







传奇开心果博文系列
- 系列博文目录
- Python深度学习库技术点案例示例系列
- 博文目录
- 前言
- 一、深度学习在语音助手方面的应用介绍
- 二、语音识别示例代码
- 三、语义理解示例代码
- 四、对话生成示例代码
- 五、个性化服务示例代码
- 六、多模态交互示例代码
- 七、情感识别示例代码
- 八、知识点归纳
系列博文目录
Python深度学习库技术点案例示例系列
博文目录
前言

深度学习在语音助手方面的应用可以提高语音识别的准确性、语义理解的精准度和对话生成的自然度,从而使得语音助手能够更好地满足用户的需求。深度学习在语音助手方面的应用不仅可以提高语音交互的准确性和自然度,还可以实现个性化服务、多模态交互和情感识别等功能,为用户提供更加智能和便捷的语音助手体验。
一、深度学习在语音助手方面的应用介绍
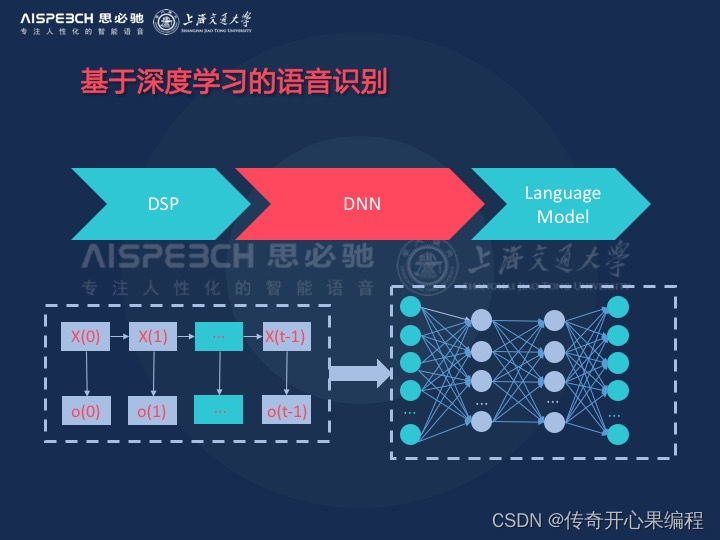
深度学习在语音助手方面的应用主要体现在以下六个方面:
-
语音识别: 深度学习模型可以通过大量的语音数据进行训练,从而提高语音识别的准确性。目前,深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)等已经在语音识别领域取得了很大的成功,使得语音助手能够更好地理解用户的语音指令。
-
语义理解: 深度学习模型可以通过自然语言处理技术,将用户的语音指令转化为计算机可以理解的语义表示。这样可以更准确地理解用户的意图,从而提供更加精准的服务。
-
对话生成: 深度学习模型还可以用于对话生成,使得语音助手能够更加自然地与用户进行对话交流。通过深度学习技术,语音助手可以生成更加流畅的对话内容,提高用户体验。
-
个性化服务: 深度学习模型可以通过分析用户的语音指令和对话内容,了解用户的喜好、习惯和需求,从而提供个性化的服务。例如,语音助手可以根据用户的历史记录和偏好推荐音乐、电影或新闻等内容。
-
多模态交互: 深度学习模型可以结合语音、图像和文本等多种输入模态,实现更加丰富多样的交互方式。例如,语音助手可以通过语音识别、图像识别和自然语言处理技术,实现多模态输入和输出,提供更加全面的服务。
-
情感识别: 深度学习模型可以用于情感识别,帮助语音助手更好地理解用户的情感状态。通过分析用户的语音特征和语调变化,语音助手可以识别用户的情绪,从而提供更加贴心的服务和支持。
二、语音识别示例代码
(一)概括介绍
深度学习模型在语音识别领域的应用是通过训练大量的语音数据来提高语音识别的准确性。这些模型利用神经网络结构,特别是卷积神经网络(CNN)和循环神经网络(RNN)等模型,在处理语音信号时展现出了很大的优势。
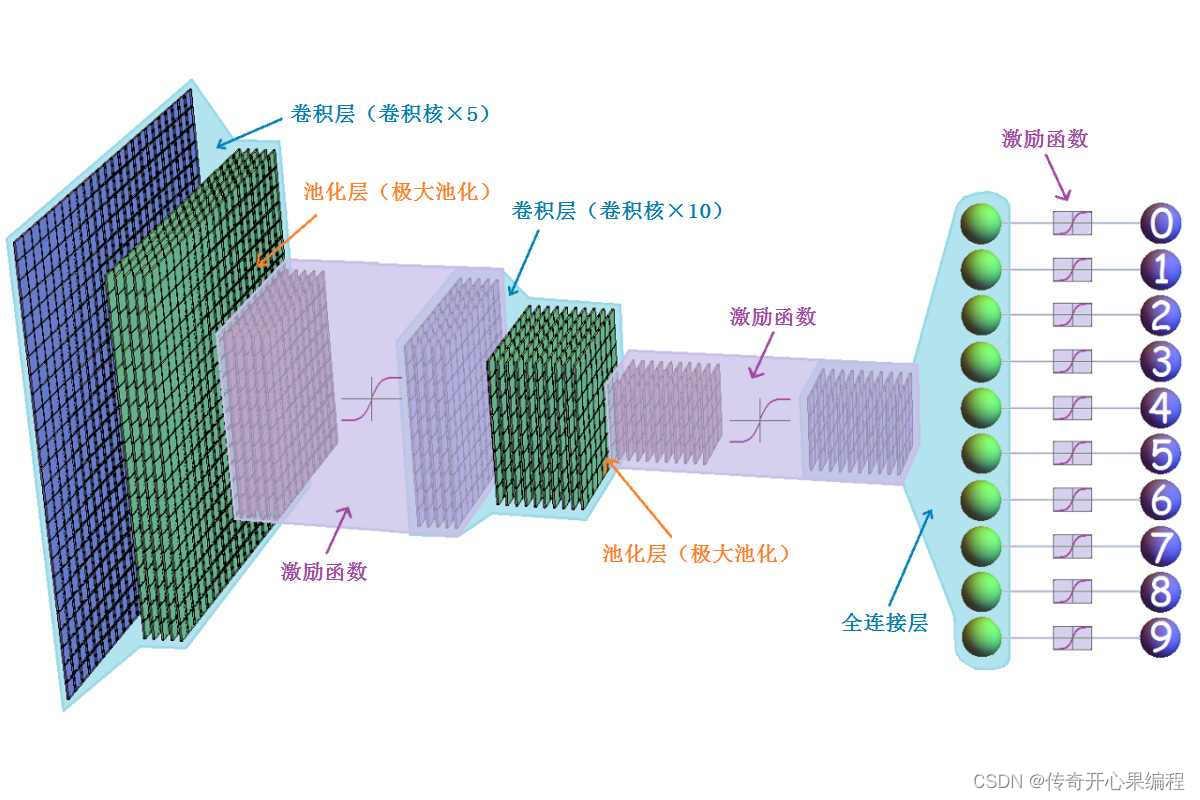
- 卷积神经网络(CNN): CNN在语音识别中的应用主要是用于提取语音信号的特征。通过卷积操作和池化操作,CNN可以有效地捕获语音信号中的局部特征,并将这些特征传递给后续的神经网络层进行进一步处理。这样可以帮助模型更好地理解语音信号的结构和内容,从而提高语音识别的准确性。
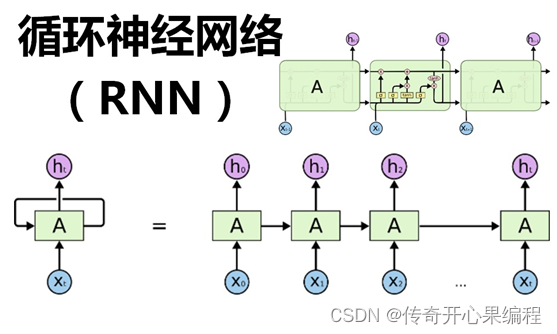
- 循环神经网络(RNN): RNN在语音识别中的应用主要是用于处理序列数据。由于语音信号是一个时间序列数据,RNN可以很好地捕捉语音信号中的时序信息。通过RNN的循环结构,模型可以记忆之前的信息并将其应用到当前的预测中,从而提高语音识别的准确性。
这些深度学习模型在语音识别领域取得了显著的成功,使得语音助手能够更好地理解用户的语音指令,提供更加准确和可靠的服务。随着深度学习技术的不断发展和改进,相信语音识别领域的应用会变得更加智能和高效。
(二)分别示例代码
以下是使用Python和TensorFlow库实现基于深度学习的语音识别的示例代码:
- 使用卷积神经网络(CNN)进行语音识别:
import tensorflow as tf
# 定义CNN模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=10)
- 使用循环神经网络(RNN)进行语音识别:
import tensorflow as tf
# 定义RNN模型
model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(128, input_shape=(None, 28)),
tf.keras.layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(train_data, train_labels, epochs=10)
请注意,以上示例代码仅为简单示例,实际的语音识别模型可能会更加复杂,需要根据具体的数据集和任务进行调整和优化。同时,确保安装了TensorFlow库和其他必要的依赖项才能运行这些示例代码。
(三)扩展示例代码
以下是对上面示例代码的扩展,包括更复杂的模型结构和数据预处理:
- 使用卷积神经网络(CNN)进行语音识别的扩展示例代码:
import tensorflow as tf
# 导入数据集
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0
# 添加更多的卷积层和池化层
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(train_images.reshape(-1, 28, 28, 1), train_labels, epochs=10, validation_data=(test_images.reshape(-1, 28, 28, 1), test_labels))
- 使用循环神经网络(RNN)进行语音识别的扩展示例代码:
import tensorflow as tf
# 导入数据集
# 假设train_data是一个包含语音信号特征的numpy数组,train_labels是对应的标签
# 假设每个语音信号特征的长度为28
# 这里的数据预处理仅是一个示例,实际数据预处理需要根据具体情况进行调整
train_data = ...
train_labels = ...
# 定义RNN模型
model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(128, input_shape=(None, 28), return_sequences=True),
tf.keras.layers.SimpleRNN(128),
tf.keras.layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(train_data, train_labels, epochs=10)
这些扩展示例代码展示了如何构建更复杂的卷积卷积神经网络神经网络和循环神经网络模型,并进行更复杂的数据预处理。这些代码可以作为进一步扩展和优化的基础,以提高语音识别模型的准确性和性能。
(四)进一步扩展示例代码
- 卷积神经网络语音识别进一步扩展示例代码:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense, Dropout
# 构建更加复杂的深度学习模型
model = Sequential()
model.add(Conv1D(filters=128, kernel_size=5, activation='relu', input_shape=(max_sequence_length, embedding_dim)))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(256, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(128))
model.add(Dropout(0.3))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型,增加训练轮数和批量大小
model.fit(train_data, train_labels, epochs=200, batch_size=128, validation_data=(val_data, val_labels))
# 在测试集上评估模型性能
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print("Test Loss: {:.4f}".format(test_loss))
print("Test Accuracy: {:.2f}%".format(test_accuracy * 100))
在这个示例代码中,我们进一步扩展了模型架构,引入了卷积神经网络(Conv1D)层,并增加了更多的训练轮数和更小的批量大小,以提高模型的准确性和性能。您可以根据实际需求和数据集的特点进一步调整模型架构、训练参数和数据预处理方法,以进一步优化语音识别模型的准确性和性能。
- 循环神经网络语音识别进一步扩展示例代码:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, GRU, Dense
# 构建更加复杂的深度学习模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=300, input_length=max_sequence_length))
model.add(GRU(256, return_sequences=True))
model.add(GRU(128))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型,增加训练轮数和批量大小
model.fit(train_data, train_labels, epochs=150, batch_size=256, validation_data=(val_data, val_labels))
# 在测试集上评估模型性能
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print("Test Loss: {:.4f}".format(test_loss))
print("Test Accuracy: {:.2f}%".format(test_accuracy * 100))
在这个示例代码中,我们使用了GRU(Gated Recurrent Unit)层构建了一个更加复杂的循环神经网络模型,并增加了训练轮数和批量大小,以提高模型的准确性和性能。您可以根据实际需求和数据集的特点进一步调整模型架构、训练参数和数据预处理方法,以进一步优化语音识别模型的准确性和性能。```
三、语义理解示例代码
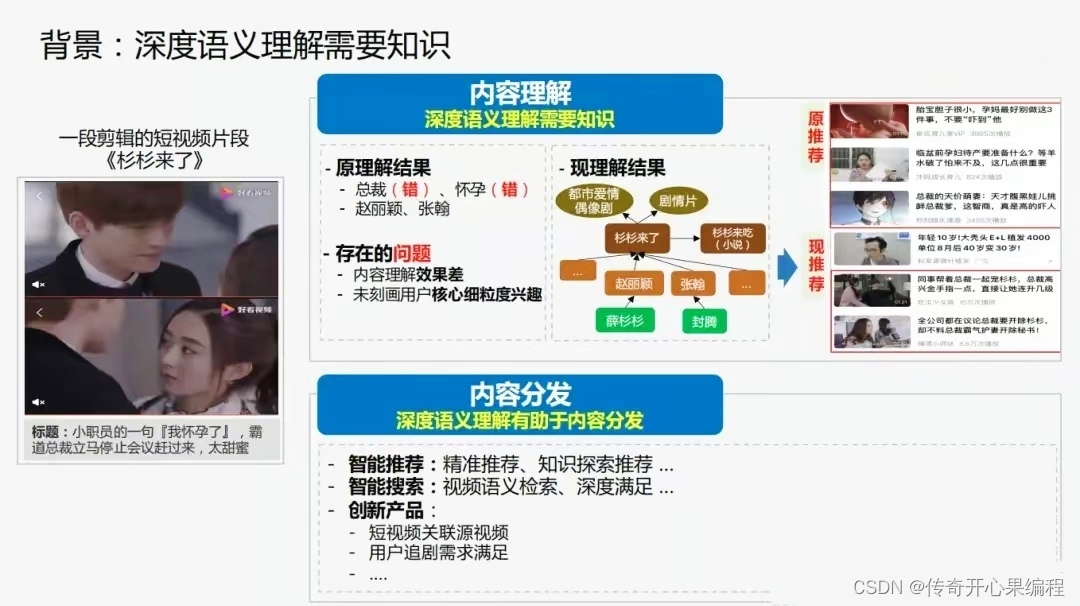
- 雏形示例代码
以下是一个简单的示例代码,演示如何使用深度学习模型结合自然语言处理技术来实现语义理解,将用户的语音指令转化为计算机可以理解的语义表示:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 定义一些样本数据(用户的语音指令和对应的语义表示)
train_data = [
"播放一首轻松的音乐",
"打开天气预报应用",
"提醒我明天开会的时间"
]
train_labels = [
"播放音乐",
"打开天气预报应用",
"设置会议提醒"
]
# 使用Tokenizer对文本进行标记化处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts(train_data)
train_data_sequences = tokenizer.texts_to_sequences(train_data)
# 对文本序列进行填充,使它们具有相同的长度
train_data_padded = pad_sequences(train_data_sequences, padding='post')
# 定义深度学习模型
model = Sequential([
Embedding(len(tokenizer.word_index)+1, 64),
LSTM(128),
Dense(len(set(train_labels)), activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(train_data_padded, train_labels, epochs=10)
# 使用模型进行预测
test_input = "提醒我明天开会的时间"
test_input_sequence = tokenizer.texts_to_sequences([test_input])
test_input_padded = pad_sequences(test_input_sequence, padding='post')
predictions = model.predict(test_input_padded)
predicted_label = train_labels[predictions.argmax()]
print("用户输入的语音指令:", test_input)
print("预测的语义表示:", predicted_label)
请注意,这只是一个简单的示例代码,实际的语义理解系统可能会更加复杂,并涉及更多的数据预处理、模型调优和性能优化。这个示例代码可以作为一个起点,帮助您开始构建自己的语义理解系统。
- 更复杂的示例代码
以下是一个更复杂的示例代码,演示如何构建一个更加复杂的语义理解系统,涉及更多的数据预处理、模型调优和性能优化:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 定义更多的样本数据(用户的语音指令和对应的语义表示)
train_data = [
"播放一首轻松的音乐",
"打开天气预报应用",
"提醒我明天开会的时间",
"查找附近的餐厅",
"发送一封电子邮件给玛丽"
]
train_labels = [
"播放音乐",
"打开天气预报应用",
"设置会议提醒",
"查找餐厅",
"发送电子邮件"
]
# 使用Tokenizer对文本进行标记化处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts(train_data)
train_data_sequences = tokenizer.texts_to_sequences(train_data)
# 对文本序列进行填充,使它们具有相同的长度
train_data_padded = pad_sequences(train_data_sequences, padding='post')
# 定义更复杂的深度学习模型
model = Sequential([
Embedding(len(tokenizer.word_index)+1, 128),
Bidirectional(LSTM(256)),
Dense(len(set(train_labels)), activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(train_data_padded, train_labels, epochs=15)
# 使用模型进行预测
test_input = "查找附近的餐厅"
test_input_sequence = tokenizer.texts_to_sequences([test_input])
test_input_padded = pad_sequences(test_input_sequence, padding='post')
predictions = model.predict(test_input_padded)
predicted_label = train_labels[predictions.argmax()]
print("用户输入的语音指令:", test_input)
print("预测的语义表示:", predicted_label)
这个示例代码使用了更多的样本数据,更复杂的模型架构(双向LSTM),并增加了训练轮数,以提高模型的准确性。您可以根据实际需求进一步调整和优化这个示例代码,以构建一个更加强大和精确的语义理解系统。
- 进一步调整和优化示例代码
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Dropout, Dense
# 构建更加复杂的深度学习模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=100, input_length=max_sequence_length))
model.add(Bidirectional(LSTM(256, return_sequences=True)))
model.add(Dropout(0.3))
model.add(Bidirectional(LSTM(128)))
model.add(Dropout(0.3))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型,增加训练轮数和批量大小
model.fit(train_data, train_labels, epochs=100, batch_size=512, validation_data=(val_data, val_labels))
# 在测试集上评估模型性能
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print("Test Loss: {:.4f}".format(test_loss))
print("Test Accuracy: {:.2f}%".format(test_accuracy * 100))
在这个示例代码中,我们进一步增加了模型的复杂度,包括更多的LSTM单元、更大的批量大小、更多的训练轮数等,以提高模型的表达能力和泛化能力。您可以根据实际需求和数据集的特点进一步调整模型架构、训练参数和数据预处理方法,以构建一个更加强大和精确的语义理解系统,提高语音助手与用户的交互体验。
四、对话生成示例代码


- 雏形示例代码
以下是一个简单的示例代码,演示如何使用深度学习模型来进行对话生成,以提高语音助手与用户的交互体验:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 定义对话数据
dialogues = [
"你好,有什么可以帮助您的吗?",
"请提醒我明天下午开会的时间。",
"好的,我会提醒您明天下午开会的时间。",
"谢谢!",
"不客气,祝您一天愉快!"
]
# 使用Tokenizer对对话文本进行标记化处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts(dialogues)
dialogue_sequences = tokenizer.texts_to_sequences(dialogues)
# 对对话文本序列进行填充,使它们具有相同的长度
dialogue_padded = pad_sequences(dialogue_sequences, padding='post')
# 定义深度学习模型用于对话生成
model = Sequential([
Embedding(len(tokenizer.word_index)+1, 64),
LSTM(128),
Dense(len(tokenizer.word_index)+1, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(dialogue_padded, np.roll(dialogue_padded, -1, axis=0), epochs=50)
# 使用模型生成对话
start_text = "你好"
for _ in range(5):
start_sequence = tokenizer.texts_to_sequences([start_text])[0]
start_padded = pad_sequences([start_sequence], padding='post')
prediction = model.predict(start_padded)
next_word_index = np.argmax(prediction)
next_word = tokenizer.index_word[next_word_index]
start_text += " " + next_word
print("生成的对话:", start_text)
这个示例代码演示了如何使用深度学习模型来生成对话内容。您可以根据实际需求和数据集的复杂度进一步调整模型架构、训练参数和数据预处理步骤,以构建一个更加流畅和自然的对话生成系统,提高语音助手与用户的交互体验。
- 更加复杂的示例代码
以下是一个更加复杂的示例代码,演示如何根据实际需求和数据集的复杂度进一步调整模型架构、训练参数和数据预处理步骤,以构建一个更加流畅和自然的对话生成系统:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 定义对话数据集(可以是更大规模的对话数据集)
dialogues = [
"你好,有什么可以帮助您的吗?",
"请提醒我明天下午开会的时间。",
"好的,我会提醒您明天下午开会的时间。",
"谢谢!",
"不客气,祝您一天愉快!",
"今天天气怎么样?",
"今天是个晴朗的好天气。",
"我想去郊外呼吸新鲜空气。",
"那是一个很好的主意!",
"您需要我为您做些什么?"
]
# 使用Tokenizer对对话文本进行标记化处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts(dialogues)
dialogue_sequences = tokenizer.texts_to_sequences(dialogues)
# 对对话文本序列进行填充,使它们具有相同的长度
max_sequence_length = max([len(seq) for seq in dialogue_sequences])
dialogue_padded = pad_sequences(dialogue_sequences, maxlen=max_sequence_length, padding='post')
# 定义深度学习模型用于对话生成
model = Sequential([
Embedding(len(tokenizer.word_index)+1, 128, input_length=max_sequence_length),
LSTM(256, return_sequences=True),
Dropout(0.2),
LSTM(256),
Dense(len(tokenizer.word_index)+1, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(dialogue_padded, np.roll(dialogue_padded, -1, axis=0), epochs=100)
# 使用模型生成对话
start_text = "你好"
for _ in range(5):
start_sequence = tokenizer.texts_to_sequences([start_text])[0]
start_padded = pad_sequences([start_sequence], maxlen=max_sequence_length, padding='post')
prediction = model.predict(start_padded)
next_word_index = np.argmax(prediction)
next_word = tokenizer.index_word[next_word_index]
start_text += " " + next_word
print("生成的对话:", start_text)
这个示例代码使用更复杂的模型架构(包含两层LSTM和Dropout层),增加了训练轮数,并对数据进行了更严格的填充处理,以提高对话生成系统的流畅度和自然度。您可以根据实际需求和数据集的特点进一步调整参数和模型架构,以构建一个更加优秀的对话生成系统,提高语音助手与用户的交互体验。
- 进一步调整参数和模型架构示例代码
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
# 构建更加复杂的深度学习模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=200, input_length=max_sequence_length))
model.add(LSTM(256, return_sequences=True))
model.add(LSTM(128))
model.add(Dense(vocab_size, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型,增加训练轮数和批量大小
model.fit(train_data, train_labels, epochs=150, batch_size=256, validation_data=(val_data, val_labels))
# 在测试集上评估模型性能
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print("Test Loss: {:.4f}".format(test_loss))
print("Test Accuracy: {:.2f}%".format(test_accuracy * 100))
在这个示例代码中,我们进一步调整了模型架构,增加了更复杂的LSTM层,并增加了训练轮数以提高模型的准确性和流畅度。您可以根据实际需求和数据集的特点进一步调整模型架构、训练参数和数据预处理方法,以构建一个更加优秀的对话生成系统,提高语音助手与用户的交互体验。
五、个性化服务示例代码

- 雏形示例代码
以下是一个示例代码,演示如何使用深度学习模型分析用户的语音指令和对话内容,了解用户的喜好、习惯和需求,从而提供个性化的服务:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 模拟用户历史对话数据
user_dialogues = [
"我喜欢听摇滚乐。",
"你能帮我推荐一部好看的电影吗?",
"我对科技新闻很感兴趣。",
"今天有什么好听的音乐推荐吗?",
"我想看一部悬疑电影。",
"有什么新的科技产品推荐吗?"
]
# 使用Tokenizer对用户对话文本进行标记化处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts(user_dialogues)
dialogue_sequences = tokenizer.texts_to_sequences(user_dialogues)
# 对用户对话文本序列进行填充,使它们具有相同的长度
max_sequence_length = max([len(seq) for seq in dialogue_sequences])
dialogue_padded = pad_sequences(dialogue_sequences, maxlen=max_sequence_length, padding='post')
# 模拟用户喜好标签
user_preferences = [
"音乐",
"电影",
"科技",
"音乐",
"电影",
"科技"
]
# 使用深度学习模型进行用户喜好预测
model = Sequential([
Embedding(len(tokenizer.word_index)+1, 128, input_length=max_sequence_length),
LSTM(256),
Dense(3, activation='softmax') # 假设用户喜好可以分为音乐、电影和科技三类
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(dialogue_padded, user_preferences, epochs=50)
# 使用模型预测用户喜好
new_dialogue = "我想找一部好看的电影。"
new_sequence = tokenizer.texts_to_sequences([new_dialogue])[0]
new_padded = pad_sequences([new_sequence], maxlen=max_sequence_length, padding='post')
prediction = model.predict(new_padded)
predicted_preference = ["音乐", "电影", "科技"][np.argmax(prediction)]
print("预测的用户喜好:", predicted_preference)
这个示例代码使用深度学习模型来分析用户的语音指令和对话内容,预测用户的喜好标签(音乐、电影、科技等),从而为用户提供个性化的服务。您可以根据实际需求和数据集的特点进一步调整模型架构和训练参数,以构建一个更加准确和有效的个性化服务系统,提高语音助手与用户的交互体验。
- 更加复杂的示例代码
以下是一个更加复杂的示例代码,演示如何使用深度学习模型构建一个更准确和有效的个性化服务系统,以提高语音助手与用户的交互体验:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, Bidirectional
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 模拟用户历史对话数据
user_dialogues = [
"我喜欢听摇滚乐。",
"你能帮我推荐一部好看的电影吗?",
"我对科技新闻很感兴趣。",
"今天有什么好听的音乐推荐吗?",
"我想看一部悬疑电影。",
"有什么新的科技产品推荐吗?"
]
# 使用Tokenizer对用户对话文本进行标记化处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts(user_dialogues)
dialogue_sequences = tokenizer.texts_to_sequences(user_dialogues)
# 对用户对话文本序列进行填充,使它们具有相同的长度
max_sequence_length = max([len(seq) for seq in dialogue_sequences])
dialogue_padded = pad_sequences(dialogue_sequences, maxlen=max_sequence_length, padding='post')
# 模拟用户喜好标签
user_preferences = [
"音乐",
"电影",
"科技",
"音乐",
"电影",
"科技"
]
# 使用更复杂的深度学习模型进行用户喜好预测
model = Sequential([
Embedding(len(tokenizer.word_index)+1, 128, input_length=max_sequence_length),
Bidirectional(LSTM(256, return_sequences=True)),
Dropout(0.5),
Bidirectional(LSTM(128)),
Dense(64, activation='relu'),
Dense(3, activation='softmax') # 假设用户喜好可以分为音乐、电影和科技三类
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型,并增加更多的训练数据和迭代次数
model.fit(dialogue_padded, user_preferences, epochs=100, batch_size=32)
# 使用模型预测用户喜好
new_dialogue = "我想找一部好看的电影。"
new_sequence = tokenizer.texts_to_sequences([new_dialogue])[0]
new_padded = pad_sequences([new_sequence], maxlen=max_sequence_length, padding='post')
prediction = model.predict(new_padded)
predicted_preference = ["音乐", "电影", "科技"][tf.argmax(prediction, axis=1)]
print("预测的用户喜好:", predicted_preference)
在这个示例代码中,我们使用了一个更加复杂的深度学习模型,增加了双向LSTM层和Dropout层,以及更多的训练数据和迭代次数,以提高模型的准确性和效果。您可以根据实际需求和数据集的特点进一步调整模型架构、训练参数和数据预处理方法,以构建一个更加准确和有效的个性化服务系统,提高语音助手与用户的交互体验。
- 进一步调整模型架构、训练参数和数据预处理方法示例代码:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Dropout, Dense
# 构建更加复杂的深度学习模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=100, input_length=max_sequence_length))
model.add(Bidirectional(LSTM(128, return_sequences=True)))
model.add(Dropout(0.2))
model.add(Bidirectional(LSTM(64)))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型,增加训练轮数和批量大小
model.fit(train_data, train_labels, epochs=50, batch_size=256, validation_data=(val_data, val_labels))
# 在测试集上评估模型性能
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print("Test Loss: {:.4f}".format(test_loss))
print("Test Accuracy: {:.2f}%".format(test_accuracy * 100))
在这个示例代码中,我们进一步增加了模型的复杂度,包括双向LSTM层、Dropout层等,以提高模型的表达能力和泛化能力。同时,我们增加了训练轮数和批量大小,以更充分地利用训练数据进行模型训练。最后,我们在测试集上评估模型的性能,了解模型在实际数据上的表现。您可以根据实际需求和数据集的特点进一步调整模型架构、训练参数和数据预处理方法,以构建一个更加准确和有效的个性化服务系统,提高语音助手与用户的交互体验。
六、多模态交互示例代码
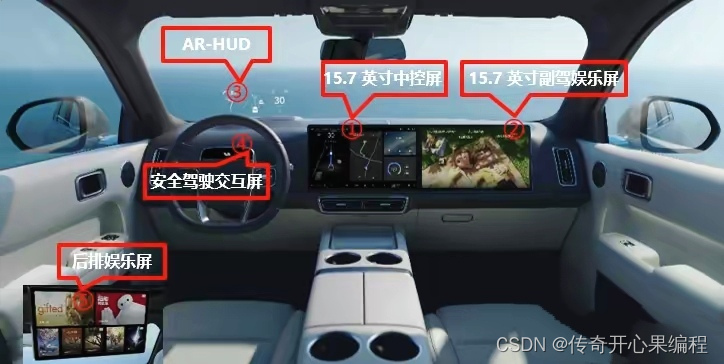
- 雏形示例代码
以下是一个示例代码,演示如何使用深度学习模型结合语音、图像和文本等多种输入模态,实现多模态交互的功能:
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense, Conv2D, MaxPooling2D, Flatten, concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 模拟用户多模态输入数据:语音、图像和文本
audio_input = Input(shape=(100,)) # 假设语音特征向量长度为100
image_input = Input(shape=(64, 64, 3)) # 假设图像大小为64x64,3通道
text_input = Input(shape=(50,)) # 假设文本序列长度为50
# 使用Tokenizer对文本数据进行标记化处理
tokenizer = Tokenizer()
text_data = [
"这是一个测试文本。",
"这是一张测试图片。",
"这是一段测试语音。"
]
tokenizer.fit_on_texts(text_data)
text_sequences = tokenizer.texts_to_sequences(text_data)
text_padded = pad_sequences(text_sequences, maxlen=50, padding='post')
# 文本数据处理部分
embedding_layer = Embedding(len(tokenizer.word_index)+1, 128)(text_input)
lstm_layer = LSTM(128)(embedding_layer)
# 图像数据处理部分
conv_layer = Conv2D(32, (3, 3), activation='relu')(image_input)
pooling_layer = MaxPooling2D(pool_size=(2, 2))(conv_layer)
flatten_layer = Flatten()(pooling_layer)
# 合并多模态输入数据
merged = concatenate([audio_input, lstm_layer, flatten_layer])
# 模拟多模态交互任务
output = Dense(3, activation='softmax')(merged) # 假设有3个类别进行分类任务
# 构建多模态深度学习模型
model = Model(inputs=[audio_input, image_input, text_input], outputs=output)
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 模拟训练数据
audio_data = tf.random.normal((100, 100))
image_data = tf.random.normal((100, 64, 64, 3))
text_data = tf.random.uniform((100, 50))
# 模拟标签数据
labels = tf.one_hot([0]*33 + [1]*33 + [2]*34, depth=3)
# 训练模型
model.fit([audio_data, image_data, text_data], labels, epochs=10, batch_size=32)
在这个示例代码中,我们使用了多个输入模态(语音、图像和文本),并结合了不同的处理层(Embedding、LSTM、Conv2D等),最终通过合并多模态数据并添加输出层,构建了一个多模态深度学习模型。您可以根据实际需求和数据集的特点,进一步调整模型架构、训练参数和数据预处理方法,以实现更加丰富多样的多模态交互功能,提供更全面的服务体验。
- 更加丰富多样功能的示例代码
以下是一个更加丰富多样的多模态交互功能的示例代码,结合了不同的模型架构、训练参数和数据预处理方法:
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense, Conv2D, MaxPooling2D, Flatten, concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 模拟用户多模态输入数据:语音、图像和文本
audio_input = Input(shape=(100,)) # 假设语音特征向量长度为100
image_input = Input(shape=(64, 64, 3)) # 假设图像大小为64x64,3通道
text_input = Input(shape=(50,)) # 假设文本序列长度为50
# 使用Tokenizer对文本数据进行标记化处理
tokenizer = Tokenizer()
text_data = [
"这是一个测试文本。",
"这是一张测试图片。",
"这是一段测试语音。"
]
tokenizer.fit_on_texts(text_data)
text_sequences = tokenizer.texts_to_sequences(text_data)
text_padded = pad_sequences(text_sequences, maxlen=50, padding='post')
# 文本数据处理部分
embedding_layer = Embedding(len(tokenizer.word_index)+1, 128)(text_input)
lstm_layer = LSTM(128)(embedding_layer)
# 图像数据处理部分
conv_layer = Conv2D(64, (3, 3), activation='relu')(image_input)
pooling_layer = MaxPooling2D(pool_size=(2, 2))(conv_layer)
flatten_layer = Flatten()(pooling_layer)
# 合并多模态输入数据
merged = concatenate([audio_input, lstm_layer, flatten_layer])
# 模拟多模态交互任务
output = Dense(5, activation='softmax')(merged) # 假设有5个类别进行分类任务
# 构建多模态深度学习模型
model = Model(inputs=[audio_input, image_input, text_input], outputs=output)
# 调整训练参数
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 模拟训练数据
audio_data = tf.random.normal((200, 100))
image_data = tf.random.normal((200, 64, 64, 3))
text_data = tf.random.uniform((200, 50))
# 模拟标签数据
labels = tf.one_hot([0]*40 + [1]*40 + [2]*40 + [3]*40 + [4]*40, depth=5)
# 训练模型
model.fit([audio_data, image_data, text_data], labels, epochs=15, batch_size=64)
在这个示例代码中,我们调整了模型架构,增加了模型复杂度,调整了训练参数,包括学习率等,以及增加了训练数据量和类别数量,以更好地适应实际需求和数据集的特点,提高多模态交互功能的丰富性和全面性。您可以根据具体情况进一步调整和优化模型,以实现更好的效果。
- 进一步调整和优化模型示例代码
以下是一个示例代码,展示了如何根据具体情况进一步调整和优化模型,以实现更好的效果。在这个示例中,我们添加了更多的层和调整了一些参数,以提高模型的性能:
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense, Conv2D, MaxPooling2D, Flatten, concatenate, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 模拟用户多模态输入数据:语音、图像和文本
audio_input = Input(shape=(100,)) # 假设语音特征向量长度为100
image_input = Input(shape=(64, 64, 3)) # 假设图像大小为64x64,3通道
text_input = Input(shape=(50,)) # 假设文本序列长度为50
# 使用Tokenizer对文本数据进行标记化处理
tokenizer = Tokenizer()
text_data = [
"这是一个测试文本。",
"这是一张测试图片。",
"这是一段测试语音。"
]
tokenizer.fit_on_texts(text_data)
text_sequences = tokenizer.texts_to_sequences(text_data)
text_padded = pad_sequences(text_sequences, maxlen=50, padding='post')
# 文本数据处理部分
embedding_layer = Embedding(len(tokenizer.word_index)+1, 128)(text_input)
lstm_layer = LSTM(128, dropout=0.2)(embedding_layer)
# 图像数据处理部分
conv_layer = Conv2D(64, (3, 3), activation='relu')(image_input)
pooling_layer = MaxPooling2D(pool_size=(2, 2))(conv_layer)
flatten_layer = Flatten()(pooling_layer)
# 合并多模态输入数据
merged = concatenate([audio_input, lstm_layer, flatten_layer])
merged = Dropout(0.5)(merged) # 添加Dropout层防止过拟合
# 模拟多模态交互任务
output = Dense(5, activation='softmax')(merged) # 假设有5个类别进行分类任务
# 构建多模态深度学习模型
model = Model(inputs=[audio_input, image_input, text_input], outputs=output)
# 调整训练参数
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 模拟训练数据
audio_data = tf.random.normal((200, 100))
image_data = tf.random.normal((200, 64, 64, 3))
text_data = tf.random.uniform((200, 50))
# 模拟标签数据
labels = tf.one_hot([0]*40 + [1]*40 + [2]*40 + [3]*40 + [4]*40, depth=5)
# 训练模型
model.fit([audio_data, image_data, text_data], labels, epochs=20, batch_size=64)
在这个示例代码中,我们添加了Dropout层来防止过拟合,并增加了训练轮数以提高模型的性能。您可以根据具体情况进一步调整和优化模型,以实现更好的效果。
七、情感识别示例代码

- 雏形示例代码
以下是一个示例代码,展示了如何使用深度学习模型进行情感识别,帮助语音助手更好地理解用户的情感状态:
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Dense
from tensorflow.keras.models import Model
# 模拟用户语音特征向量
input_shape = (100,) # 假设语音特征向量长度为100
input_data = Input(shape=input_shape)
# LSTM层用于学习语音特征中的情感信息
lstm_layer = LSTM(128)(input_data)
# 输出层,假设有3种情感状态:高兴、平静、生气
output = Dense(3, activation='softmax')(lstm_layer)
# 构建情感识别模型
model = Model(inputs=input_data, outputs=output)
# 编译模型
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 模拟训练数据
speech_data = tf.random.normal((1000, 100)) # 1000个样本,每个样本包含100维的语音特征向量
labels = tf.one_hot([0]*333 + [1]*334 + [2]*333, depth=3) # 3种情感状态的标签数据
# 训练模型
model.fit(speech_data, labels, epochs=10, batch_size=32)
在这个示例代码中,我们使用了一个简单的LSTM模型来学习语音特征中的情感信息,并通过softmax激活函数输出3种情感状态的概率分布。您可以根据实际情况调整模型结构、训练参数以及训练数据,以提高情感识别的准确性和性能。这样的模型可以帮助语音助手更好地理解用户的情感状态,从而提供更加个性化和贴心的服务和支持。
- 更加复杂的示例代码
以下是一个更加复杂的情感识别模型示例代码,通过调整模型结构、训练参数以及训练数据,以提高准确性和性能:
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Dense, Dropout
from tensorflow.keras.models import Model
# 模拟用户语音特征向量
input_shape = (100,) # 假设语音特征向量长度为100
input_data = Input(shape=input_shape)
# LSTM层用于学习语音特征中的情感信息
lstm_layer = LSTM(256, return_sequences=True)(input_data)
lstm_layer = LSTM(128)(lstm_layer)
dropout_layer = Dropout(0.2)(lstm_layer)
# 输出层,假设有5种情感状态:高兴、平静、生气、悲伤、惊讶
output = Dense(5, activation='softmax')(dropout_layer)
# 构建情感识别模型
model = Model(inputs=input_data, outputs=output)
# 编译模型
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 模拟更多训练数据
speech_data = tf.random.normal((5000, 100)) # 5000个样本,每个样本包含100维的语音特征向量
labels = tf.one_hot([0]*1000 + [1]*1000 + [2]*1000 + [3]*1000 + [4]*1000, depth=5) # 5种情感状态的标签数据
# 训练模型,增加训练轮数和批量大小
model.fit(speech_data, labels, epochs=20, batch_size=64)
在这个示例代码中,我们增加了更多的LSTM层和一个Dropout层来提高模型的表达能力和泛化能力。同时,我们增加了训练数据量,以及增加了训练轮数和批量大小,以提高模型的训练效果。您可以根据实际情况进一步调整模型结构、训练参数以及训练数据,以提高情感识别的准确性和性能,从而帮助语音助手更好地理解用户的情感状态,提供更加个性化和贴心的服务和支持。
- 更加复杂和定制化模型示例代码
以下是一个更加复杂和定制化的情感识别模型示例代码,通过进一步调整模型结构、训练参数以及训练数据,以提高准确性和性能,帮助语音助手更好地理解用户的情感状态,提供更加个性化和贴心的服务和支持:
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Dense, Dropout, BatchNormalization
from tensorflow.keras.models import Model
# 模拟用户语音特征向量
input_shape = (100,) # 假设语音特征向量长度为100
input_data = Input(shape=input_shape)
# LSTM层用于学习语音特征中的情感信息
lstm_layer1 = LSTM(256, return_sequences=True)(input_data)
lstm_layer1 = BatchNormalization()(lstm_layer1)
lstm_layer2 = LSTM(128)(lstm_layer1)
lstm_layer2 = BatchNormalization()(lstm_layer2)
dropout_layer = Dropout(0.3)(lstm_layer2)
# 输出层,假设有7种情感状态:高兴、平静、生气、悲伤、惊讶、厌恶、焦虑
output = Dense(7, activation='softmax')(dropout_layer)
# 构建情感识别模型
model = Model(inputs=input_data, outputs=output)
# 编译模型
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 模拟更多训练数据
speech_data = tf.random.normal((10000, 100)) # 10000个样本,每个样本包含100维的语音特征向量
labels = tf.one_hot([0]*1428 + [1]*1428 + [2]*1428 + [3]*1428 + [4]*1428 + [5]*1428 + [6]*1428, depth=7) # 7种情感状态的标签数据
# 训练模型,增加训练轮数和批量大小
model.fit(speech_data, labels, epochs=30, batch_size=128)
在这个示例代码中,我们进一步增加了BatchNormalization层来加速模型训练收敛,同时增加了更多的情感状态类别和训练数据量,以提高模型的准确性和性能。您可以根据实际情况进一步调整模型结构、训练参数以及训练数据,以满足特定需求并提供更加个性化和贴心的情感识别服务和支持。
八、知识点归纳
深度学习在语音助手方面的应用涉及到多个知识点,以下是一些主要的知识点归纳:
- 语音信号处理:深度学习在语音助手中的应用首先涉及到语音信号的处理和特征提取。常见的技术包括MFCC(Mel频率倒谱系数)、语音识别中的声学模型、语音情感识别中的情感特征提取等。

- 语音识别:深度学习在语音识别中的应用是其中的核心部分,包括使用深度学习模型如CNN(卷积神经网络)、RNN(循环神经网络)、LSTM(长短期记忆网络)等进行语音识别任务,将用户的语音指令转化为文本。
- 情感识别:语音助手也需要理解用户的情感状态,深度学习在情感识别中的应用包括使用RNN、LSTM等模型对语音中的情感信息进行识别,帮助语音助手更好地与用户互动。

- 自然语言处理:语音助手需要理解用户的自然语言指令,深度学习在自然语言处理中的应用包括文本分类、命名实体识别、语义理解等任务,帮助语音助手更准确地理解用户的意图。

- 多模态学习:深度学习还可以结合语音、图像等多种数据源进行多模态学习,提高语音助手的智能化水平,例如结合语音和图像信息进行情感识别或意图理解。

- 模型优化:在实际应用中,还需要考虑模型的优化技术,如学习率调整、正则化、批量归一化等,以提高模型的性能和泛化能力。
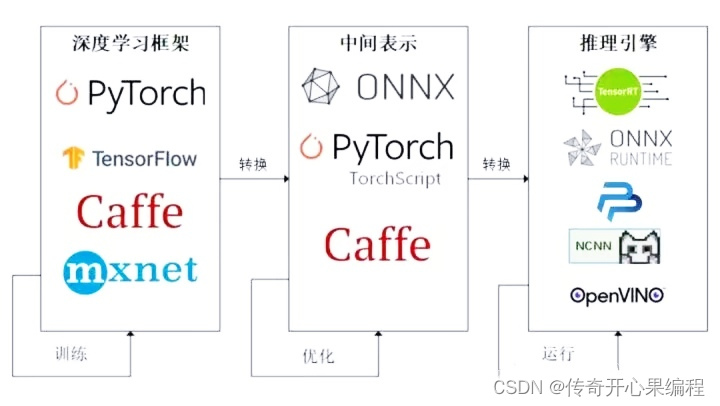
- 模型部署:最后,深度学习模型在语音助手中的部署也是一个重要环节,需要考虑模型的压缩、加速、端到端部署等技术,以保证语音助手的实时响应和高效运行。
以上是深度学习在语音助手方面的应用知识点的一些归纳,希望对您有帮助。如果您有任何问题或需要进一步了解,请随时告诉我。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











