






本篇文件目的是为了快速入门scala,投入后续的spark开发而准备的
一、Scala概述
1.1 学习目的:
开发Spark程序
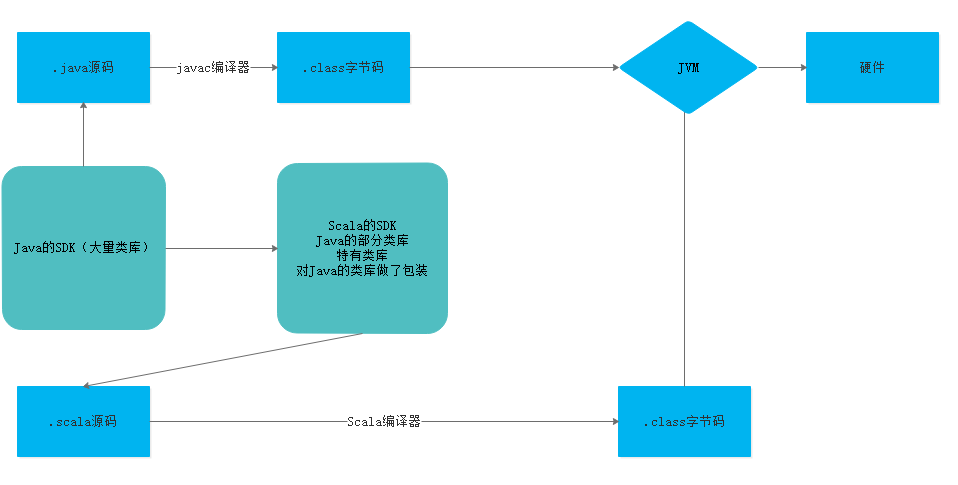
1.2 Scala和java以及JVM之间的关系
二、快速入门案例
2.1 Scala环境配置
1) JDK1.8
2) Scala环境变量配置Path,能够快速找到scala相关指令
3) 测试cmd输入scala即可
2.2 IDEA开发scala
1) 安装插件Scala插件使得IDEA支持Scala开发 Plugins->Scala
2) IDEA中项目不支持Scala开发,需要添加Scala框架 Project Structre->Libraries->添加scala-sdk
3) 和java不同的是Create New Scala Class 时选择Object而不是Class
object Scala_HelloWorld { def main(args: Array[String]): Unit = { Array[String]= new Array[String]("hello") } }
可以看到scala可以写java的内容
Scala和java创建源码项目时的不同点
Scala使用object去模拟静态语法,可以通过对象名称实现静态操作。
解释一下为什么scala创建的是object,我们要知道java和scala使用的虚拟环境都是JVM,这就意味着两者的编译后文件.class语法格式都一样 。
这是因为scala语言是一个完全面向对象的语言,这里的object其实是声明对象(单例对象),我们之前使用的java是声明类然后再去实例化对象,java中静态语法不是面向对象的,而是面向类的,但scala中没有静态语法,而是使用对象.方式的样式去替代静态语法。
使用object关键字声明对象,同时会编译出class文件,注意这里有两个class文件,这是为了模拟静态语法
带$符号的是单例对象object编译后的文件,不带的是类生成的编译后文件
![]()
三、Scala中的方法
def : scala中声明方法的关键字
: Unit 是返回的类型,虽然scala和java一样是强类型的语言,但是开发作者认为名称比类型重要,所以类型放到了后面,这里的Unit相当于java的void即无返回值类型
在java中数组本身是没有类型的,例如String[] arg ,String只是数组中元素的类型,arg是数组名字
scala中 数组自己的类型是Array, 例如Array[String],括号表示泛型
scala声明方法时 = {} 相当于将代码块的内容赋值给方法名
四、Scala中的变量
4.1 scala变量的概述
1.采用var|val关键字声明
2.变量名称应该放置在变量类型之前
3.var | val 变量名 :变量类型 = 变量值
4.如果根据变量值可以推断出变量类型,那么变量类型就可以省略
4.2 val和var的区别
val和var的区别
var修饰的变量值可以修改,但是val修饰的变量不可改变
一般推荐使用val
4.3 变量的输入和输出
输入: //从控制台获取输入 val age = scala.io.StdIn.readInt() //从文件中获取数据 val source : BufferedSource = Source.fromFile("D:\\ScalaProject\\data\\word.txt") val iterator = source.getLines() while(iterator.hasNext){ println(iterator.next()) } source.close() 输出: 插值的方式拼接字符串输出 val name="zs" print(s"name=${name}") 传值的方式拼接字符串输出 printf("name=%s",name)
五、Scala的流程控制
5.1 分支控制
分支控制 Scala中表达式都有返回结果 val age =30 //返回的结果就是最后一行代码的执行结果,println的返回是Unit所以结果是个() //res的类型是相对的,如果if结果有多种类型返回可能,那么res类型就是通用类型,也就是多个结果的公共父类 val res = if (age == 30){ println("age is 30") } print(res) 结果: age is 30 () //上面res类型是Unit //下面这个res类型是Any val res = if (age == 30){ "zs" }else{ 2 } //如果表达式逻辑代码只有一行,可以省略大括号 val res = if (age == 30) "30" else 1 scala中没有三元运算符,可以采用上面的方法来代替三元运算符
5.2循环控制
循环控制 val array = 1 to 5 包含5 val array1 = 1 until 5 不包含5 这是Range的语法糖 val arrary2 = Range(1,5) 相当于 1 until 5 取出集合中的数挨个进行便利 for(i : Int <- array){ println(i) } 如果集合确定 Int可以省略 for(i <- array){ println(i) } 循环守卫,只有不能3才能执行逻辑 for(i <- array if i !=3){ println(i) } 循环步长,by +数字 表示步长 下面的结果是 1 5 for(i <- 1 to 5 by 2 if i !=3){ println(i) } 嵌套循环 for(i <- 1 to 3){ for(j <- 1 to 3){ println("i="+i+",j="+j) } } //如果逻辑比较简单,可以写成下面的方式 for(i<- Range(1,4); j <- Range(1,4)){ println("i="+i+",j="+j) }
六、函数式编程
6.1scala函数概述
1.java中的方法在scala中就是函数,只不过方法是相对类的概念,函数在作用域内有效,方法受到类的约束 2.函数就是功能的封装不属于类的,所以函数名不能重复,没有重载重写概念 def test():Unit = { println("test~") } test()object Function { def main(args: Array[String]): Unit = { def test1():Unit = { println("test~") } } def test2() = { println("test2~") } } 可以看到在main中的test1是f也就是function函数 直接在类中的test2是m也就是method方法

6.2可变参数
可变参数 def func(name:String*)= println(name) func() func("zs","ls") //如果有其他参数,可变参数要放到最后 def func2(age:Int,name:String*)= println(name) func2(20,"ww") 从结果可以看到不同的参数个数结果封装的集合是不同的,无参时是List,其他情况是WrappedArray

6.3默认参数
scala是的参数可以有默认值,传参的时候不传参数就使用默认值 def main(args: Array[String]): Unit = { def info(name:String = "zs",age:Int = 20) = println(s"name=${name},age=${age}") info() }
6.4带名参数
给函数传递参数的时候可以指定顺序传递参数
def main(args: Array[String]): Unit = { def info(name:String = "zs",age:Int = 20) = println(s"name=${name},age=${age}") info(age=20,name="ls") }
6.5函数详解
//函数其实就是对象 //意味着函数有类型,函数可以赋值给其他人使用 def test():Unit={ } def test1(age:Int):String={ age.toString } /* * 函数对象赋值给变量 * test _ 将函数对象赋值给一个变量,这个变量就是函数 * Function后面的数字表示函数有几个参数[]是返回值类型,如有有参数要先把参数类型写[]里最后写返回值类型 * 此时函数的类型:Int(参数列表类型) => String(返回值类型) * 如果是多个参数: (Int,String,Int) => String */ val f1:Function0[Unit] =test _ val f2:Function1[Int,String] = test1 _ 此时 f1()就可以调用函数
/* * 函数对象作为参数使用,类似于将逻辑进行传递 * 意味着逻辑可以不用写死了 */ def sum(a:Int,b:Int) = a+b def diff(a:Int,b:Int) = a-b //test2函数的参数是一个函数,test2中定义了数据,传入的参数是逻辑 def test2(f:(Int,Int)=>Int) = println(f(1,2)) test2(sum) //其实传入的参数名称不重要,重要的是逻辑所以传参时可以省略函数名称 test2((x,y) =>x+y) //只需要参数列表和逻辑代码即可 (x,y) =>x+y是匿名函数的简化 def sum(a:Int,b:Int) ={ a+b } def,函数名,可推断的参数类型,只有一行的逻辑代码->都可以省略 最总就是(x,y)=>x+y 如果参数只有一个小括号也可以省略 x=>x 如果这个逻辑按顺序只使用一次的话可以省略成 _+_ 这里的按顺序是指(x,y) =>x/y 这种 不是按顺序的比如(x,y)=>y/x
//将函数作为返回值返回 def outer() = { def inner()={ println("inner") } inner _ } val f = outer() f()
6.6闭包
def outer(x:Int) = { def inner(y:Int)={ x+y } inner _ } val inner = outer(10) val result = inner(20) println(result) //一般来说outer调用后x就因该出栈了 //但是inner调用后又计算出了x+y的结果30 //这就是函数式编程特有的闭包 //一个函数使用了外部的变量,会改变变量的声明周期
6.7控制抽象
//控制抽象 //本质就是将代码逻辑作为参数直接传递 //参数没有类型 def test(f: =>Unit)={ f } test(println("test..."))
6.8惰性函数
//惰性函数 //当我们给参数赋值函数时,主要想用函数,但是此时函数会被执行,自此不想执行就要使用惰性函数 def test(f:string){ println("test...") } val a = test() 此时test立刻执行 lazy val a = test() 只有a被使用时才执行test
七、面向对象编程
7.1Scala的package语法
包: package com.debu.test1.chapter Java中的.表示从属关系 1.package关键字可以多次声明 package com package debu package test1 package chapter 2.可以给包设定作用域,体现上下级关机 package com{ package debu{ ....{ object name{ def main.... } } } } 3.包可以当作对象 package com //上一级包,如果有多个都要写 //包对象summer_ybg package object summer_ybg { } //包对象中声明的方法和属性,在当前包和子包中都可以访问
7.2Scala的import语法
//JAVA中: 1.导入类 //将util包中的所有类导入 import java.util.* 2.导入类中静态功能 import static java.util.XXXX.YYYY //Scala中: 1.scala不是导入类,而是导入包 import com.debu.test1 2.scala中import关键字可以在任何地方使用,但是只在当前作用域有作用 3.scala导入包中的所有类不用*使用的是_ import java.util._ 4.scala使用{}可以将包中的多个类在同一行中导入 5.屏蔽类 如果不同的包中有相同类名,可以通过屏蔽的方式屏蔽其中之一 import java.util._ import java.sql.{Date=>_,_} 这种方式可以屏蔽掉java.sql中的Date类 6.类可以有别名 比如: val map = new HashMap() 此时HashMap是java还是scala呢不易分辨 可以起个别名 import java.util.{HashMap=>JavaHashMap} val map = new JavaHashMap即可
7.3Scala的Class语法
//java中
1.一个源码文件中,类可以声明多个,但是公共类只能有一个
2.类的目的是抽取对象的相同的内容(模板)
3.使用Class声明类//scala
1.scala源码文件中所有声明的类都可以是公共的
2.使用object关键字也可以声明类,但是同时会产生另一个对象的类
3.object中声明的类被称为伴生类,声明的对象叫伴生对象
4.伴生类和伴生对象可以出现在同一个源码文件中
class Scala_TE{
}
object Scala_TE {
}//scala属性
def main(args: Array[String]): Unit = {
//1.scala中给类声明属性就等同于给类声明变量
//2.变量必须显示初始化不可以var name 就结束了
//3.java中属性可以默认初始化
//4.scala中属性可以默认初始化,但是必须表明属性和使用_赋值
//5.当访问属性时,等同于调用对象的get方法
//6.给属性赋值时,等同雨调用对象的set方法
val user = new User()
user.name = "lisi"
}
class User{
var name="zhangsan"
var age =30
var email:String = _
}
7.4Scala的trait特质
//scala中没有接口的概念 //scala可以将多个对象相同的特质从对象中剥离出来,形成独立的语法结构特质 //一个对象符合这个特质,就可以将特质混入对象中 //向类中混入特质有2种方式 //1.如果存在父类,则采用with混入 //2.如果没有父类,直接采用extends混入 //3.如果要混入多个特质,第一个采用extends,后续采用with 案例: //有一个跑的特质 trait Run{ def run():Unit } //有一个猫类,此时没有父类直接用extends混入即可 //混入后需要重写特质的方法 class Cat extends Run{ override def run()={ println("car run") } } //特质的本质就是接口 //scala种特质语法编译后就是interface //动态混入 //trait可以在构建对象时将新的功能混入 val user = new User() user.insertUser() } class User{ def insertUser()={ println("insert user...") } } 此时想要给user添加一个更新功能,并且这个功能其他类,不止User都可以随时使用怎么办呢 使用动态混入with 混入特质 //构建User对象时动态混入Update特质 val user = new User() with Update user.insertUser() user.updateUser() } trait Update{ def updateUser() = println("update user....") } class User{ def insertUser()={ println("insert user...") } }
八、集合
8.1数组、Seq、Set、Map、元组
//首先看看java的集合 1.List:有序存储,数据可以重复 2.Set: 无序存储,数据不可重复 3.Map: 存储KV键值对,无需存储,key不可重复,value可以重复 //scala侧重与java不同,java侧重数据结构之间的关系,scala侧重的是集合的功能 scala三大集合 1.Seq:有序存储,数据可以重复 2.Set:无序存储,数据不可重复 3.Map:存储KV键值对,无需存储,key不可重复,value可以重复1)'数组' //java中数组不算集合,因为java的集合都是有类型的 //java的数组没有类型,只有数组元素的类型 //scala的数组有类型Array //scala中Array的本质就是java的数组 //scala中[]表示泛型 val array = new Array[String](3) //println(array) 结果[Ljava.lang.String;@19bb089b //反编译后可以看到 String[] array = new Stirng[3]; //此时array没有添加和删除能力的,只能通过索引修改和查询数据 for(i <- 0 to 2){ array(i)="hello" + i } for(elem <- array){ println(elem) } //不通过遍历可以通过mkString将数据数据按照分隔符拼接字符串 println(array.mkString(",")) //循环foreach array.foreach(println) //结合构建时就含有数据 val array2 =Array.apply(1,2,3,4) //apply可以编译器自动识别是可以省略的 //Array是不可变数组,添加数据会产生新的数组 val array3 = Array(1,2,3) val array4 = array3.+:(4) val array5 = array3.:+(4) println(array3 eq array4) //false //如果是冒号结尾,运算就是从右向左的 //所以array4(4,1,2,3) array(1,2,3,4) //可变数组ArrayBuffer val array = new ArrayBuffer[Int]() val arr1 = Array(5,6,7,8) //添加数据 array.append(1,2,3,4) array.appendAll(arr1) //修改(下标,修改值) array.update(3,6) //删除(下标,删除数量) array.remove(0,2)2)'Seq' //Seq类似java的List集合 // val seq = new Seq[Int]() 这样是报错的 //一位内Seq是一个trait 无法直接构建对象,一般采用伴生对象apply方法构建 //apply可以省略 val seq:Seq[Int] = Seq.apply(1, 2, 3, 4) println(seq) //结果是List(1,2,3,4) //Seq是trait无法构建对象,所以底层采用List集合 3)'Set'与'Seq'类似不过插入的数据插入位置是无序的 4)'Map' //Map集合存储的K-V类型的键值对数据 //数据是无序的,K不能重复,V可以重复 //Scala中kv键值对可以采用特殊的方式构建 val k = "a" -> 1 //Map也是一个trait,采用伴生对象构建,mutable构建可变的map集合 val map =mutable.Map(k,"b" -> 2) //增加数据 map.put("c",3) //修改数据 map.update("c",4) //删除数据 map.remove("b") //清除数据 map.clear()
5)'元组' //scala采用特殊的方式将无关的数据组合成整体,称之为元组 例如 val t = (1,"zs","beijing") //元组也是集合,也有类型是Tuple val t:Tuple3[Int,String,Int] = (1,"zs",30) //Tuple关键字后面的数字限制了元素的个数1-22个 //Tuple采用集合类型表示,如下比较麻烦要写泛型 val t:Tuple3[Int,String,Int] = (1,"zs",30) //简化版本: val t1:(Int,String,Int) = (1,"zs",30) //因为元素类型不同所以无法循环遍历 //采用顺序号访问元组的元素 println(t1._1,t1._2,t1._3)
九、隐式转换
//隐式转换 - 二次编译 //这里隐式函数自动调用解决无法转换的问题 //implicit关键字,当编译出现错误时,让编译器自动找到并完成功能 implicit def transform(data:Double) = data.toInt val age:Int = showAge() //这里会报错因为Double无法自动转成Int def showAge():Double = 10.5
















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











