






新的 Hugging Face SmolVLM 在 5.02GB 的 GPU 内存中运行,这意味着它可以在 8GB 的 Jetson Orin Nano 上运行,因为内存由系统和 GPU 共享。这太疯狂了,因为您可以在一个微型边缘设备上运行完全离线的视觉语言模型,功耗仅为 10 瓦。
今天,就让我们一起来了解这个小而强大的视觉语言模型——SmolVLM。
什么是SmolVLM
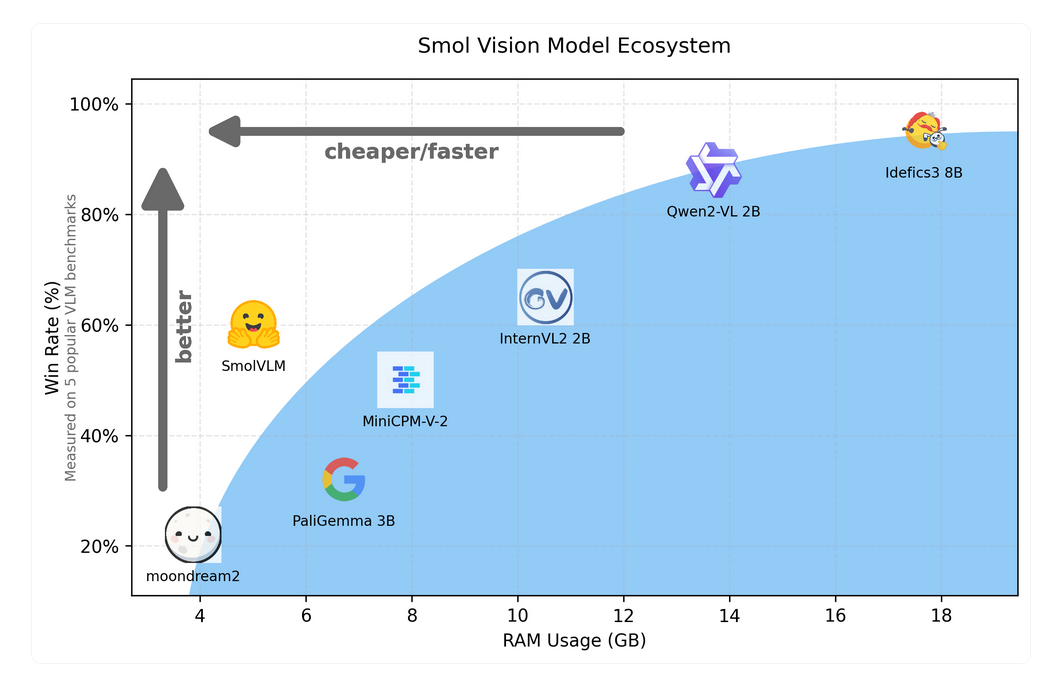
SmolVLM是一款仅有20亿参数的紧凑型视觉语言模型。与目前流行的VLM(如Qwen2-VL、PaliGemma)相比,SmolVLM体积更小、速度更快、内存占用更低,尤其适合在边缘设备或本地环境中运行。更令人惊喜的是,它是一款完全开源的模型,所有的训练数据集、模型检查点和工具都可以免费使用。这为开发者提供了极大的自由度和可定制性。
SmolVLM的核心特点
1. 多样的模型版本
SmolVLM家族包含三种不同版本,满足不同需求:
- SmolVLM-Base:基础模型,可用于各种下游任务的微调。
- SmolVLM-Synthetic:在合成数据上进行微调,更适合处理特定的视觉任务。
- SmolVLM-Instruct:支持交互式应用,可直接用于终端用户场景。
2. 卓越的性能表现
SmolVLM在多个基准测试中表现优异。例如:
- 在文档视觉问答(DocVQA)测试中达到**81.6%**的准确率,超越了许多更大的模型。
- 在数学推理任务(MathVista)中,SmolVLM的表现与先进模型相当,但内存占用仅为竞争对手的三分之一。
3. 极致的内存效率
SmolVLM对每个图像块进行了更高效的压缩(将图像信息压缩至原来的1/9),这大大降低了内存使用。例如,处理同一图像输入时,SmolVLM仅需5GB GPU内存,而类似的模型Qwen2-VL需要超过13GB。
SmolVLM的技术架构
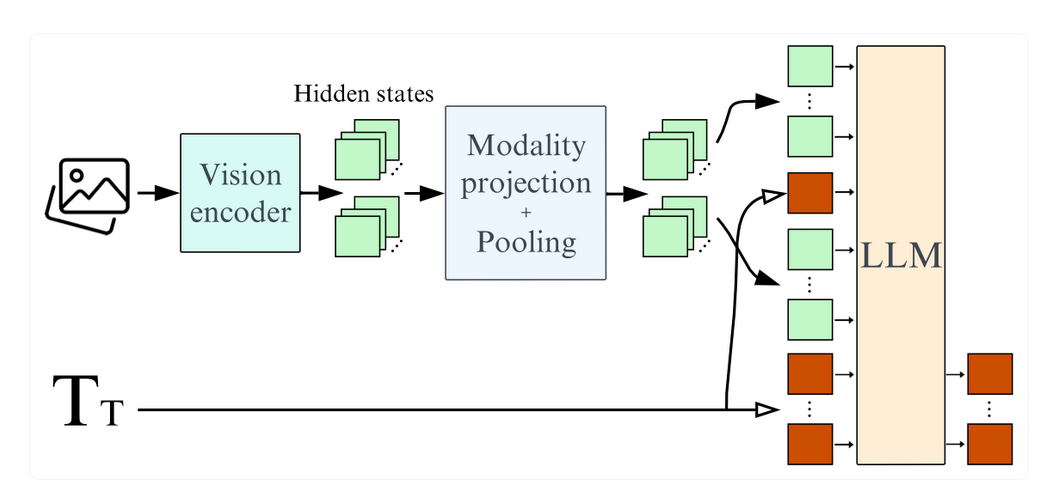
SmolVLM继承了Idefics3的核心架构,但进行了多项优化:
- 语言骨干:采用SmolLM2 1.7B替代了较大的Llama 3.1 8B。
- 视觉处理:图像分块尺寸升级为384x384像素,并采用像素分组(Pixel Shuffle)策略进行压缩处理。
- 上下文扩展:通过增加RoPE基值,使模型支持16k上下文窗口,有助于处理多图像输入和长文本。
应用场景
1. 边缘设备部署
SmolVLM小巧的内存占用,使其能够轻松部署在笔记本电脑、智能手机等设备上。对于资源受限的环境(如边缘计算),它提供了一个高效的解决方案。
2. 图像问答系统
利用SmolVLM,可以构建智能的图像问答系统。例如,用户上传一张寺庙的图片并询问旅行建议,模型能够生成详细的回答,提供景点介绍、建筑风格解析等信息。
3. 视频分析
SmolVLM还支持基本的视频分析。即使在简单的处理流程下,它在CinePile基准上的得分达到了27.14%,表现超越许多更大的模型。
如何使用SmolVLM?
您可以使用 transformer 中的 Auto 类轻松加载 SmolVLM。在底层,模型和处理器映射到用于 Idefics3 的相同实现。
代码语言:javascript
代码运行次数:0
运行
AI代码解释
from transformers import AutoProcessor, AutoModelForVision2Seq
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
图像和文本可以任意交错,您可以传入多张图片。以下是如何使用聊天模板并将格式化的输入传递给处理器。
代码语言:javascript
代码运行次数:0
运行
AI代码解释
from PIL import Image
from transformers.image_utils import load_image
# Load images
image1 = load_image("https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/resolve/main/example_images/rococo.jpg")
image2 = load_image("https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/blob/main/example_images/rococo_1.jpg")
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
使用预处理的输入开始生成并解码生成的输出。
代码语言:javascript
代码运行次数:0
运行
AI代码解释
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
微调
SmolVLM不仅性能强大,还提供了灵活的微调选项:
- 支持LoRA和QLoRA微调:降低显存需求,适合在消费级GPU上进行训练。
- 提供开源训练脚本:开发者可以使用官方提供的脚本,在自己的数据集上进一步优化模型性能。
详细的信息可以访问这篇文章:https://huggingface.co/blog/smolvlm
代码:huggingface/smollm: Everything about the SmolLM2 and SmolVLM family of models
权重:https://huggingface.co/HuggingFaceTB
Demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM2
原文链接:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









