







一、Kafka和Flume的整合
1.1 部署实施
Flume主要是做日志数据(离线或实时)的采集。
下图显示的是flume采集完毕数据之后,进行的离线处理和实时处理两条业务线,本文将介绍flume和kafka的整合处理。

- 创建整合的topic
# kafka-topics.sh --create \
--topic flume-kafka \
--zookeeper bigdata01:2181/kafka \
--partitions 3 \
--replication-factor 3
Created topic "flume-kafka".- 调整Flume-agent配置文件
flume-kafka-sink.conf
##a1就是flume agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = bigdata01
a1.sources.r1.port = 44444
# 修改sink为kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = bigdata01:9092,bigdata02:9092,bigdata03:9092
a1.sinks.k1.kafka.topic = flume-kafka
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 启动Flume和kafka的整合测试
- 消费者监听读取的数据
# kafka-console-consumer.sh --topic flume-kafka \ --bootstrap-server bigdata01:9092 \ --from-beginning - 启动flume-agent
# nohup bin/flume-ng agent -n a1 -c conf -f conf/flume-kafka-sink.conf >/dev/null 2>&1 & - 发送数据
# telnet bigdata01 44444 Trying 192.168.10.101... Connected to bigdata01. Escape character is '^]'. Hello Oak OK Good Good Study Day Day Up! OK - 接收数据
# kafka-console-consumer.sh --topic flume-kafka --bootstrap-server bigdata01:9092 --from-beginning Hello Oak Good Good Study Day Day Up!
二、Kafka架构之道
2.1 Kafka相关术语介绍

replica:
每⼀个分区,根据副本因子N,会有N个副本。比如在broker1上有一个topic,分区为topic-1, 副本因子为2,那么在两个broker的数据目录里,都会有⼀个topic-1,其中⼀个是leader,⼀个follower。
Segment:
partition 物理上由多个 segment 组成,每个 Segment 存着 message 信息。
Leader:
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower:
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出⼀个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
Offset
kafka的存储文件都是按照offset.log来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置, 只要找到2048.log的文件即可。当然the first offset就是00000000000.log
2.2 Kafka的架构
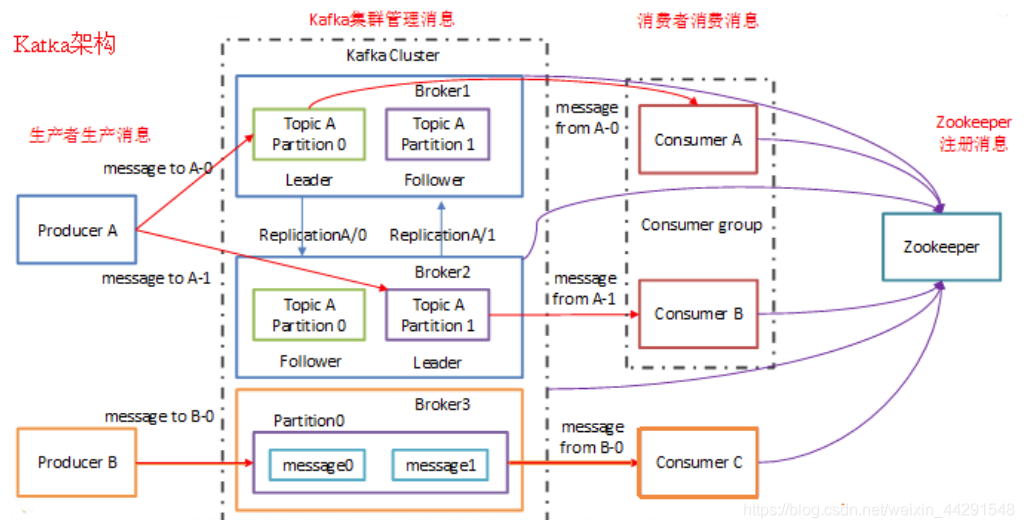
通常,一个典型的Kafka集群中包含若干Producer(可以是web前端产⽣的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干 Consumer Group,以及⼀个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在 Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull 模式从broker订阅并消费消息。
2.3 Kafka的分布式模型
Kafka分布式主要是指分区被分布在多台server(broker)上,同时每个分区都有leader和follower(不是必须),即老大和小弟的角色,老大负责处理,小弟负责同步,小弟也可以变成老大,形成分布式模型。
kafka的分区日志(message)被分布在kafka集群的服务器上,每⼀个服务器处理数据和共享分区请求。每⼀个分区是被复制到⼀系列配置好的服务器上来进行容错。
每个分区有⼀个server节点来作为分区leader和零个或者多个server节点来作为分区followers。分区leader处理指定分区的所有读写请求,同时分区follower被动复制分区leader。如果leader失败,follwers中的⼀个将会自动地变成⼀个新的leader。每⼀个服务器都能作为分区的⼀个leader和作为其它分区的follower,因此kafka集群能被很好地平衡。kafka集群是一个去中心化的集群。
以上信息参考官网:http://kafka.apache.org/intro.html#intro_distribution

kafka消费的并行度就是kafka topic分区的个数,或者说分区的个数决定了同一时间同一消费者组内最多可以有多少个消费者消费数据。
2.4 kafka的文件存储

- 在kafka集群中,分为单个broker和多个broker。每个broker中有多个topic,topic数量可以自己设定。在每个topic中又有0到多个partition,每个partition为一个分区。kafka分区命名规则为topic的名称+有序序号,这个序号从0开始依次增加。
- 每个partition中有多个segment file。创建分区时,默认会生成一个segment file,kafka默认每个segmentfile的大小是1G。当生产者向partition中存储数据时,内存中存不下了,就会往segment file里面刷新。在存储数据时,会先生成⼀个segment file,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











