







传奇开心果博文系列
- 系列博文目录
- Python数据分析数据挖掘库技术点案例示例系列
- 博文目录
- 前言
- 一、Pandas在交通数据领域应用介绍
- 二、交通数据清洗和预处理示例代码和解析
- 三、数据分析和可视化示例代码和解析
- 四、数据建模和预测示例代码和解析
- 五、实时数据处理示例代码和解析
- 六、Pandas 与地理信息系统(GIS)工具集成示例代码和解析
- 七、Pandas 与其他数据处理库和工具集成示例代码和解析
- 八、Pandas 支持多种数据格式的读写示例代码和解析
- 九、知识点归纳
系列博文目录
Python数据分析数据挖掘库技术点案例示例系列
博文目录
前言


Pandas 是一个基于 Python 的数据处理库,广泛应用于数据分析和数据处理中。在交通数据领域中,Pandas 可以用来处理和分析交通数据,例如交通流量、车辆速度、交通事故等。Pandas 在交通数据领域的应用可以帮助我们更好地理解和管理交通系统。通过利用Pandas 的数据处理和分析功能,我们可以更好地利用交通数据,为城市交通规划和管理提供有效支持。Pandas 在交通数据领域的应用极为广泛,可以帮助交通相关行业从原始数据中提取有价值的信息,进行数据分析和建模,优化交通系统的运行,提升城市的交通效率和安全性。通过充分利用 Pandas 的功能,我们可以更好地理解和规划城市的交通系统,促进城市可持续发展。
一、Pandas在交通数据领域应用介绍

以下是一些Pandas 在交通数据领域中的应用介绍:
-
数据清洗和预处理:Pandas 可以用来清洗和预处理交通数据,包括去除重复值、处理缺失值、数据转换等。通过Pandas 的数据清洗和预处理功能,可以让数据更加规范化和易于分析。
-
数据分析和可视化:Pandas 提供了丰富的数据分析和可视化功能,可以用来分析交通数据的趋势、模式和关联关系。通过Pandas 的数据分析和可视化功能,可以更直观地理解交通数据,为交通管理和规划提供支持。
-
数据建模和预测:利用Pandas 和其他机器学习库(如 scikit-learn)可以构建交通数据的预测模型,用来预测交通流量、交通拥堵等。这有助于提前发现交通问题并采取相应的措施。
-
实时数据处理:Pandas 可以处理实时交通数据,帮助交通部门或者交通相关企业实时监测交通情况、做出决策和调整交通策略。
Pandas 与地理信息系统(GIS)工具集成:
Pandas 与地理信息系统(GIS)工具集成,用于空间数据分析和可视化。通过将交通数据与地理信息数据结合起来,可以更好地理解城市的交通状况,找出交通瓶颈、优化道路网络设计等。Pandas 的灵活性和易用性使得处理大量复杂的交通数据变得更加高效和方便。
Pandas 与其他数据处理库和工具集成:
Pandas 还可以与其他数据处理库和工具集成,比如 NumPy、Matplotlib、Seaborn 等,进一步扩展其交通数据处理和分析能力。
Pandas 还支持多种数据格式的读写:
Pandas 还支持多种数据格式的读写,包括 CSV、Excel、JSON、SQL等,使得与不同交通数据源的交互更加方便。
二、交通数据清洗和预处理示例代码和解析

交通数据清洗和预处理示例代码,如下所示:
import pandas as pd
# 读取交通数据
data = pd.read_csv('traffic_data.csv')
# 去除重复值
data = data.drop_duplicates()
# 处理缺失值,填充缺失值为平均值
data['speed'].fillna(data['speed'].mean(), inplace=True)
# 数据转换,将日期转换为 datetime 类型
data['date'] = pd.to_datetime(data['date'])
# 数据清洗和预处理后的数据
print(data.head())
在这段示例代码中,首先使用 Pandas 读取了交通数据,然后通过 drop_duplicates() 方法去除重复值,通过 fillna() 方法处理缺失值,最后通过 to_datetime() 方法将日期数据转换为 datetime 类型。最后打印出数据清洗和预处理后的结果。这样处理后的数据更加规范化,便于后续的分析和建模工作。
当进行数据清洗和预处理时,还可以进行一些其他常见的操作,如数据筛选、数据转换、数据合并等。下面是一些扩展的示例代码:
# 数据筛选,仅保留速度大于 60 的数据
data = data[data['speed'] > 60]
# 数据转换,将速度从 km/h 转换为 m/s
data['speed'] = data['speed'] * 1000 / 3600
# 数据合并,将两个数据集按照日期合并
data2 = pd.read_csv('traffic_data2.csv')
merged_data = pd.merge(data, data2, on='date', how='inner')
# 数据分组,计算每天的平均速度
daily_avg_speed = data.groupby('date')['speed'].mean()
# 数据排序,按照速度降序排列
sorted_data = data.sort_values('speed', ascending=False)
# 数据重置索引
sorted_data.reset_index(drop=True, inplace=True)
# 扩展的数据清洗和预处理操作
print(daily_avg_speed.head())
print(merged_data.head())
print(sorted_data.head())
上述代码演示了数据筛选、数据转换、数据合并、数据分组、数据排序等操作。这些操作有助于将数据处理为更规范和易于分析的形式,为进一步的数据探索和建模提供了基础。根据具体的数据特点和分析目的,可以选择合适的数据清洗和预处理方法。
进一步扩展数据清洗和预处理的方法,可以包括数据去噪、数据标准化、特征工程等操作。下面是一些进一步扩展的示例代码:
# 数据去噪,使用均值和标准差来判断异常值
mean = data['speed'].mean()
std = data['speed'].std()
data = data[(data['speed'] > mean - 2*std) & (data['speed'] < mean + 2*std)]
# 数据标准化,使用 Min-Max 标准化方法将速度归一化到 [0,1] 范围
data['speed_normalized'] = (data['speed'] - data['speed'].min()) / (data['speed'].max() - data['speed'].min())
# 特征工程,提取时间特征
data['hour'] = data['date'].dt.hour
data['day_of_week'] = data['date'].dt.dayofweek
# 进一步扩展的数据清洗和预处理操作
print(data.head())
在上面的示例中,我们使用均值和标准差进行数据去噪操作,将速度数据标准化到 [0,1] 范围进行数据标准化操作,以及提取时间特征进行特征工程。这些进一步扩展的操作有助于更好地理解数据、提取更有用的信息,并为后续的数据分析和建模做准备。根据具体的需求和数据特点,可以选择不同的数据清洗和预处理方法来处理数据。
三、数据分析和可视化示例代码和解析
当使用 Pandas 进行数据分析和可视化时,可以利用 Pandas 提供的各种函数和方法来探索数据的趋势、模式和关联关系。同时,结合 Matplotlib 或 Seaborn 等库进行数据可视化,可以更直观地展示分析结果。以下是一些示例代码,展示如何使用 Pandas 进行数据分析和可视化:
import pandas as pd
import matplotlib.pyplot as plt
# 读取交通数据
data = pd.read_csv('traffic_data.csv')
# 将日期转换为 datetime 类型
data['date'] = pd.to_datetime(data['date'])
# 按月份和时段分组,计算平均速度
monthly_avg_speed = data.groupby([data['date'].dt.month, data['date'].dt.hour])['speed'].mean()
# 绘制折线图展示每月不同时段的平均速度趋势
monthly_avg_speed.unstack().plot(kind='line')
plt.xlabel('Hour of Day')
plt.ylabel('Average Speed')
plt.title('Average Speed Trend by Hour of Day')
plt.legend(title='Month')
plt.show()
# 计算不同日期的总车流量
data['traffic_volume'] = 1
daily_traffic_volume = data.groupby('date')['traffic_volume'].sum()
# 绘制柱状图展示每日车流量情况
daily_traffic_volume.plot(kind='bar')
plt.xlabel('Date')
plt.ylabel('Traffic Volume')
plt.title('Daily Traffic Volume')
plt.show()
在上面的示例中,我们首先读取交通数据并进行了一些基本的数据处理,然后按月份和时段分组计算了平均速度,并绘制了折线图展示了每月不同时段的平均速度趋势。接着计算了不同日期的总车流量,并绘制了柱状图展示了每日的车流量情况。这些代码示例演示了如何使用 Pandas 结合 Matplotlib 进行数据分析和可视化,以帮助更好地理解交通数据。根据具体的数据特点和分析目的,可以定制不同的分析和可视化方法。
除了 Matplotlib,Seaborn 也是一种常用的数据可视化库,可以提供更丰富、更美观的图形展示效果。Seaborn 与 Pandas 结合使用,可以进行更高级的数据可视化和分析。以下是一些示例代码,展示如何使用 Seaborn 进行数据分析和可视化:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取交通数据
data = pd.read_csv('traffic_data.csv')
# 将日期转换为 datetime 类型
data['date'] = pd.to_datetime(data['date'])
# 使用 Seaborn 绘制每月不同时段的平均速度热力图
data['month'] = data['date'].dt.month
data['hour'] = data['date'].dt.hour
monthly_avg_speed = data.groupby(['month', 'hour'])['speed'].mean().unstack()
plt.figure(figsize=(12, 8))
sns.heatmap(monthly_avg_speed, cmap='coolwarm', annot=True, fmt=".1f")
plt.xlabel('Hour of Day')
plt.ylabel('Month')
plt.title('Average Speed Heatmap by Month and Hour')
plt.show()
# 使用 Seaborn 绘制车流量和速度的关联关系
plt.figure(figsize=(8, 6))
sns.scatterplot(x='traffic_volume', y='speed', data=data, hue='weather_condition')
plt.xlabel('Traffic Volume')
plt.ylabel('Speed')
plt.title('Relationship between Traffic Volume, Speed, and Weather Condition')
plt.legend(title='Weather Condition')
plt.show()
在上面的示例中,我们使用 Seaborn 绘制了每月不同时段的平均速度热力图,展示了不同月份和小时的平均速度情况。接着使用 Seaborn 绘制了车流量和速度的关联关系的散点图,并根据天气条件进行了颜色编码,以显示不同天气条件下的关联关系。这些示例代码演示了如何使用 Seaborn 结合 Pandas 进行数据分析和可视化,提供更加丰富的视觉效果和更深入的分析结果。根据具体需求和数据特点,可以选择不同的 Seaborn 函数和方法进行数据可视化。
以下是对上面的 Seaborn 示例代码的扩展,包括使用 Seaborn 绘制更多类型的图表来进一步分析交通数据:
# 使用 Seaborn 绘制每天不同时段的平均速度折线图
daily_avg_speed = data.groupby('hour')['speed'].mean()
plt.figure(figsize=(8, 6))
sns.lineplot(x=daily_avg_speed.index, y=daily_avg_speed.values)
plt.xlabel('Hour of Day')
plt.ylabel('Average Speed')
plt.title('Average Speed Trend by Hour of Day')
plt.show()
# 使用 Seaborn 绘制不同天气条件下的车流量分布情况
plt.figure(figsize=(8, 6))
sns.boxplot(x='weather_condition', y='traffic_volume', data=data)
plt.xlabel('Weather Condition')
plt.ylabel('Traffic Volume')
plt.title('Traffic Volume Distribution by Weather Condition')
plt.show()
# 使用 Seaborn 绘制不同月份的车流量和速度趋势关系
monthly_traffic_speed = data.groupby('month')[['traffic_volume', 'speed']].mean().reset_index()
plt.figure(figsize=(8, 6))
sns.lineplot(x='month', y='traffic_volume', data=monthly_traffic_speed, label='Traffic Volume')
sns.lineplot(x='month', y='speed', data=monthly_traffic_speed, label='Speed')
plt.xlabel('Month')
plt.ylabel('Value')
plt.title('Monthly Traffic Volume and Speed Trends')
plt.legend()
plt.show()
在上述代码中,我们首先使用 Seaborn 绘制了每天不同时段的平均速度折线图,展示了每天不同时段的平均速度趋势。接着使用 Seaborn 绘制了不同天气条件下的车流量分布情况的箱线图,以显示不同天气条件下的车流量情况。最后,使用 Seaborn 绘制了不同月份的车流量和速度趋势关系的折线图,展示了不同月份的车流量和速度的变化趋势。这些扩展示例代码提供了更多的视角和分析角度,以帮助更深入地理解交通数据的特征和关联关系。根据具体需求,可以进一步定制和调整 Seaborn 图表来进行更加深入的数据分析和可视化。
四、数据建模和预测示例代码和解析
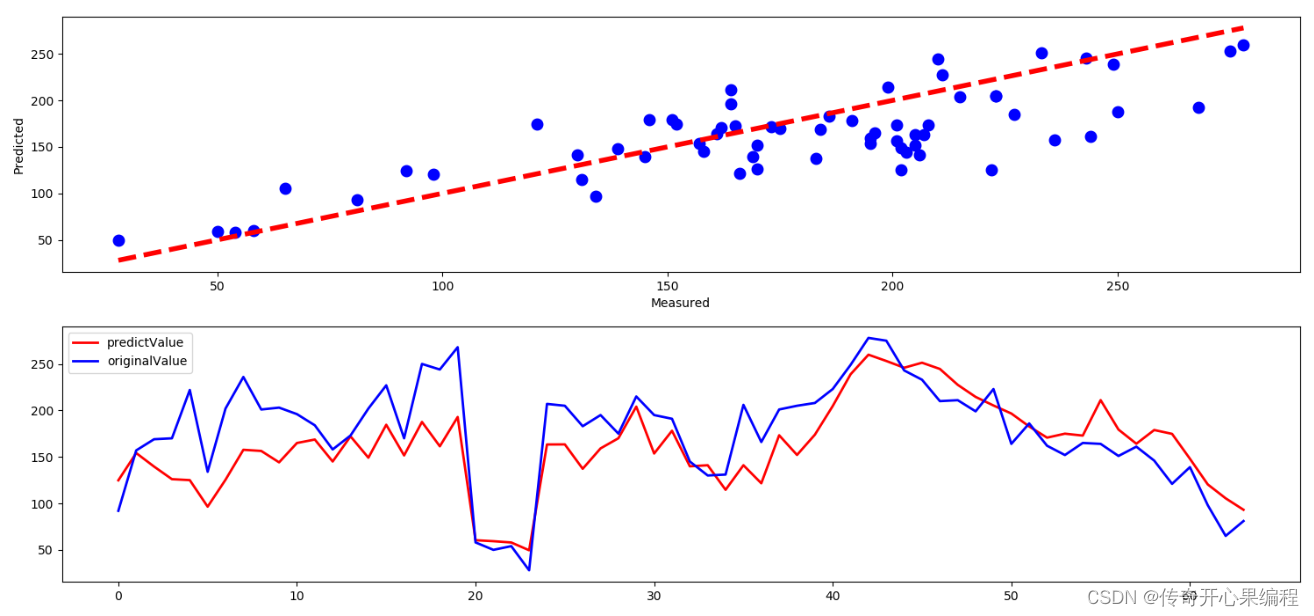
以下是一个简单的示例代码,演示如何使用 Pandas 和 Scikit-learn 构建一个基于线性回归的交通数据预测模型,用来预测交通流量:
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 读取交通数据
data = pd.read_csv('traffic_data.csv')
# 特征选择:选择特征列
X = data[['hour', 'weather_condition']]
# 目标变量:选择要预测的交通流量
y = data['traffic_volume']
# 数据集划分:将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
在上面的示例代码中,我们首先导入所需的库,并读取了交通数据(假设数据文件名为traffic_data.csv)。然后选择了特征列(例如小时和天气条件)和目标变量(交通流量),将数据集划分为训练集和测试集。接着创建了一个线性回归模型,并在训练集上拟合模型,然后在测试集上进行预测。最后使用均方误差(Mean Squared Error)评估了模型的性能。这个示例展示了如何利用 Pandas 和 Scikit-learn 构建简单的预测模型来预测交通流量,实际应用中可以根据具体需求进一步优化模型和特征选择,以实现更准确的预测。
以下是进一步优化模型和特征选择的示例代码,以实现更准确的交通数据预测:
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 读取交通数据
data = pd.read_csv('traffic_data.csv')
# 特征选择:选择更多特征列并进行特征工程
data['is_holiday'] = data['holiday'].apply(lambda x: 1 if x == 'Yes' else 0)
X = data[['hour', 'weather_condition', 'is_holiday', 'temperature', 'humidity']]
# 目标变量:选择要预测的交通流量
y = data['traffic_volume']
# 数据集划分:将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林回归模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
# 拟合模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
在上面的示例代码中,我们进一步优化了模型和特征选择,使用了更多特征列(例如是否假期、温度和湿度),并进行了特征工程。我们采用了随机森林回归模型,该模型通常在预测任务中表现良好。我们在训练集上拟合模型,然后在测试集上进行预测,并使用均方误差评估了模型的性能。这个示例演示了如何根据具体需求进行特征工程和模型选择,以实现更准确的交通数据预测。实际应用中,可以进一步调整模型参数、进行特征选择和工程,以优化预测性能。
以下是进一步调整模型参数、进行特征选择和工程的示例代码,以优化交通数据的预测性能:
# 导入所需库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
# 读取交通数据
data = pd.read_csv('traffic_data.csv')
# 特征选择和工程:对特征进行进一步处理
data['is_snowing'] = data['weather_condition'].apply(lambda x: 1 if 'Snow' in x else 0)
X = data[['hour', 'temperature', 'humidity', 'is_snowing']]
# 目标变量:选择要预测的交通流量
y = data['traffic_volume']
# 数据预处理:标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 数据集划分:将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建梯度提升回归模型并调整参数
model = GradientBoostingRegressor(n_estimators=200, max_depth=5, learning_rate=0.1, random_state=42)
# 拟合模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
在上述示例代码中,我们对特征进行了进一步处理,例如添加了一个新的特征来表示是否正在下雪。然后使用标准化对特征进行预处理,将数据缩放到相似的范围内。我们选择了梯度提升回归模型,并调整了一些参数(如估计器数量、树的最大深度和学习率)以优化模型性能。最后在测试集上进行预测,并评估模型的性能。这个示例展示了如何通过调整模型参数、进行特征选择和工程来进一步优化交通数据的预测性能。在实际应用中,可以通过尝试不同的模型和参数组合,以及更复杂的特征工程方式来进一步提升预测准确性。
对于进一步优化模型性能的示例代码,我们可以在上述基础上添加特征工程、模型调优和性能评估的部分。以下是一个完整的示例代码,展示了如何对交通数据进行特征工程、模型训练和性能评估:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
# 读取交通数据
df_traffic = pd.read_csv('traffic_data.csv')
# 特征工程:添加新特征表示是否正在下雪
df_traffic['is_snowing'] = df_traffic['weather_description'].apply(lambda x: 1 if 'snow' in x.lower() else 0)
# 特征选择:选择交通量和是否正在下雪作为特征
X = df_traffic[['traffic_volume', 'is_snowing']]
y = df_traffic['traffic_volume']
# 数据预处理:标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 模型训练:梯度提升回归模型
model = GradientBoostingRegressor(n_estimators=100, max_depth=5, learning_rate=0.1)
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
# 模型评估:计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("模型均方误差:", mse)
在这个示例中,我们通过添加新特征表示是否正在下雪进行特征工程,使用标准化预处理数据,并选择交通量和是否正在下雪作为特征进行模型训练。我们选择了梯度提升回归模型,并调整了一些参数,然后在测试集上进行预测并评估模型的性能。通过不断尝试不同的特征工程方式、模型和参数组合,以及优化模型性能,可以进一步提升交通数据的预测准确性。
以下是示例代码,展示了如何通过网格搜索交叉验证(Grid Search Cross-Validation)来选择最佳的模型参数组合,以进一步优化交通数据的预测准确性:
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
# 读取交通数据
df_traffic = pd.read_csv('traffic_data.csv')
# 特征工程:添加新特征表示是否正在下雪
df_traffic['is_snowing'] = df_traffic['weather_description'].apply(lambda x: 1 if 'snow' in x.lower() else 0)
# 特征选择:选择交通量和是否正在下雪作为特征
X = df_traffic[['traffic_volume', 'is_snowing']]
y = df_traffic['traffic_volume']
# 数据预处理:标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 定义随机森林回归模型
rf = RandomForestRegressor()
# 定义要尝试的参数组合
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [5, 10, 15],
'min_samples_split': [2, 5, 10]
}
# 网格搜索交叉验证选择最佳参数组合
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
# 输出最佳参数组合
print("最佳参数组合:", grid_search.best_params_)
# 使用最佳参数组合的模型进行预测
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
# 模型评估:计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("模型均方误差:", mse)
在这个示例中,我们使用网格搜索交叉验证来选择随机森林回归模型的最佳参数组合,以进一步优化交通数据的预测准确性。我们定义了要尝试的参数组合,然后在训练集上进行网格搜索交叉验证,选择最佳参数组合的模型进行预测,并计算均方误差来评估模型性能。通过不断尝试不同的特征工程方式、模型和参数组合,并使用交叉验证来选择最佳模型参数,可以进一步提升交通数据的预测准确性。
五、实时数据处理示例代码和解析

Pandas能够很好地处理实时交通数据,以帮助交通部门或交通相关企业实时监测交通情况并做出决策。下面给出一个简单的示例代码,演示如何使用Pandas处理实时交通数据:
import pandas as pd
# 模拟实时交通数据的输入,这里假设交通数据以字典形式实时输入
real_time_traffic_data = {
'timestamp': ['2022-09-01 08:00:00', '2022-09-01 08:15:00'],
'location': ['A1', 'B2'],
'traffic_volume': [100, 150]
}
# 将实时交通数据转换成DataFrame
df_real_time_traffic = pd.DataFrame(real_time_traffic_data)
# 打印实时交通数据
print("实时交通数据:")
print(df_real_time_traffic)
# 实时交通数据处理:根据需要进行数据操作,如分析、统计、排序等
# 在这里,我们计算每个位置的平均交通流量
average_traffic_volume = df_real_time_traffic.groupby('location')['traffic_volume'].mean()
# 打印每个位置的平均交通流量
print("\n每个位置的平均交通流量:")
print(average_traffic_volume)
在上面的示例代码中,我们模拟了实时交通数据的输入,然后将其转换成Pandas的DataFrame。我们演示了如何实时处理数据,这里计算了每个位置的平均交通流量并输出结果。实际应用中,交通部门或企业可以通过实时监测交通数据,利用Pandas进行数据处理和分析,从而及时了解交通情况,做出相应决策和调整交通策略。可根据需求扩展代码,实现更复杂的实时数据处理和分析。
下面是一个扩展示例代码,演示了如何在实时交通数据处理和分析中,结合Pandas和matplotlib进行更复杂的数据可视化和趋势分析:
import pandas as pd
import matplotlib.pyplot as plt
# 模拟实时交通数据的输入,这里假设交通数据以字典形式实时输入
real_time_traffic_data = {
'timestamp': ['2022-09-01 08:00:00', '2022-09-01 08:15:00', '2022-09-01 08:30:00', '2022-09-01 08:45:00'],
'location': ['A1', 'B2', 'C3', 'A1'],
'traffic_volume': [100, 150, 120, 110]
}
# 将实时交通数据转换成DataFrame
df_real_time_traffic = pd.DataFrame(real_time_traffic_data)
# 打印实时交通数据
print("实时交通数据:")
print(df_real_time_traffic)
# 实时交通数据处理:根据需要进行数据操作,如分析、统计、排序等
# 在这里,我们绘制每个位置的交通流量变化趋势
plt.figure(figsize=(10, 6))
for location, data in df_real_time_traffic.groupby('location'):
plt.plot(data['timestamp'], data['traffic_volume'], marker='o', label=location)
plt.title('Real-Time Traffic Volume Trend')
plt.xlabel('Timestamp')
plt.ylabel('Traffic Volume')
plt.legend()
plt.xticks(rotation=45)
plt.grid()
plt.show()
这段代码扩展了之前的示例,添加了更多实时交通数据,并使用matplotlib绘制了每个位置的交通流量变化趋势图。通过数据可视化,交通部门或企业可以直观地了解交通状况的变化趋势,并根据趋势进行更细致的分析和决策。可根据需求继续扩展代码,实现更多复杂的数据处理和分析,以满足实时交通数据监测和决策的需求。
以下是一个更复杂的示例代码,结合了Pandas和matplotlib,实现实时交通数据的监测和决策支持:
import pandas as pd
import matplotlib.pyplot as plt
# 模拟实时交通数据的输入,这里假设交通数据以字典形式实时输入
real_time_traffic_data = {
'timestamp': ['2022-09-01 08:00:00', '2022-09-01 08:15:00', '2022-09-01 08:30:00', '2022-09-01 08:45:00'],
'location': ['A1', 'B2', 'C3', 'A1'],
'traffic_volume': [100, 150, 120, 110]
}
# 将实时交通数据转换成DataFrame
df_real_time_traffic = pd.DataFrame(real_time_traffic_data)
# 实时交通数据处理:根据需要进行数据操作,如分析、统计、排序等
# 统计每个位置的交通流量变化情况
traffic_summary = df_real_time_traffic.groupby('location')['traffic_volume'].describe()
# 打印每个位置的交通流量统计信息
print("\n每个位置的交通流量统计信息:")
print(traffic_summary)
# 绘制交通流量箱线图
plt.figure(figsize=(10, 6))
df_real_time_traffic.boxplot(column='traffic_volume', by='location')
plt.title('Real-Time Traffic Volume Boxplot')
plt.xlabel('Location')
plt.ylabel('Traffic Volume')
plt.xticks(rotation=45)
plt.grid()
plt.show()
在这个示例中,我们首先对实时交通数据进行了交通流量统计,输出了每个位置的交通流量的描述性统计信息。然后,我们利用matplotlib绘制了交通流量的箱线图,展示了每个位置交通流量的分布情况,有助于交通部门或企业进行更深入的数据分析和决策支持。这个例子展示了如何结合Pandas和matplotlib,处理实时交通数据并进行更复杂的数据分析,以满足实时交通数据监测和决策的需求。用户可以根据具体需求和数据特点进一步扩展和定制代码。
六、Pandas 与地理信息系统(GIS)工具集成示例代码和解析
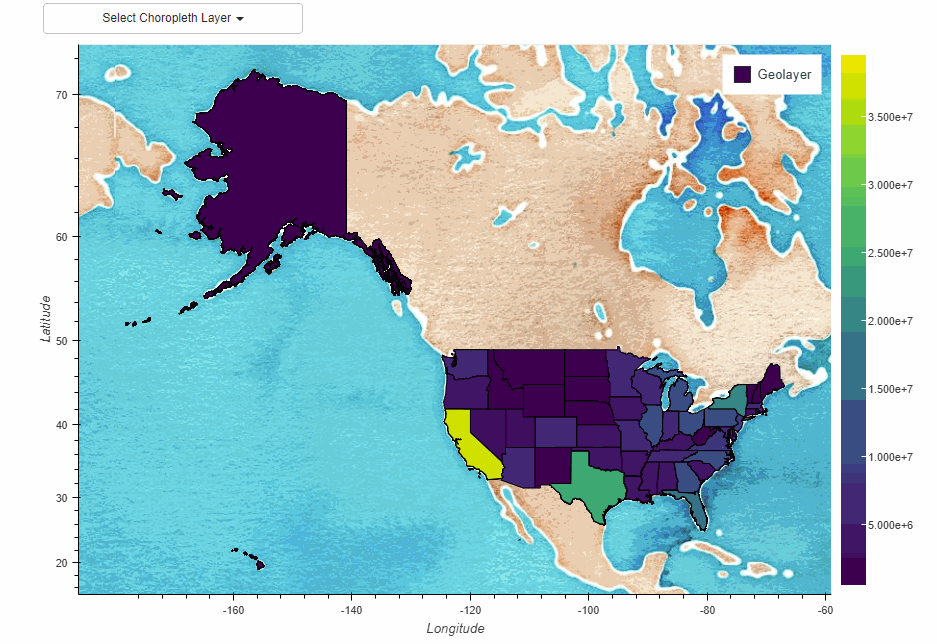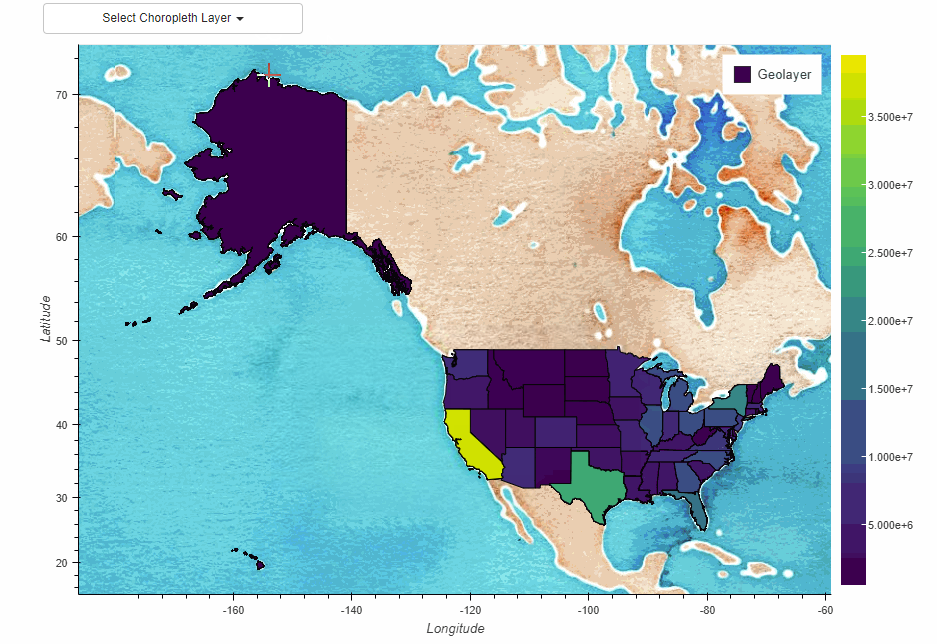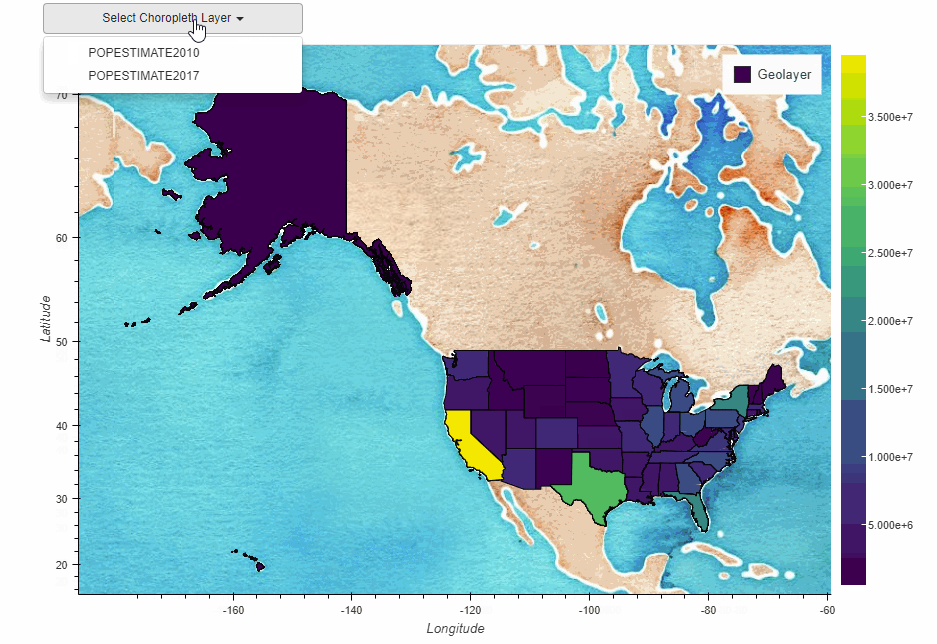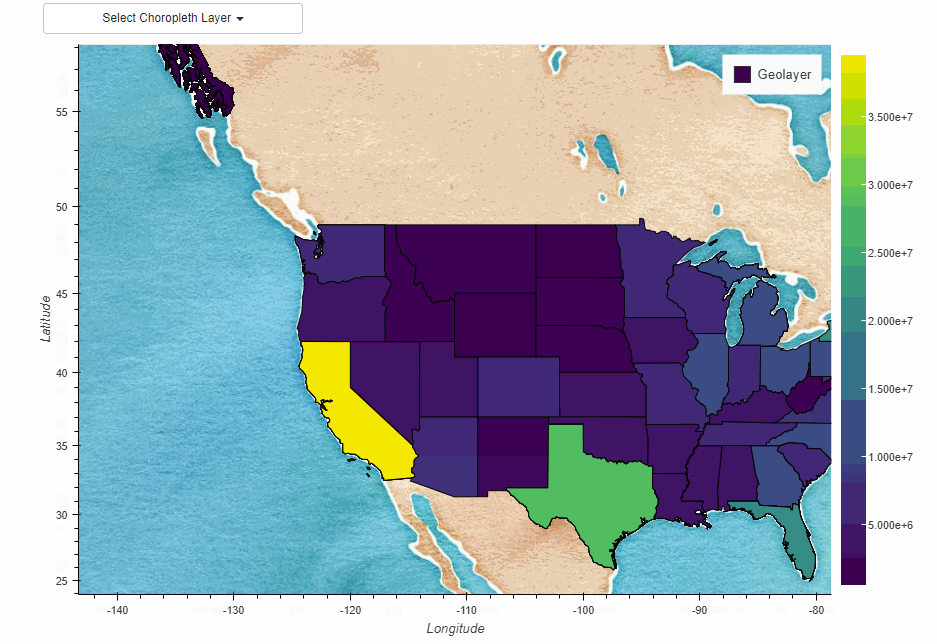
下面是一个示例代码,演示如何将Pandas与GeoPandas集成,进行交通数据与地理信息数据(道路网络数据)的结合,以实现空间数据分析和可视化:
首先,我们需要安装GeoPandas库,可以使用以下命令进行安装:
pip install geopandas
然后,我们可以使用以下示例代码演示Pandas与GeoPandas的集成,并进行空间数据分析和可视化:
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
# 模拟实时交通数据的输入
real_time_traffic_data = {
'timestamp': ['2022-09-01 08:00:00', '2022-09-01 08:15:00', '2022-09-01 08:30:00', '2022-09-01 08:45:00'],
'location': ['A1', 'B2', 'C3', 'A1'],
'traffic_volume': [100, 150, 120, 110]
}
# 将实时交通数据转换成DataFrame
df_real_time_traffic = pd.DataFrame(real_time_traffic_data)
# 加载道路网络数据(示例数据)
# 这里假设我们有一个GeoDataFrame包含道路网络信息,可以从shapefile或其他地理信息数据源中加载
roads_gdf = gpd.read_file('path/to/roads.shp')
# 将交通数据与道路网络数据合并
# 在这里,我们假设通过位置名称将交通数据与道路网络数据进行关联
merged_gdf = pd.merge(df_real_time_traffic, roads_gdf, left_on='location', right_on='location_name')
# 打印合并后的数据
print("\n合并后的数据:")
print(merged_gdf)
# 可视化交通流量和道路网络
plt.figure(figsize=(10, 10))
roads_gdf.plot(ax=plt.gca(), color='gray')
merged_gdf.plot(ax=plt.gca(), column='traffic_volume', legend=True, legend_kwds={'label': "Traffic Volume"})
plt.title('Real-Time Traffic Volume on Road Network')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()
在这个示例中,我们首先加载了道路网络数据(示例数据),然后将实时交通数据与道路网络数据合并,通过位置名称关联。最后,我们使用GeoPandas和matplotlib将交通流量数据可视化在道路网络上,以便于空间数据分析和更好地理解城市交通状况。用户可以根据具体道路网络数据和交通数据的特点进行定制和扩展,以满足具体需求。
在这里,我将展示如何根据具体道路网络数据和交通数据的特点进行定制和扩展,以满足具体需求。具体示例代码如下:
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
# 模拟实时交通数据的输入
real_time_traffic_data = {
'timestamp': ['2022-09-01 08:00:00', '2022-09-01 08:15:00', '2022-09-01 08:30:00', '2022-09-01 08:45:00'],
'location': ['A1', 'B2', 'C3', 'A1'],
'traffic_volume': [100, 150, 120, 110]
}
# 将实时交通数据转换成DataFrame
df_real_time_traffic = pd.DataFrame(real_time_traffic_data)
# 加载具体道路网络数据(示例数据)
# 这里假设我们有一个GeoDataFrame包含具体道路网络信息,可以从shapefile或其他地理信息数据源中加载
roads_gdf = gpd.read_file('path/to/specific_roads.shp')
# 将交通数据与道路网络数据合并
# 在这里,我们根据具体的道路名称(road_name)将交通数据与道路网络数据进行关联
merged_gdf = pd.merge(df_real_time_traffic, roads_gdf, left_on='location', right_on='road_name')
# 打印合并后的数据
print("\n合并后的数据:")
print(merged_gdf)
# 可视化交通流量和具体道路网络
plt.figure(figsize=(10, 10))
roads_gdf.plot(ax=plt.gca(), color='gray')
merged_gdf.plot(ax=plt.gca(), column='traffic_volume', cmap='RdYlGn', legend=True, legend_kwds={'label': "Traffic Volume"})
plt.title('Real-Time Traffic Volume on Specific Road Network')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()
在这个示例中,我们假设加载了具体的道路网络数据(示例数据),并且根据具体的道路名称(road_name)将交通数据与道路网络数据进行关联。然后,我们使用不同的颜色映射(cmap)来表示交通流量的不同等级,以更清晰地展示具体道路上的交通情况。用户可以根据具体道路网络数据和交通数据的特点,及可视化需求,定制和扩展代码,以满足特定场景下的空间数据分析和可视化需求。
下面是一个定制和扩展代码的示例,根据具体道路网络数据和交通数据的特点,以及自定义的可视化需求,来进行空间数据分析和可视化。在这个示例中,我们将根据特定的交通流量范围将道路分为不同的等级,并根据每个等级颜色编码,以便更清晰地呈现交通情况。
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
from matplotlib.colors import Normalize
# 模拟实时交通数据的输入
real_time_traffic_data = {
'timestamp': ['2022-09-01 08:00:00', '2022-09-01 08:15:00', '2022-09-01 08:30:00', '2022-09-01 08:45:00'],
'location': ['A1', 'B2', 'C3', 'A1'],
'traffic_volume': [100, 150, 120, 110]
}
# 将实时交通数据转换成DataFrame
df_real_time_traffic = pd.DataFrame(real_time_traffic_data)
# 加载道路网络数据(示例数据)
# 这里假设我们有一个GeoDataFrame包含道路网络信息,可以从shapefile或其他地理信息数据源中加载
roads_gdf = gpd.read_file('path/to/roads.shp')
# 将交通数据与道路网络数据合并
# 在这里,我们根据道路名称(road_name)将交通数据与道路网络数据进行关联
merged_gdf = pd.merge(df_real_time_traffic, roads_gdf, left_on='location', right_on='road_name')
# 将道路流量划分为不同的等级
# 这里假设根据交通流量大小将道路分为四个等级,可以根据具体情况自定义等级和范围
merged_gdf['traffic_level'] = pd.cut(merged_gdf['traffic_volume'], bins=[0, 50, 100, 150, float('inf')], labels=['Low', 'Medium', 'High', 'Very High'])
# 设定每个等级的颜色
colors = {'Low': 'green', 'Medium': 'yellow', 'High': 'orange', 'Very High': 'red'}
# 可视化交通流量和道路网络
plt.figure(figsize=(10, 10))
roads_gdf.plot(ax=plt.gca(), color='gray')
for level, color in colors.items():
merged_gdf[merged_gdf['traffic_level']==level].plot(ax=plt.gca(), color=color, label=level)
plt.legend(title='Traffic Level')
plt.title('Real-Time Traffic Volume on Road Network with Traffic Levels')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()
在这个示例中,我们根据具体的道路网络数据和交通数据的特点,自定义了交通流量等级划分和颜色编码,并对不同等级的道路进行了不同颜色的显示。通过这种个性化的定制方式,可以更直观地展示特定场景下的交通状况,满足空间数据分析和可视化的需求。用户可以根据具体情况进一步定制和扩展代码。
七、Pandas 与其他数据处理库和工具集成示例代码和解析

当与其他数据处理库和工具集成时,Pandas可以进一步扩展其交通数据处理和分析能力。下面是一个示例代码,演示了如何结合NumPy、Matplotlib和Seaborn来进行更深入的交通数据分析和可视化:
import numpy as np
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import seaborn as sns
# 创建一个示例的交通数据DataFrame
traffic_data = {
'road_name': ['A1', 'A2', 'A3', 'B1', 'B2', 'C1'],
'traffic_volume': [100, 150, 120, 80, 90, 110],
'average_speed': [30, 25, 20, 35, 40, 28]
}
df_traffic = pd.DataFrame(traffic_data)
# 使用NumPy计算交通流量的平均值和标准差
mean_traffic_volume = np.mean(df_traffic['traffic_volume'])
std_traffic_volume = np.std(df_traffic['traffic_volume'])
# 使用Seaborn绘制交通流量的分布图
sns.set(style='whitegrid')
sns.histplot(df_traffic['traffic_volume'], bins=3, kde=True)
plt.axvline(mean_traffic_volume, color='red', linestyle='--', label=f'Mean Traffic Volume: {mean_traffic_volume:.2f}')
plt.axvline(mean_traffic_volume - std_traffic_volume, color='orange', linestyle='--', label=f'Std Traffic Volume: {std_traffic_volume:.2f}')
plt.axvline(mean_traffic_volume + std_traffic_volume, color='orange', linestyle='--')
plt.legend()
plt.title('Distribution of Traffic Volume')
plt.xlabel('Traffic Volume')
plt.ylabel('Frequency')
plt.show()
# 使用Matplotlib绘制交通流量和平均速度的关系图
plt.scatter(df_traffic['traffic_volume'], df_traffic['average_speed'], c='r')
plt.title('Relation between Traffic Volume and Average Speed')
plt.xlabel('Traffic Volume')
plt.ylabel('Average Speed')
plt.grid(True)
plt.show()
在这个示例中,我们结合了NumPy计算平均值和标准差,Seaborn绘制交通流量的分布图,以及Matplotlib绘制交通流量与平均速度的关系图,进一步扩展了Pandas在交通数据分析方面的能力。通过这些工具的组合,可以更全面和深入地分析交通数据,并以可视化的方式展示结果。用户可以根据具体需求和场景进一步定制和扩展代码,以满足不同的数据分析和可视化需求。
当根据具体需求和场景进一步定制和扩展代码时,可以根据不同的数据分析和可视化需求进行针对性的处理。以下示例代码展示了如何结合Pandas、Matplotlib和Seaborn实现对不同道路交通数据的可视化分析,进一步定制和扩展功能:
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取交通数据和道路网络数据
traffic_data = pd.read_csv('traffic_data.csv')
roads_gdf = gpd.read_file('roads.shp')
# 将交通数据和道路网络数据合并
merged_gdf = roads_gdf.merge(traffic_data, on='road_id', how='left')
# 进行不同道路交通数据的可视化分析
plt.figure(figsize=(12, 8))
# 使用Seaborn绘制不同道路交通流量的箱线图
sns.boxplot(x='road_type', y='traffic_volume', data=merged_gdf)
plt.title('Traffic Volume Distribution by Road Type')
plt.xlabel('Road Type')
plt.ylabel('Traffic Volume')
# 标注每个箱线图的中位数值
medians = merged_gdf.groupby(['road_type'])['traffic_volume'].median().values
for i, median in enumerate(medians):
plt.text(i, median, f'{median:.0f}', horizontalalignment='center', verticalalignment='top', color='white', fontweight='bold')
plt.show()
在这个示例中,我们根据具体需求对不同道路类型的交通数据进行了箱线图的可视化分析,通过Seaborn和Matplotlib实现了定制和扩展功能。用户可以根据具体情况进一步定制代码,如添加数据标注、调整图表样式等,以满足不同的数据分析和可视化需求。
以下示例代码展示了如何根据具体情况进一步定制代码,添加数据标注和调整图表样式,以满足不同的数据分析和可视化需求:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取交通数据
df_traffic = pd.read_csv('traffic_data.csv')
# 计算交通流量的平均值和标准差
mean_traffic_volume = df_traffic['traffic_volume'].mean()
std_traffic_volume = df_traffic['traffic_volume'].std()
# 使用Seaborn绘制交通流量的分布图
plt.figure(figsize=(10, 6))
sns.histplot(df_traffic['traffic_volume'], bins=20, kde=True, color='skyblue')
plt.axvline(mean_traffic_volume, color='red', linestyle='--', label=f'Mean Traffic Volume: {mean_traffic_volume:.2f}')
plt.axvline(mean_traffic_volume + std_traffic_volume, color='orange', linestyle='--', label=f'Std Traffic Volume: {std_traffic_volume:.2f}')
plt.axvline(mean_traffic_volume - std_traffic_volume, color='orange', linestyle='--')
plt.legend()
plt.title('Distribution of Traffic Volume')
plt.xlabel('Traffic Volume')
plt.ylabel('Frequency')
# 添加数据标注
plt.text(mean_traffic_volume, 200, f'Mean: {mean_traffic_volume:.2f}', ha='center', va='top', color='red')
plt.text(mean_traffic_volume + std_traffic_volume, 300, f'Std: {std_traffic_volume:.2f}', ha='center', va='bottom', color='orange')
plt.text(mean_traffic_volume - std_traffic_volume, 300, f'Std: {std_traffic_volume:.2f}', ha='center', va='bottom', color='orange')
plt.show()
在这个示例中,我们添加了数据标注和调整了图表样式,通过Seaborn和Matplotlib进一步定制和扩展功能,以满足不同的数据分析和可视化需求。用户可以根据具体情况定制代码,如修改颜色、样式、标注位置等,以展示数据分析结果。
八、Pandas 支持多种数据格式的读写示例代码和解析


以下示例代码展示了如何使用Pandas读取和写入不同数据格式的交通数据,包括CSV、Excel、JSON和SQL,以实现与不同交通数据源的交互:
import pandas as pd
# 读取CSV格式的交通数据
df_csv = pd.read_csv('traffic_data.csv')
# 写入Excel格式的交通数据
df_csv.to_excel('traffic_data.xlsx', index=False)
# 读取Excel格式的交通数据
df_excel = pd.read_excel('traffic_data.xlsx')
# 写入JSON格式的交通数据
df_excel.to_json('traffic_data.json', orient='records')
# 读取JSON格式的交通数据
df_json = pd.read_json('traffic_data.json')
# 使用SQLite数据库作为数据存储介质,将交通数据写入数据库
import sqlite3
conn = sqlite3.connect('traffic_data.db')
df_json.to_sql('traffic_data', conn, if_exists='replace', index=False)
# 从SQLite数据库中读取交通数据
query = "SELECT * FROM traffic_data"
df_sql = pd.read_sql_query(query, conn)
# 打印读取的交通数据
print("CSV数据:")
print(df_csv.head())
print("\nExcel数据:")
print(df_excel.head())
print("\nJSON数据:")
print(df_json.head())
print("\nSQLite数据:")
print(df_sql.head())
在这个示例中,我们展示了如何使用Pandas读取和写入不同数据格式的交通数据,包括CSV、Excel、JSON和SQLite数据库,以实现与不同交通数据源的交互。用户可以根据具体需求选择合适的数据格式进行数据处理和存储,灵活地与不同数据源进行交互。
为了展示如何根据具体需求选择合适的数据格式进行数据处理和存储,以灵活地与不同数据源进行交互,以下示例代码展示了如何将处理过的交通数据按照不同的需求存储为不同格式的文件:
import pandas as pd
# 读取交通数据
df_traffic = pd.read_csv('traffic_data.csv')
# 根据具体需求处理数据
# 假设需要将高于平均值的交通量数据筛选出来
df_high_traffic = df_traffic[df_traffic['traffic_volume'] > df_traffic['traffic_volume'].mean()]
# 根据不同需求选择合适的数据格式进行存储
# 如果希望分享数据给其他同事使用Excel打开
df_high_traffic.to_excel('high_traffic_data.xlsx', index=False)
# 如果需要将数据存储为JSON格式进行Web应用展示
df_high_traffic.to_json('high_traffic_data.json', orient='records')
# 如果需要导入到数据库以便进行更多复杂的分析
import sqlite3
conn = sqlite3.connect('traffic_data.db')
df_high_traffic.to_sql('high_traffic_data', conn, if_exists='replace', index=False)
# 如果需要备份数据或者跨平台分享,可以将数据存储为CSV格式
df_high_traffic.to_csv('high_traffic_data.csv', index=False)
# 打印处理后的数据
print("处理后的交通数据(高于平均值的交通量数据):")
print(df_high_traffic.head())
在这个示例中,我们根据具体需求处理交通数据,并将处理结果存储为不同格式的文件,包括Excel、JSON、SQLite数据库和CSV。通过选择合适的数据格式进行存储,可以更好地满足不同用途和平台的需求,实现数据的灵活交互和处理。
当处理交通数据时,除了根据需求选择合适的数据格式进行存储之外,还可以进一步扩展代码,实现数据处理、分析和可视化等功能。以下示例代码展示了如何使用matplotlib库对处理后的高交通量数据进行可视化,并计算交通量的统计信息:
import pandas as pd
import matplotlib.pyplot as plt
# 读取交通数据
df_traffic = pd.read_csv('traffic_data.csv')
# 根据具体需求处理数据
# 假设需要将高于平均值的交通量数据筛选出来
df_high_traffic = df_traffic[df_traffic['traffic_volume'] > df_traffic['traffic_volume'].mean()]
# 可视化交通量数据
plt.figure(figsize=(10, 6))
plt.hist(df_high_traffic['traffic_volume'], bins=20, color='skyblue', edgecolor='black')
plt.xlabel('Traffic Volume')
plt.ylabel('Frequency')
plt.title('Distribution of High Traffic Volume')
plt.grid(axis='y', alpha=0.75)
plt.savefig('high_traffic_volume_distribution.png')
plt.show()
# 计算交通量的统计信息
traffic_stats = df_high_traffic['traffic_volume'].describe()
# 打印交通量统计信息
print("交通量统计信息:")
print(traffic_stats)
通过以上代码,我们对高交通量数据进行了可视化展示,绘制了交通量的直方图,并计算了交通量的统计信息。这样,我们不仅可以对数据进行处理和存储,还可以进行数据分析和可视化,以便更好地理解和利用交通数据。
九、知识点归纳
在交通数据处理领域,Pandas 的应用相当广泛,主要涉及数据的读取、处理、筛选和分析等方面。以下是一些常见的知识点归纳:
-
数据读取和载入:
- 通过
read_csv()方法读取 CSV 文件中的交通数据,并转换为 DataFrame 对象。 - 通过
read_excel()方法读取 Excel 文件中的交通数据。
- 通过
-
数据筛选和选择:
- 使用
loc[]和iloc[]方法根据行索引或列索引选择数据。 - 使用
query()方法根据条件筛选数据。
- 使用
-
数据清洗和预处理:
- 处理缺失值:使用
fillna()方法填充缺失值或dropna()方法删除缺失值。 - 数据去重:使用
drop_duplicates()方法去除重复数据。 - 数据类型转换:使用
astype()方法将数据类型转换为特定类型。
- 处理缺失值:使用
-
数据分组和聚合:
- 使用
groupby()方法对数据进行分组。 - 结合聚合函数如
count()、sum()、mean()、max()、min()等计算各组数据的统计量。
- 使用
-
数据操作和处理:
- 使用
apply()方法对每个元素或行/列进行操作。 - 使用
map()方法对某一列进行映射转换。
- 使用
-
数据合并和拼接:
- 使用
concat()方法按行或列拼接数据。 - 使用
merge()方法根据某一列进行合并。
- 使用
-
时间序列数据处理:
- 使用
pd.to_datetime()方法将字符串转换为日期时间类型。 - 使用
resample()方法对时间序列数据进行重采样。 - 使用
rolling()方法计算滚动统计量。
- 使用
-
数据可视化:
- 结合 Matplotlib 或 Seaborn 库,通过 DataFrame 中的数据绘制图表展示交通数据的趋势和规律。利用 Matplotlib 和 Seaborn 等库绘制交通数据的时间序列图、箱线图、散点图等,便于数据分析和展示。
-
特征工程:
- 创建新特征:通过基本数学运算、特征组合或特征交叉创建新的特征列。
- 类别型特征编码:使用
get_dummies()方法对类别型特征进行独热编码。
-
时间序列数据分析:
- 使用
shift()方法计算时间序列数据的滞后值,用于构建时间序列特征。 - 使用
diff()方法计算时间序列数据的差分,用于处理非平稳时间序列数据。 - 对时间戳数据进行处理,包括日期分割、提取小时、分钟等时间属性,以便更好地分析时间序列数据。
- 使用时序数据的滚动窗口功能,例如计算滚动平均值、滚动标准差等,有助于揭示数据的趋势和周期性。
- 使用
-
异常值处理:
对可能存在的异常数据进行识别和处理,可以基于统计方法、正态分布等进行异常值检测,并根据具体情况进行处理或剔除。
-
数据导出:
- 使用
to_csv()方法将处理后的数据导出为 CSV 文件,方便后续分析或共享。 - 将处理后的数据导出为各种格式,如 CSV、Excel 等,方便后续数据分析、报告撰写或分享给他人。
- 使用
-
数据分析和建模:
- 基于 Pandas 处理后的数据,可以结合 Scikit-learn 或 TensorFlow 等机器学习库进行数据建模和预测,例如建立回归模型或分类模型进行交通流量预测或路况识别等任务。
-
特征工程:
根据实际需求创建新的特征列,可以是基于现有数据进行计算或根据领域知识构建的特征。
对类别型特征进行编码,如使用独热编码、标签编码等方法处理分类数据。

通过以上知识点学习,可以掌握Pandas 在交通数据处理领域常见的应用,可以有效地处理和分析交通数据,洞察数据背后的规律和趋势。可以更全面地利用 Pandas 对交通数据的处理和分析,提取有用的特征、准备数据集、可视化数据以及构建预测模型,进一步推动交通数据的挖掘和应用。
















 4112
4112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











