + \lambda \sum\limits_{j = 1}^n {{\theta _j}^2} } } \right]\\ \mathop {\min }\limits_\theta J(\theta ) \end{array} J(θ)=m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]θminJ(θ)
如果 λ \lambda λ设置的过大,着就会出现欠拟合问题。
Regularized Linear Regression
J
(
θ
)
=
1
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
min
θ
J
(
θ
)
\begin{array}{l} J(\theta ) = \frac{1}{m}\left[ {\sum\limits_{i = 1}^m {{{\left( {{h_\theta }\left( {{x^{\left( i \right)}}} \right) - {y^{\left( i \right)}}} \right)}^2} + \lambda \sum\limits_{j = 1}^n {{\theta _j}^2} } } \right]\\ \mathop {\min }\limits_\theta J(\theta ) \end{array}
J(θ)=m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]θminJ(θ)
之前我们使用梯度下降法进行求解没有正则化的代价函数:
N
e
w
a
l
g
o
r
i
t
h
m
(
n
≥
1
)
:
R
e
p
e
a
t
{
θ
j
:
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
(
s
i
m
u
l
r
a
n
e
o
u
s
l
y
u
p
d
a
t
e
θ
j
f
o
r
j
=
0
,
.
.
.
,
n
)
}
\begin{array}{l} {\rm{New algorithm(n}} \ge {\rm{1):}}\\ {\rm\qquad\qquad{Repeat\{ }}\\ \qquad\qquad{\theta _j}: = {\theta _j} - \alpha \frac{1}{m}\sum\limits_{i = 1}^m {\left( {{h_\theta }\left( {{x^{(i)}}} \right) - {y^{(i)}}} \right){x_j}^{(i)}} \\ \qquad \qquad\qquad\qquad(simulraneously\quad{\rm\quad{ update }}\quad{\theta _j}\quad for\quad{\rm{ j = 0,}}...{\rm{,n}})\\ {\rm{\} }} \end{array}
Newalgorithm(n≥1):Repeat{θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)(simulraneouslyupdateθjforj=0,...,n)}
现在我们把
θ
0
\theta_0
θ0单独拿出来,因为正则化中我们并不惩罚
θ
0
\theta_0
θ0.
KaTeX parse error: Unknown column alignment: * at position 16: \begin{array}{*̲{20}{l}} {{\rm{…
第二项转化过来就是:
θ
j
:
=
θ
j
(
1
−
α
λ
m
)
−
α
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
{\theta _j}: = {\theta _j}(1 - \alpha \frac{\lambda }{m}) - \alpha \frac{1}{m}({h_\theta }({x^{(i)}}) - {y^{(i)}}){x_j}^{(i)}
θj:=θj(1−αmλ)−αm1(hθ(x(i))−y(i))xj(i)
而
1
−
α
λ
m
1 - \alpha \frac{\lambda }{m}
1−αmλ这一项永远小于1。
Normal equation
KaTeX parse error: Unknown column alignment: * at position 58: …{\begin{array}{*̲{20}{c}} \hline…
中间方阵是
(
n
+
1
)
×
(
n
+
1
)
(n+1)\times (n+1)
(n+1)×(n+1) ,
λ
\lambda
λ必须大于零。
Regularized Logistic Regression
添加正则化后的逻辑回归代价函数如下:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
log
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
]
+
λ
2
m
∑
j
=
1
n
θ
j
2
J(\theta ) = - \frac{1}{m}\sum\nolimits_{i = 1}^m {\left[ {{y^{(i)}}\log ({h_\theta }({x^{(i)}})) + (1 - {y^{(i)}})log(1 - {h_\theta }({x^{(i)}}))} \right]} + \frac{\lambda }{{2m}}\sum\nolimits_{j = 1}^n {{\theta _j}^2}
J(θ)=−m1∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλ∑j=1nθj2














 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









