







安装环境:
Python3.6;CUDA8.0;cudnn6.0。
1.安装git
2.安装Anaconda
3.Code:https://github.com/ildoonet/tf-pose-estimation
旧版本Mark教学视频:https://www.youtube.com/watch?v=nUjGLjOmF7o 注意要激活环境,这部分视频里有讲。
4.在执行pip install -r requirements.txt时
pycocotools报错,出现两个错误,第一个不用管,其中第二个错误为No module named Cython
解决方法:pip install Cython
接着执行 :pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
5.安装完之后安装Tensorflow,
输入命令:pip install tensorflow-gpu==1.4.0
6.安装OpenCV,https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
下载安装包,下载完成跳转到安装包路径下:pip install opencv_python-3.4.6-cp36-cp36m-win_amd64.whl

7.测试tensorflow,运行run_webcam,命令:python run_webcam.py --model=mobilenet_thin_432*368 --camera=0
报错:ImportError: DLL load failed: 找不到指定的模块。 和 ImportError: No module named ‘_pywrap_tensorflow_internal’
解决:之前安装的CUDNN5.1与tensorflow不匹配,下载安装cundnn6.0 for win10 地址:https://developer.nvidia.com/rdp/cudnn-archive。
8.再次调用摄像头:python run_webcam.py --model=mobilenet_thin_432*368 --camera=0
继续报错ImportError: No module named ‘_pafprocess’
解决方法:使用swig再次编译
下载地址:https://sourceforge.net/projects/swig/
解压zip,比如:D:\backupsoftware
添加环境变量到path, 比如: D:\backupsoftware\swigwin-3.0.12
在命令行执行: swig --help,不报错说明安装成功了。(回到base环境中执行该命令)
9.cmd定位到D:\tf-pose-estimation\tf_pose\pafprocess
运行:swig -python -c++ pafprocess.i && python setup.py build_ext --inplace
9.接着又tm报错。。。Emmmmm心态爆炸。
解决方法:https://blog.csdn.net/a2099948768/article/details/81738853
之后再次回到D:\tf-pose-estimation\tf_pose\pafprocess
运行:swig -python -c++ pafprocess.i && python setup.py build_ext --inplace
10.10.继续回到D:\tf-pose-estimation,运行python run_webcam.py --model=mobilenet_thin_432*368 --camera=0
再次报错:ModuleNotFoundError: No module named ‘matplotlib’

解决:pip install matplotlib
11.继续运行python run_webcam.py --model=mobilenet_thin_432x368 --camera=0,再次报错:KeyError: ‘mobilenet_thin_432x368’。此问题在最后一步解决了,可以直接去最后一步看,尝试运行图片。
12.执行:python run.py --model=mobilenet_thin --resize=432x368 --image=./images/p1.jpg
报错:UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
解决:将run.py中第56行import matplotlib.pyplot as plt改成
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
- 1
- 2
- 3
- 4
再次运行:python run.py --model=mobilenet_thin --resize=432x368 --image=./images/p1.jpg
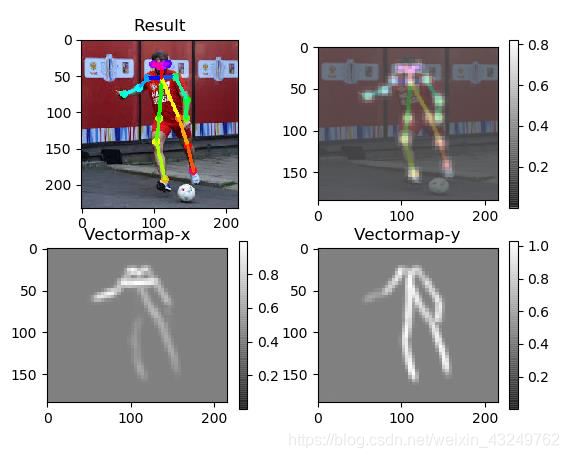
13.继续测试:python run_video.py --model=mobilenet_thin --resolution=432x368 --video=./etcs/dance.mp4,无法检测骨骼。
显示:
解决:在run_video.py文件中进行修改,在parser那块添加一句parser.add_argument('--resize-out-ratio', type=float, default=4.0, help='if provided, resize heatmaps before they are post-processed. default=1.0')
然后下方while cap.isOpened()中humans = e.inference(image)改为
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
- 1

14.继续测试,调用摄像头:python run_webcam.py --model=mobilenet_thin_432x368 --camera=0
报错:KeyError: ‘mobilenet_thin_432x368’
解决:更改命令:python run_webcam.py --model=mobilenet_thin --resize=432x368 --camera=0
PS.追加更新2019.08.16
在新机器上安装出现了一个新报错No module named’tensorflow.contrib.tensorrt’,使用pip执行安装该模块,依旧报错没有发现该模块
解决:\tf-pose-estimation\tf_pose\estimator第14行import tensorflow.contrib.tensorrt as trt注释掉。















 6933
6933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









