







逻辑回归模型属于广义线性回归模型,也是一种常用的二分类模型,模型假设输入向量 x 与分类概率 P(y | x; θ) 符合逻辑线性关系,并可用极大似然或极小化损失函数来估计模型的参数θ。
[欢迎访问我的博客:http://blog.csdn.net/jacobzende ]
分类公式:
1. 给定线性函数:
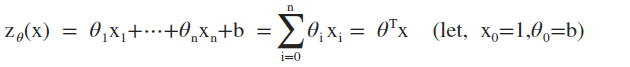
2. 给定逻辑函数:
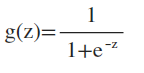
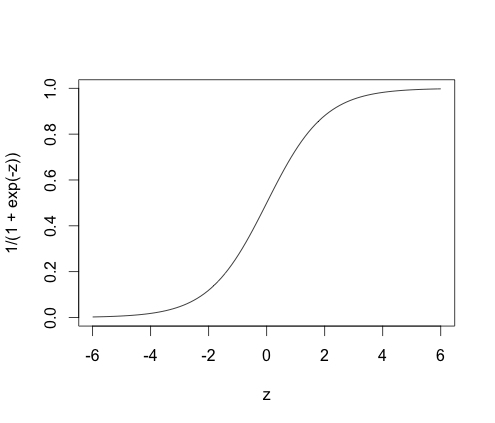
将 z∈(-∞, +∞)值映射到[0,1]
3. 定义复合函数:
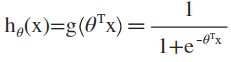
4. 定义分类公式:
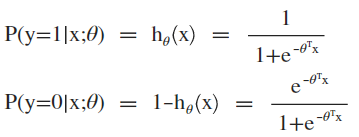
合并写为:
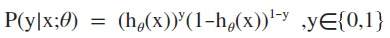
5. 概率分割点为0.5=h(x)=g(z),对应z=0的线性超平面即为模型的分割面。分类公式可以很好的将点到分割面的距离转换为概率,距离越远属于相应类别的概率越大,按指数衰减。
参数估计:
1、参数估计方法
介绍逻辑回归模型参数估计的两种方法:极大似然估计、极小损失函数估计。
(1)极大似然估计:
给定m个训练样本,θ的似然函数等于各个样本于标注类别的概率的积:
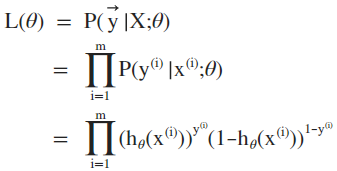
极大似然估计即为求解逻辑似然函数的最优化问题:
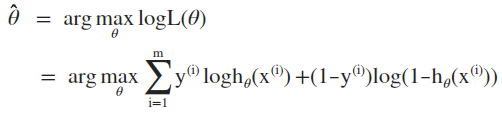
(2)极小损失函数估计
逻辑回归采用log损失函数:
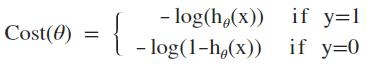
函数图如下,显然,预测与实际结果越不一致,损失函数的值越大:
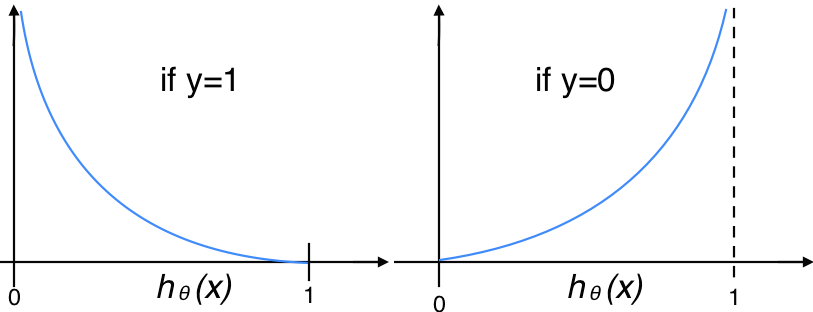
线性回归模型采用的差方损失函数(OLS/最小二乘法)对逻辑回归模型不适用,由于逻辑回归公式是非线性的,故差方损失函数为非凸函数(非线性的二次型),最优化求解较为困难。log损失函数常用于概率输出类模型,并可以证明上述逻辑回归模型的log损失函数一定是凸函数。
由于 y 取值{0,1},可将上述函数合并写为:
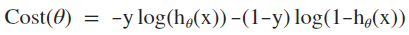
扩展到m个训练样本,该损失函数正好是逻辑似然函数负数的平均值,也为log损失函数提供了概率一致性的解释:
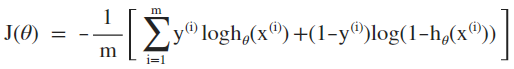
极小损失函数最优化问题即为求解:
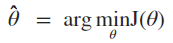
如果定义 y 取值{-1,+1},可以得到更为紧凑的损失函数形式:
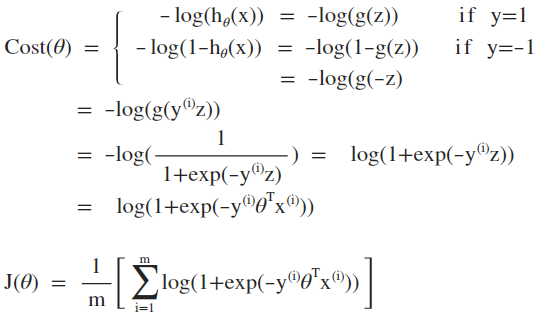
上述推导用到 g(z) = 1 - g(-z),这个很容易证明,可以自己推导一下。
2、正则化(regularization)
为损失函数增加参数的L1或L2范数惩罚项来消去不明显的或冗余的特征以避免过拟合,L1及L2正则化惩罚项分别定义为:
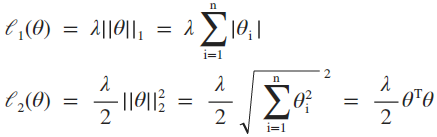
L1正则化用参数的1-范数乘以系数 λ 作为惩罚项,L2正则化用参数的2-范数的平方乘以系数 λ / 2 作为惩罚项(此处除于2只有数学公式上的意义)。
另外由于截距项 theta0 没有对应的特征项(x0=1),其目的是为了适配数据的整体偏移,因做为保留项特殊处理,不需要参与正则化。
对于 y 取值 {-1, +1}的形式,L1及L2正则化的损失函数分别为:
对上述损失函数求极小化:
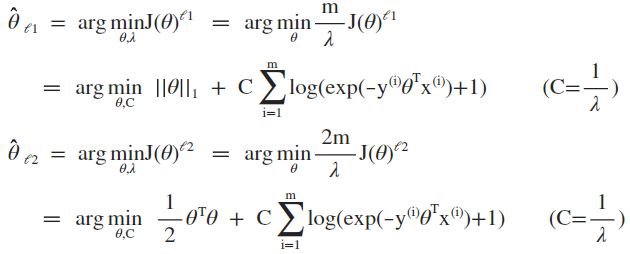
第二步等式中乘以一个标量常数因子不改变最优化问题的解,最终将优化公式转化为常见的形式。
截距项不参与正则化,截距项不同于普通的特征项(可以理解为截距项的特征值=1),截距项的作用是拟合训练样本的整体偏差(有利于其他特征项参数的正则化),而正则化主要是解决过拟合问题,因此对截距项惩罚有害无益。
算法:随机梯度下降
相比拟牛顿算法,随机梯度下降(SGD)算法是一种简单有效的凸函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









