







审计日志打开后会影响性能,本篇做下根因分析。
1 相关参数
这两个参数打开后会增加大量的日志写入,一般生产环境上纠结的就是这两个参数了,其他日志参数使用的较少。
-
log_statement:有效值是none(off)、ddl、mod和all(所有语句),打开all后会记录大量日志14115 [local] postgres bench 2019-07-16 07:13:41 UTC 00000LOG: execute P0_1: SELECT abalance FROM pgbench_accounts WHERE aid = $1; 14115 [local] postgres bench 2019-07-16 07:13:41 UTC 00000DETAIL: parameters: $1 = '13660205' -
log_duration:记录语句的持续时间14499 [local] postgres bench 2019-07-16 07:25:19 UTC 00000LOG: execute P0_1: SELECT abalance FROM pgbench_accounts WHERE aid = $1; 14499 [local] postgres bench 2019-07-16 07:25:19 UTC 00000DETAIL: parameters: $1 = '17685816' 14499 [local] postgres bench 2019-07-16 07:25:19 UTC 00000LOG: duration: 0.055 ms
2 测试记录
-
环境:64C(小规格上测不出来的,需要大并发引起log大量锁冲突)
-
初始化:
pgbench -i -s 200 bench
结果对比:
| log_statement | log_duration | tps | 下降% |
|---|---|---|---|
| none | 166786.137539 | 0% | |
| all | off | 141541.265184 | 15% |
| all | on | 96551.544436 | 42% |
2.1 关闭审计日志
关闭审计日志,使用prepared协议,只做select尽量增加SQL执行数量,避免IO影响测试(IO一般都会是瓶颈)
alter system set logging_collector=on;
alter system set log_rotation_size='128MB';
alter system set log_statement='none';
select pg_reload_conf();
测试:tps = 166786.137539
pgbench -M prepared -c 64 -j 64 -P 1 -T 120 -r -v -S bench
transaction type: <builtin: select only>
scaling factor: 200
query mode: prepared
number of clients: 64
number of threads: 64
duration: 120 s
number of transactions actually processed: 20016075
latency average = 0.384 ms
latency stddev = 0.097 ms
tps = 166786.137539 (including connections establishing)
tps = 166823.430955 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.002 \set aid random(1, 100000 * :scale)
0.386 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
2.2 打开审计日志&关闭记录时间
alter system set logging_collector=on;
alter system set log_rotation_size='128MB';
alter system set log_statement='all';
alter system set log_duration='off';
select pg_reload_conf();
测试:tps = 141541.265184
pgbench -M prepared -c 64 -j 64 -P 1 -T 120 -r -v -S bench
transaction type: <builtin: select only>
scaling factor: 200
query mode: prepared
number of clients: 64
number of threads: 64
duration: 120 s
number of transactions actually processed: 16989391
latency average = 0.452 ms
latency stddev = 0.300 ms
tps = 141541.265184 (including connections establishing)
tps = 141568.228057 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.002 \set aid random(1, 100000 * :scale)
0.466 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
2.3 打开审计日志&打开记录时间
alter system set logging_collector=on;
alter system set log_rotation_size='128MB';
alter system set log_statement='all';
alter system set log_duration='on';
select pg_reload_conf();
测试:tps = 96551.544436
pgbench -M prepared -c 64 -j 64 -P 1 -T 120 -r -v -S bench
transaction type: <builtin: select only>
scaling factor: 200
query mode: prepared
number of clients: 64
number of threads: 64
duration: 120 s
number of transactions actually processed: 11589065
latency average = 0.662 ms
latency stddev = 3.185 ms
tps = 96551.544436 (including connections establishing)
tps = 96570.262659 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.002 \set aid random(1, 100000 * :scale)
0.708 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
3 PERF分析
3.1 两个日志参数打开
打开参数执行压测的同时开始perf收集5s数据
perf record -agv -- sleep 5
使用perf展示结果
perf report -v -n --showcpuutilization -g --stdio
perf report -n --showcpuutilization -g --no-children --stdio
perf top -n -g --no-children
使用gprof2dot处理数据图形化展示结果
perf script | c++filt | gprof2dot -f perf | dot -Tpng -o output.png
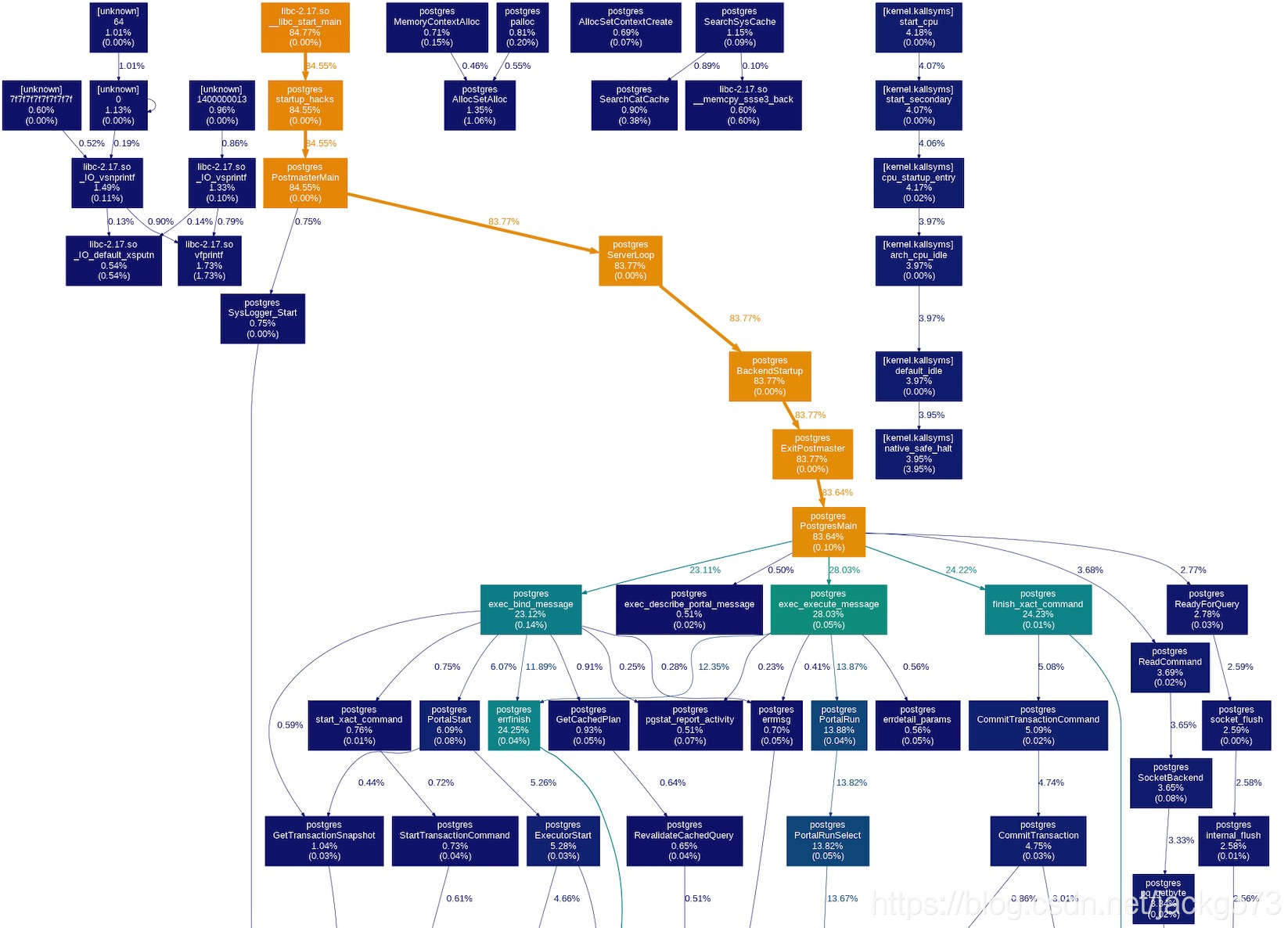
上半部分可以明显看到errfinish的占用率是比较高的,这个函数会刷审计日志,如果参数不打开的话这个函数占用时间非常少。继续看下这个函数为什么占用时间高:
直接看最后的部分
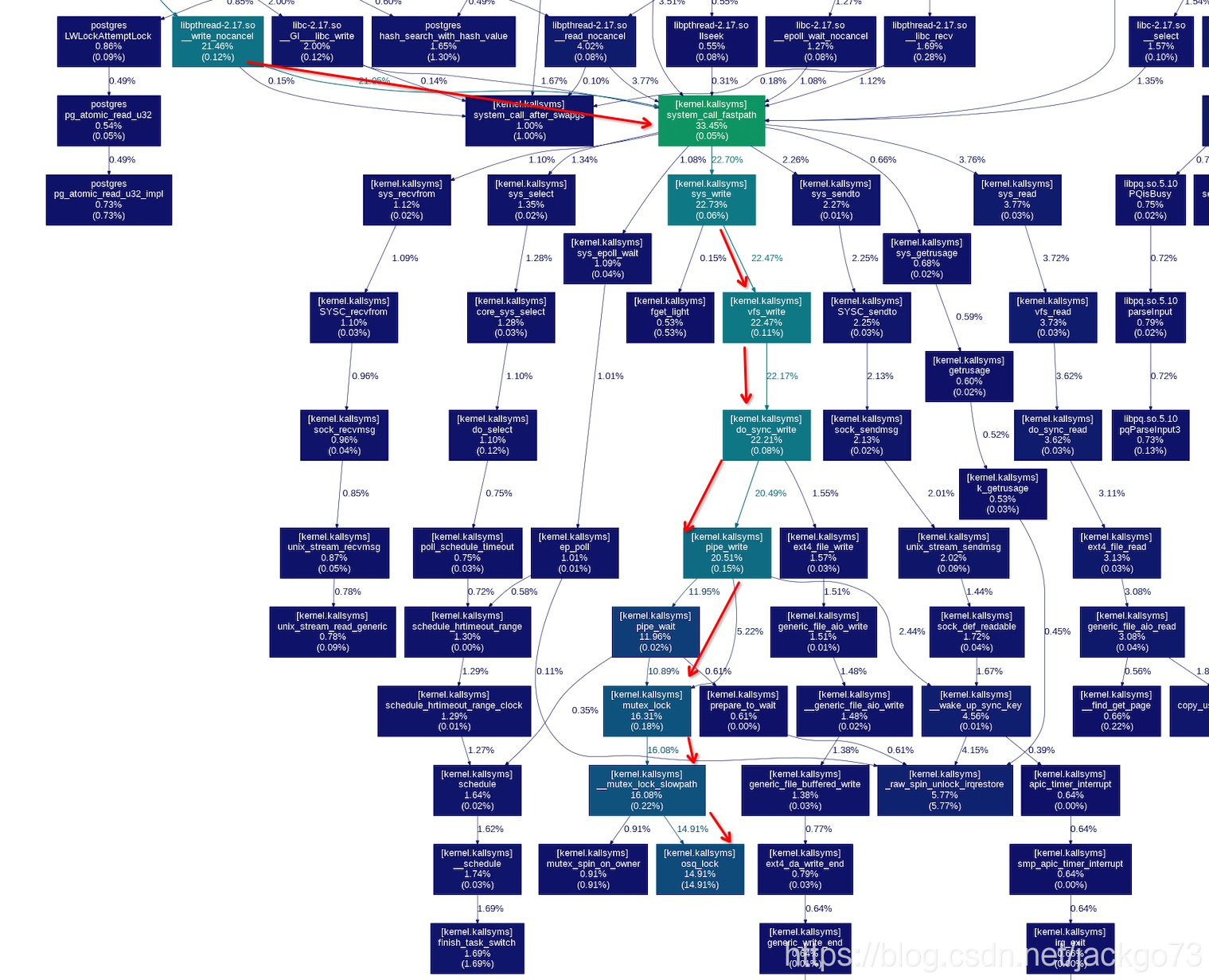
这里可以看到pipe_write函数在等mutex_lock,等锁占用了大量的时间(14%)。
3.2 关闭日志时间参数
只打开log_statement='all'参数,为了是问题更明显,测试使用select 1增加日志的写入量!
pgbench -M prepared -c 64 -j 64 -P 1 -T 1200 -r -f ./s1.sql
对比一下select 1和pgbench -S的效果
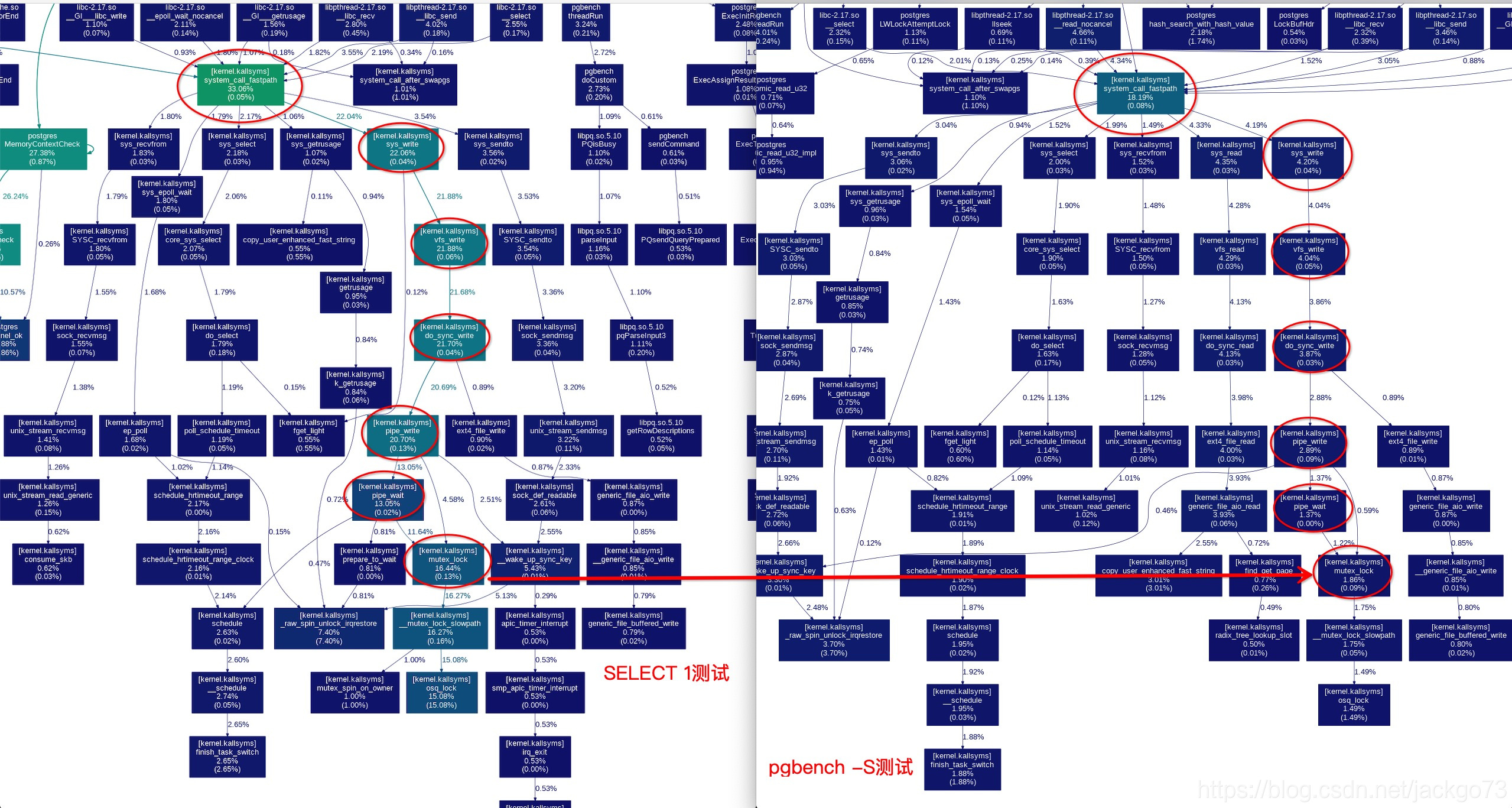
可以看到mutex锁竞争是明显的瓶颈。
那么pipe的mutex锁是哪来的?pipe锁的机制是什么样的?下一篇继续分析。
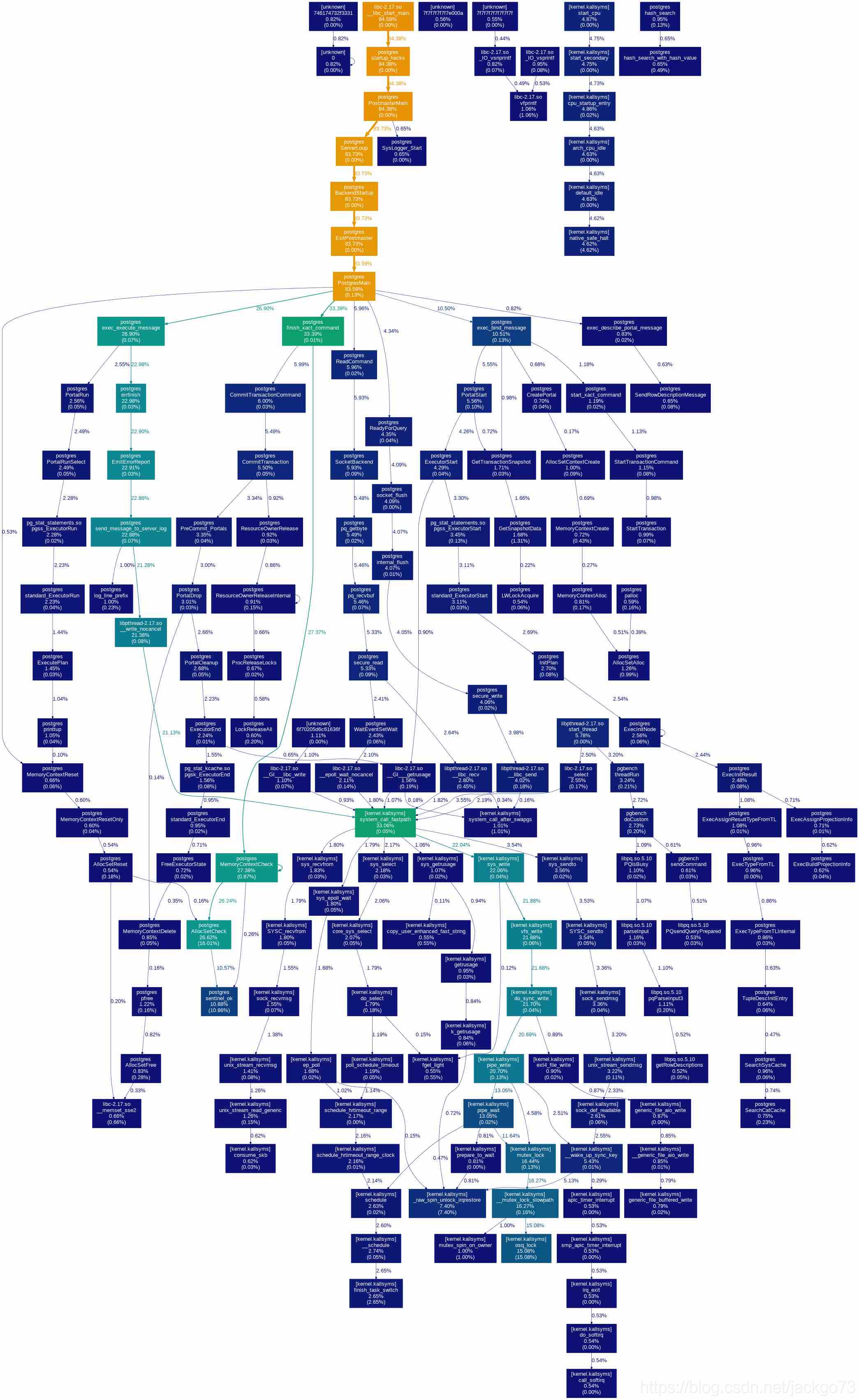
select 1的完整调用栈















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











