







Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
日志收集
Flume最早是Cloudera提供的日志收集系统,是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
数据处理
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 。Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式,exec(命令执行)等数据源上收集数据的能力。
工作方式
Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
优势
1.Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
2.当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据。
3.提供上下文路由特征
4.Flume的管道是基于事务,保证了数据在传送和接收时的一致性。
5.Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
1、下载:Index of /dist/flume

2、安装部署
1)解压 apache flume 1.9.0 bin.tar.gz
chmod 777 apache-flume-1.9.0-bin.tar.gz
tar -zxvf apache-flume-1.9.0-bin.tar.gz

2)重命名目录
mv apache-flume-1.9.0-bin flume

3)将lib目录下的guava 11.0.2.jar删除以兼容Hadoop3.1.3
cd flume/lib/
rm –rf guava-11.0.2.jar
4)检查hadoop是否安装和配置环境变量
hadoop version

5)修改conf目录下的log4j配置文件,配置存储日志文件的路径
cd conf/
vim log4j.properties

按Esc退出,输入:wq保存并退出编辑
3、Flume实现Kafka生产者(Flume发送数据到Kafka主题test)
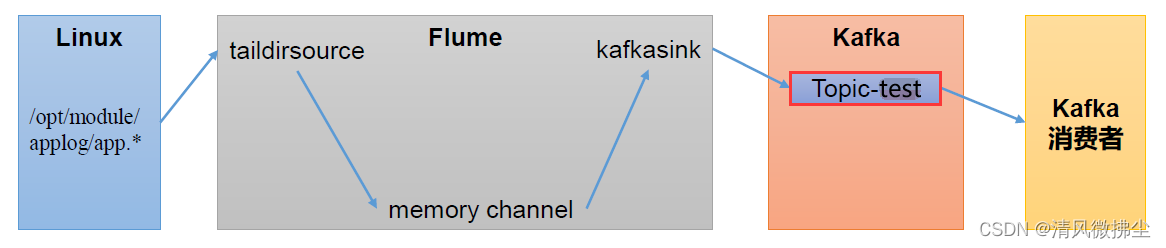
1)创建jobs目录:mkdir jobs
2)创建配置文件:vim jobs/file_to_kafka.conf

# 1、组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2、配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/pengbiao/applog/app.*
a1.sources.r1.positionFile = /home/pengbiao/flume/taildir_position.json
# 3、配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 4、配置 sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop002:9092,hadoop003:9092
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# 5、拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

3)启动Flume
bin/flume-ng agent -c conf/ -n a1 -f jobs/file_to_kafka.conf &
注:上面命令后面加上&表示后台启动


4)创建applog目录和app.log文件来模拟数据
注:创建的目录是对应jobs/file_to_kafka.conf中的a1.sources.r1.filegroups.f1 = /home/pengbiao/applog/app.*
输入命令:
cd /home/pengbiao
mkdir applog

vim app.log

![]()
输入数据并保存,然后观察kafka消费者有没有收到数据
![]()
4、Flume实现Kafka消费者(Flume从Kafka主题test订阅消息)

1)创建jobs目录(如果已创建就无需执行):mkdir jobs
2)创建配置文件:vim kafka_to_file.conf

# 1、组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2、配置source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 50
a1.sources.r1.batchDurationMillis = 200
a1.sources.r1.kafka.bootstrap.servers = hadoop002:9092,hadoop003:9092
a1.sources.r1.kafka.topics = test
a1.sources.r1.kafka.consumer.group.id = test-group-001
# 3、配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 4、配置sink
a1.sinks.k1.type = logger
# 5、拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

3)启动Flume
输入命令:bin/flume-ng agent -c conf/ -n a1 -f jobs/kafka_to_file.conf -Dflume.root.logger=INFO,console


4)kafka生产者发送数据

5)查看flume启动窗口的控制台输出















 2405
2405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









