







目录
1.原理
1.1输入

1.2激活函数(sigmoid函数 )
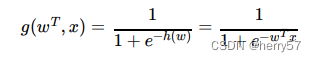
判断标准
回归的结果输⼊到sigmoid函数当中
输出结果:[0, 1]区间中的⼀个概率值,默认为0.5为阈值,其图像如下
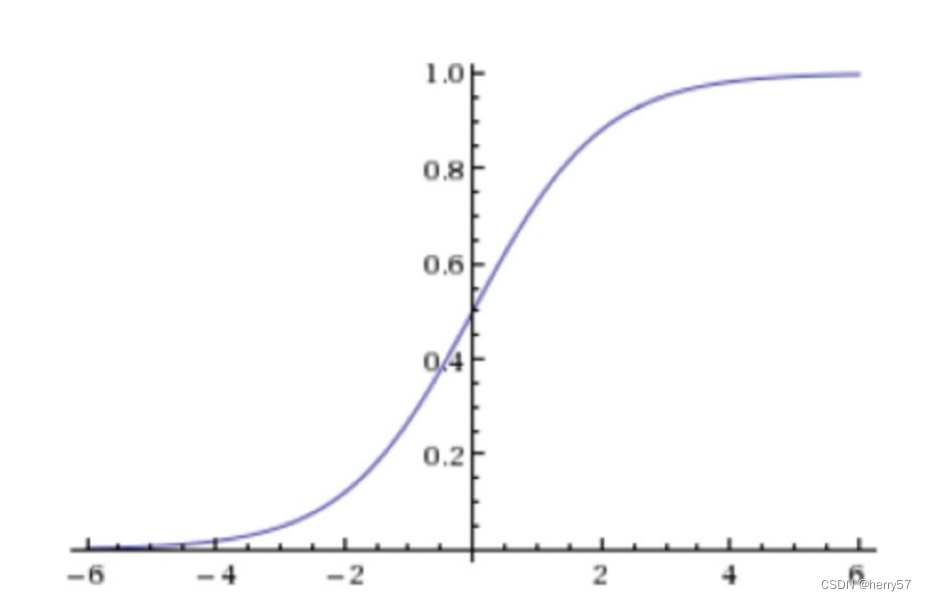
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例), 另外的⼀个类别会标记为0(反例)
2.损失
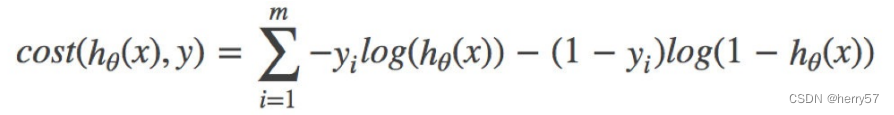
当y=1时,我们希望h (x)值越⼤越好
当y=0时,我们希望h (x)值越⼩越好

-log(P), P值越⼤,结果越⼩
优化:提升原本属于1类别的概率,降低原本是0类别的概率。
对于⼩数据集来说,“liblinear”是个不错的选择,⽽“sag”和'saga'对于⼤型数据集会更快。
3.案例
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report,roc_auc_score
# 1.获取数据
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data=pd.read_csv("D:/迅雷下载/demo/machineLearnCode/LogisticRegressionTest//breast-cancer-wisconsin.data",names=names)
# 2.基本数据处理
# 2.1 缺失值处理
data=data.replace(to_replace="?",value=np.nan) #把问号替换为nan
data=data.dropna()
# 2.2 确定特征值,⽬标值
x=data.iloc[:,1:-1]
y=data["Class"]
# 2.3 分割数据
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=22,test_size=0.2)
# 3.特征⼯程(标准化)
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
# 4.机器学习(逻辑回归)
estimator=LogisticRegression()
estimator.fit(x_train,y_train)
# 5.模型评估
y_predict=estimator.predict(x_test) #准确率
print(y_predict)
print(estimator.score(x_test,y_test))
# 5.1精确率和召回率
ret=classification_report(y_test,y_predict,labels=(2,4),target_names=("良性","恶性"))
print(ret)
# 5.2auc指标计算
y_test=np.where(y_test>3,1,0)
print(roc_auc_score(y_test,y_predict))















 5113
5113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









