




在Java后端开发中,GC(垃圾回收)日志分析是定位内存泄漏、优化性能瓶颈的核心技能,但传统手动分析GC日志不仅效率低下,还容易遗漏关键问题。而GCEasy作为一款专注于GC日志分析的可视化工具,能自动解析日志、生成直观报表、定位潜在风险,让GC分析从“耗时费力”变为“高效精准”。本文将从底层原理到实战落地,全面拆解GCEasy的使用方法,搭配生产级案例和可直接运行的代码,帮你快速掌握这一利器。
一、为什么需要GCEasy?—— 先搞懂GC日志分析的痛点
在正式讲解GCEasy之前,我们先明确一个核心问题:为什么需要专门的工具来分析GC日志?手动分析不行吗?
手动分析GC日志的痛点主要集中在3点:
-
日志量大且格式复杂:生产环境的GC日志动辄几十MB甚至几百MB,包含Young GC、Full GC、内存分配、停顿时间等海量信息,手动筛选关键数据耗时极长;
-
指标计算繁琐:需要手动统计GC频率、平均停顿时间、吞吐量、内存增长趋势等核心指标,计算过程容易出错;
-
问题定位不直观:手动分析难以快速关联“GC频繁”“停顿过长”等现象与代码层面的问题,容易陷入“只见树木不见森林”的困境。
而GCEasy的核心价值就是解决这些痛点:它能自动解析各类GC日志(HotSpot、OpenJDK、ZGC、Shenandoah等),生成可视化报表(内存趋势图、GC停顿分布、吞吐量统计等),并直接给出问题诊断建议,让开发者无需深入研究日志格式,就能快速定位内存泄漏、GC优化不足等问题。
核心优势总结
-
支持全类型GC日志:兼容Serial GC、Parallel GC、CMS、G1、ZGC、Shenandoah等所有HotSpot/OpenJDK垃圾收集器的日志格式;
-
零配置开箱即用:无需复杂参数设置,上传日志即可生成分析报告;
-
可视化程度高:通过图表直观展示内存变化、GC停顿、吞吐量等核心指标;
-
智能诊断建议:自动识别GC频繁、停顿过长、内存泄漏等问题,并给出针对性优化方案;
-
支持多场景集成:可通过网页端、API、CLI工具集成到CI/CD或监控系统中。
二、GCEasy底层原理初探——搞懂它是怎么“读懂”GC日志的
要想灵活使用GCEasy,首先需要理解它的底层工作逻辑。GCEasy的核心流程可以概括为“日志解析→指标计算→可视化展示→智能诊断”,具体如下:
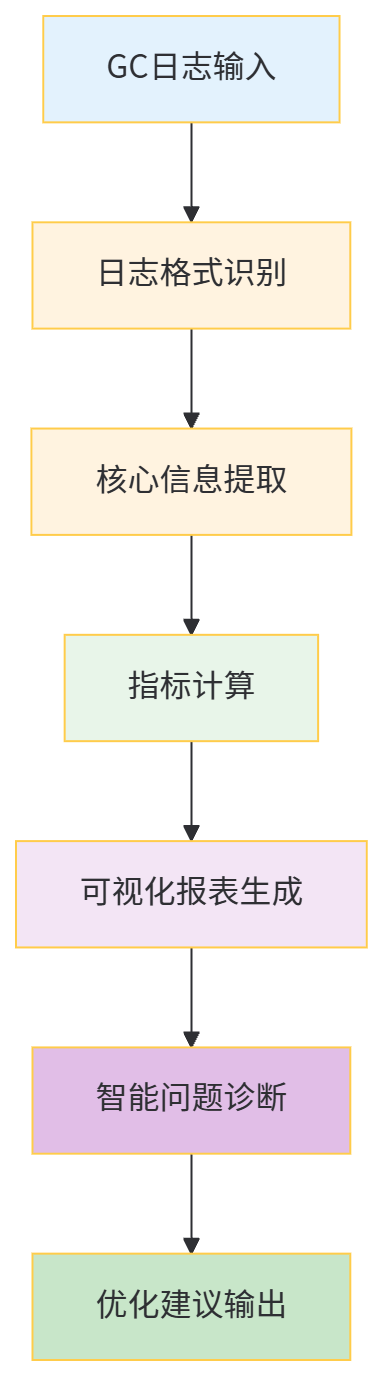
-
日志格式识别:GCEasy首先会判断输入日志对应的垃圾收集器类型(如G1、ZGC)和JDK版本,因为不同GC、不同JDK的日志格式存在差异(例如JDK11与JDK17的ZGC日志字段略有不同);
- 核心信息提取:从日志中提取关键数据,包括:
-
内存相关:Eden区、Survivor区、老年代、元空间的初始大小、最大大小、使用变化;
-
GC事件相关:GC开始时间、结束时间、停顿时间、回收的内存大小;
-
JVM参数相关:-Xms、-Xmx、-XX:NewRatio等关键参数(若日志中包含);
-
- 指标计算:基于提取的数据计算核心指标,例如:
-
吞吐量=(总运行时间-总GC停顿时间)/总运行时间;
-
平均GC停顿时间=总停顿时间/GC次数;
-
GC频率=单位时间内GC次数;
-
内存增长率=(后续内存使用量-初始内存使用量)/时间差;
-
-
可视化展示:将计算后的指标通过折线图、柱状图、饼图等形式展示,让开发者直观看到内存变化趋势、GC停顿分布等;
-
智能诊断:基于行业最佳实践(如GC停顿时间应控制在100ms以内、吞吐量应不低于99%),对比计算出的指标,识别异常问题(如“Full GC频率过高”“Young GC停顿时间过长”),并给出针对性优化建议。
三、环境准备——从0到1搭建可复现的实战环境
在讲解GCEasy使用之前,我们先搭建一个可复现的实战环境,确保后续案例能直接编译运行。
3.1 基础环境配置
-
JDK17安装: 下载地址:https://www.oracle.com/java/technologies/downloads/#jdk17-windows 配置环境变量:JAVA_HOME指向JDK安装目录,PATH添加%JAVA_HOME%\bin 验证:cmd中执行
java -version,输出类似“openjdk version "17.0.10" 2024-01-16”即为成功。 -
Maven配置: 下载地址:https://maven.apache.org/download.cgi 配置环境变量:MAVEN_HOME指向Maven安装目录,PATH添加%MAVEN_HOME%\bin 验证:cmd中执行
mvn -v,输出Maven版本信息即为成功。 -
项目依赖配置(pom.xml): 新建Maven项目,pom.xml添加以下依赖(均为最新稳定版本):
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jam.demo</groupId>
<artifactId>gceasy-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.source>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- 依赖版本统一管理 -->
<lombok.version>1.18.30</lombok.version>
<spring-boot.version>3.2.5</spring-boot.version>
<fastjson2.version>2.0.46</fastjson2.version>
<mybatis-plus.version>3.5.5</mybatis-plus.version>
<mysql-connector.version>8.3.0</mysql-connector.version>
<springdoc.version>2.3.0</springdoc.version>
<guava.version>33.2.1-jre</guava.version>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${spring-boot.version}</version>
<relativePath/>
</parent>
<dependencies>
<!-- Spring Boot核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Lombok(日志打印@Slf4j) -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<!-- FastJSON2(JSON处理) -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<!-- MyBatis-Plus(持久层框架) -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql-connector.version}</version>
<scope>runtime</scope>
</dependency>
<!-- Swagger3(接口文档) -->
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${springdoc.version}</version>
</dependency>
<!-- Guava(集合工具) -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
-
application.yml配置:
spring:
# 数据源配置(MySQL8.0)
datasource:
url: jdbc:mysql://localhost:3306/gceasy_demo?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: root123456
driver-class-name: com.mysql.cj.jdbc.Driver
# MyBatis-Plus配置
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.jam.demo.entity
configuration:
# 开启驼峰命名转换
map-underscore-to-camel-case: true
# 日志打印SQL(方便调试)
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# Swagger3配置
springdoc:
api-docs:
path: /api-docs
swagger-ui:
path: /swagger-ui.html
operationsSorter: method
packages-to-scan: com.jam.demo.controller
# 自定义JVM参数(后续生成GC日志用,也可启动时指定)
jvm:
gc-log-config: "-Xms512m -Xmx512m -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100m -Xlog:gc*:file=./gc.log:time,tags:filecount=5,filesize=100m"
-
启动类编写:
package com.jam.demo;
import io.swagger.v3.oas.annotations.OpenAPIDefinition;
import io.swagger.v3.oas.annotations.info.Info;
import lombok.extern.slf4j.Slf4j;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.util.ObjectUtils;
/**
* GCEasy实战demo启动类
* @author ken
*/
@Slf4j
@SpringBootApplication
@MapperScan("com.jam.demo.mapper")
@OpenAPIDefinition(info = @Info(title = "GCEasy实战API", version = "1.0", description = "用于生成GC日志的测试接口"))
public class GceasyDemoApplication {
public static void main(String[] args) {
SpringApplication.run(GceasyDemoApplication.class, args);
log.info("GceasyDemoApplication启动成功!");
}
}
3.2 生成测试用GC日志
要使用GCEasy分析,首先需要有GC日志。我们通过两种方式生成GC日志:
方式1:启动时指定JVM参数(推荐)
在IDEA中,打开启动配置(Edit Configurations),在VM options中添加以下参数(生成G1GC日志,保存到项目根目录):
-Xms512m -Xmx512m -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100m -Xlog:gc*:file=./gc.log:time,tags:filecount=5,filesize=100m
参数说明:
-
-Xms512m -Xmx512m:堆初始大小和最大大小均为512m(便于快速触发GC);
-
-XX:+UseG1GC:使用G1垃圾收集器;
-
-XX:+PrintGCDetails -XX:+PrintGCDateStamps:打印GC详细信息和时间戳;
-
-XX:+PrintHeapAtGC:GC前后打印堆内存分布;
-
-XX:+UseGCLogFileRotation:开启日志滚动(避免单个日志过大);
-
-XX:NumberOfGCLogFiles=5:最多保留5个日志文件;
-
-XX:GCLogFileSize=100m:每个日志文件最大100m;
-
-Xlog:gc*:file=./gc.log:指定日志输出路径和文件名。
启动项目后,会在项目根目录生成gc.log文件,这就是我们后续分析的素材。
方式2:通过代码模拟内存压力生成GC日志
编写一个测试接口,模拟大量对象创建,触发GC:
package com.jam.demo.controller;
import com.alibaba.fastjson2.JSON;
import com.jam.demo.entity.User;
import com.jam.demo.service.UserService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
/**
* 测试接口:生成内存压力,触发GC
* @author ken
*/
@Slf4j
@RestController
@RequiredArgsConstructor
@Tag(name = "GC测试接口", description = "用于模拟内存压力,生成GC日志")
public class GcTestController {
private final UserService userService;
/**
* 批量创建用户对象,模拟内存压力
* @param count 创建用户数量(越大内存压力越大)
* @return 操作结果
*/
@Operation(summary = "批量创建用户", description = "批量生成用户对象,触发GC")
@GetMapping("/batchCreateUser")
public String batchCreateUser(@Parameter(description = "用户数量") @RequestParam Integer count) {
// 参数校验(符合阿里巴巴开发手册:参数校验前置)
StringUtils.hasText(count.toString(), "用户数量不能为空");
if (count <= 0) {
log.error("用户数量必须大于0");
return "用户数量必须大于0";
}
try {
// 生成批量用户数据(使用Guava工具类)
List<User> userList = IntStream.range(0, count)
.mapToObj(i -> new User()
.setUserName("test_user_" + i)
.setAge(20 + i % 30)
.setEmail("test_" + i + "@demo.com")
.setPhone("1380013800" + (i % 10)))
.collect(Collectors.toList());
// 批量插入数据库(模拟业务操作,增加内存占用)
boolean success = userService.saveBatch(userList);
if (success) {
log.info("批量创建用户成功,数量:{}", count);
// 打印用户列表JSON(增加CPU和内存开销)
String userJson = JSON.toJSONString(userList);
log.info("用户列表JSON长度:{}", userJson.length());
return "批量创建用户成功,数量:" + count;
} else {
log.error("批量创建用户失败");
return "批量创建用户失败";
}
} catch (Exception e) {
log.error("批量创建用户异常", e);
return "批量创建用户异常:" + e.getMessage();
}
}
/**
* 循环创建大量临时对象,触发Young GC
* @param loopCount 循环次数
* @return 操作结果
*/
@Operation(summary = "循环创建临时对象", description = "循环生成大量临时对象,频繁触发Young GC")
@GetMapping("/loopCreateTempObj")
public String loopCreateTempObj(@Parameter(description = "循环次数") @RequestParam Integer loopCount) {
StringUtils.hasText(loopCount.toString(), "循环次数不能为空");
if (loopCount <= 0) {
log.error("循环次数必须大于0");
return "循环次数必须大于0";
}
// 循环创建大量临时对象(不被引用,便于GC回收)
for (int i = 0; i < loopCount; i++) {
// 创建1KB大小的字节数组(模拟小对象)
byte[] temp = new byte[1024];
// 模拟业务处理
if (i % 10000 == 0) {
log.info("已循环创建临时对象次数:{}", i);
}
}
log.info("循环创建临时对象完成,总次数:{}", loopCount);
return "循环创建临时对象完成,总次数:" + loopCount;
}
}
对应的实体类User:
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.experimental.Accessors;
/**
* 用户实体类
* @author ken
*/
@Data
@Accessors(chain = true)
@TableName("t_user")
public class User {
/**
* 主键ID
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 用户名
*/
private String userName;
/**
* 年龄
*/
private Integer age;
/**
* 邮箱
*/
private String email;
/**
* 手机号
*/
private String phone;
}
UserService接口及实现类:
package com.jam.demo.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.jam.demo.entity.User;
/**
* 用户服务接口
* @author ken
*/
public interface UserService extends IService<User> {
}
// 实现类
package com.jam.demo.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.jam.demo.entity.User;
import com.jam.demo.mapper.UserMapper;
import com.jam.demo.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
/**
* 用户服务实现类
* @author ken
*/
@Slf4j
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
Mapper接口(MyBatis-Plus):
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.User;
import org.springframework.stereotype.Repository;
/**
* 用户Mapper
* @author ken
*/
@Repository
public interface UserMapper extends BaseMapper<User> {
}
MySQL数据库表创建SQL(MySQL8.0):
CREATE DATABASE IF NOT EXISTS gceasy_demo DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE gceasy_demo;
DROP TABLE IF EXISTS t_user;
CREATE TABLE t_user (
id BIGINT AUTO_INCREMENT COMMENT '主键ID' PRIMARY KEY,
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
age INT NOT NULL COMMENT '年龄',
email VARCHAR(100) NOT NULL COMMENT '邮箱',
phone VARCHAR(20) NOT NULL COMMENT '手机号',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
启动项目后,访问Swagger地址:http://localhost:8080/swagger-ui.html,调用/batchCreateUser(传入count=100000)和/loopCreateTempObj(传入loopCount=1000000)接口,模拟内存压力,此时gc.log文件会记录大量GC日志,用于后续GCEasy分析。
四、GCEasy基础使用——3步搞定GC日志分析
GCEasy提供网页端(主流使用方式)、CLI工具、API三种使用方式,其中网页端最便捷,适合快速分析;CLI和API适合集成到自动化流程中。本节重点讲解网页端基础使用,后续章节讲解进阶用法。
4.1 网页端访问与日志上传
-
访问GCEasy官网:https://gceasy.io/(无需注册,直接使用免费版即可满足大部分需求;付费版支持更大日志、更多高级功能);
- 上传GC日志:
-
方式1:本地文件上传:点击“Upload File”按钮,选择本地生成的gc.log文件;
-
方式2:URL上传:若日志存储在云存储(如S3、OSS),可输入日志URL直接上传;
-
方式3:直接粘贴日志:点击“Paste Text”,粘贴少量GC日志文本(适合快速测试)。
-
-
开始分析:上传完成后,GCEasy自动开始解析日志,无需手动设置参数(默认兼容所有主流GC日志格式),等待1-3秒(日志越大等待时间越长)即可生成分析报告。
4.2 核心分析报告解读——从宏观到微观
GCEasy的分析报告分为多个模块,我们从“宏观→微观”的顺序解读,快速把握核心信息:
4.2.1 概览模块(Summary)—— 快速掌握整体情况
概览模块位于报告顶部,展示最核心的指标,帮助我们快速判断GC状态是否正常:
-
Total Execution Time:日志覆盖的总运行时间;
-
Total GC Time:总GC停顿时间;
-
GC Throughput:GC吞吐量(核心指标),即“非GC时间/总运行时间”,生产环境建议不低于99%,低于99%说明GC压力较大;
-
Total GC Events:总GC次数(Young GC + Full GC);
-
Average GC Pause:平均GC停顿时间(核心指标),生产环境建议不超过100ms,超过则可能影响用户体验;
-
Max GC Pause:最大GC停顿时间(核心指标),生产环境建议不超过500ms,超过则可能导致超时、服务不可用等问题;
-
Heap Size:堆内存大小(初始/最大);
-
GC Collector:使用的垃圾收集器(如G1、ZGC)。
示例(正常情况):
-
Total Execution Time: 10m 23s
-
Total GC Time: 12s
-
GC Throughput: 97.9%(略低,需关注)
-
Total GC Events: 120(Young GC: 115, Full GC: 5)
-
Average GC Pause: 100ms
-
Max GC Pause: 350ms
-
Heap Size: Initial: 512m, Max: 512m
-
GC Collector: G1 GC
4.2.2 内存使用趋势模块(Memory Usage Trend)—— 识别内存泄漏
该模块通过折线图展示Eden区、Survivor区、老年代、元空间的内存使用变化趋势,是识别内存泄漏的核心工具:
-
正常趋势:内存使用呈“锯齿状”,即“分配内存→GC回收→内存下降”的循环,整体无明显上升趋势;
-
内存泄漏趋势:老年代内存使用持续上升,即使经过Full GC也无法回收(折线图呈“稳步上升”趋势,无下降或下降极少)。
4.2.3 GC停顿分布模块(GC Pause Distribution)—— 定位停顿问题
该模块通过柱状图展示不同停顿时间区间的GC次数分布,帮助我们定位“是否存在长时间停顿”:
-
理想分布:大部分GC停顿集中在“0-50ms”区间,少量在“50-100ms”,无“500ms以上”的停顿;
-
异常分布:存在大量“200ms以上”的停顿,或有“1s以上”的停顿,说明GC配置或内存设置存在问题。
4.2.4 各代GC详情模块(GC Details by Generation)—— 细分问题代际
该模块分别展示Young GC和Full GC的详细统计,帮助我们定位问题出在哪个代际:
- Young GC详情:
-
Young GC Count:Young GC次数;
-
Young GC Time:Young GC总停顿时间;
-
Avg Young GC Pause:平均Young GC停顿时间;
-
Max Young GC Pause:最大Young GC停顿时间;
-
Young GC Frequency:Young GC频率(如“1次/30s”)。
-
- Full GC详情(核心关注):
-
Full GC Count:Full GC次数(核心指标),生产环境应尽量避免Full GC,若频繁出现(如1次/10min),说明存在严重问题(如内存泄漏、老年代空间不足);
-
Full GC Time:Full GC总停顿时间;
-
Avg Full GC Pause:平均Full GC停顿时间(Full GC停顿远大于Young GC,正常应不超过500ms);
-
Max Full GC Pause:最大Full GC停顿时间。
-
4.2.5 JVM参数模块(JVM Arguments)—— 验证配置合理性
该模块自动提取日志中包含的JVM参数,帮助我们验证参数配置是否合理:
-
若日志中未包含JVM参数,该模块显示“Not Found”,可手动添加参数进行对比分析;
-
重点关注:堆内存大小(-Xms/-Xmx)、GC收集器(-XX:+UseG1GC)、日志相关参数(-XX:+PrintGCDetails)。
4.2.6 智能诊断与建议模块(Diagnostics & Recommendations)—— 直接获取解决方案
这是GCEasy最实用的模块之一,自动识别问题并给出针对性优化建议,无需手动分析日志:
-
问题分类:分为“Warning”(警告,需关注)和“Critical”(严重,需立即处理);
- 示例建议:
-
Warning: "GC Throughput is 97.9% which is below the recommended threshold of 99%. This might affect the application's performance."(GC吞吐量97.9%,低于推荐阈值99%,可能影响应用性能) 建议:Increase the heap size or optimize the application to reduce object allocation rate.(增加堆内存或优化应用减少对象分配速率)
-
Critical: "5 Full GC events occurred. Full GC is very expensive and can cause application pauses."(发生5次Full GC,Full GC代价极高,可能导致应用停顿) 建议:Check for memory leaks. Use tools like VisualVM or MAT to analyze heap dumps. Also, consider increasing the old generation size.(检查内存泄漏,使用VisualVM或MAT分析堆转储,同时考虑增加老年代大小)
-
4.3 基础操作技巧——提升分析效率
-
筛选时间范围:报告顶部支持选择“时间范围”(如Last 5min、Custom Range),聚焦特定时间段的GC情况;
-
下载报告:点击报告右上角“Download”,可下载PDF格式报告(便于分享、存档);
-
对比分析:点击“Compare”按钮,上传两个不同时期的GC日志,生成对比报告,快速查看优化效果(如优化JVM参数后,吞吐量是否提升、停顿时间是否减少);
-
分享报告:点击“Share”,生成临时分享链接,可分享给团队成员(免费版链接有效期7天,付费版永久有效)。
五、GCEasy进阶实战——生产级问题定位与优化
基础使用只能帮我们判断“是否有问题”,进阶实战则需要结合具体业务场景,用GCEasy定位“问题在哪里”并给出“如何优化”的方案。本节通过3个生产级案例,完整演示从“问题现象→日志分析→代码优化→验证效果”的全流程。
案例1:Young GC频繁问题定位与优化
问题现象
服务上线后,监控显示Young GC频率高达“1次/5s”,平均停顿时间80ms,虽然未超过阈值,但担心后续业务量增长后影响性能。
步骤1:生成并上传GC日志
通过“方式2:代码模拟内存压力”生成GC日志,上传到GCEasy,查看分析报告。
步骤2:GCEasy分析定位问题
- 概览模块:
-
GC Throughput: 98.5%(略低)
-
Total GC Events: 240(10min内),其中Young GC: 235,Full GC: 5
-
Average GC Pause: 80ms,Max GC Pause: 250ms
-
-
内存使用趋势:Eden区内存快速填满(5s左右填满一次),触发Young GC,回收后内存下降,但填充速率过快;
- Young GC详情:
-
Young GC Frequency: 1次/5s(正常应1次/30s以上)
-
Avg Young GC Pause: 80ms
-
-
智能诊断建议:"Young GC is occurring too frequently. This is likely due to high object allocation rate. Check if the application is creating unnecessary objects or large objects in the young generation."(Young GC频繁,可能是对象分配速率过高,检查应用是否创建不必要的对象或年轻代大对象)。
步骤3:代码层面排查
查看业务代码,发现/loopCreateTempObj接口中,循环创建大量1KB的临时字节数组,且循环次数极大(100万次),导致Eden区快速被填满,触发频繁Young GC:
// 问题代码
for (int i = 0; i < loopCount; i++) {
// 每次循环创建1KB临时对象,100万次就是1GB,Eden区512m,快速填满
byte[] temp = new byte[1024];
if (i % 10000 == 0) {
log.info("已循环创建临时对象次数:{}", i);
}
}
步骤4:优化方案
-
减少临时对象创建:将临时对象复用,避免每次循环创建新对象;
-
批量处理:分批次创建对象,减少单次循环的内存压力;
-
调整年轻代大小:通过JVM参数增大年轻代比例(G1收集器可通过-XX:G1NewSizePercent、-XX:G1MaxNewSizePercent调整)。
优化后的代码:
/**
* 优化后:循环创建大量临时对象,复用对象减少分配
* @param loopCount 循环次数
* @return 操作结果
*/
@Operation(summary = "优化后循环创建临时对象", description = "复用临时对象,减少Young GC频率")
@GetMapping("/optimizedLoopCreateTempObj")
public String optimizedLoopCreateTempObj(@Parameter(description = "循环次数") @RequestParam Integer loopCount) {
StringUtils.hasText(loopCount.toString(), "循环次数不能为空");
if (loopCount <= 0) {
log.error("循环次数必须大于0");
return "循环次数必须大于0";
}
// 复用临时对象,避免每次循环创建新对象
byte[] temp = new byte[1024];
// 分批次处理,每10万次休息10ms,缓解内存压力
int batchSize = 100000;
int batchCount = loopCount / batchSize;
int remain = loopCount % batchSize;
for (int i = 0; i < batchCount; i++) {
for (int j = 0; j < batchSize; j++) {
// 复用temp对象,仅修改内容(若无需修改可直接复用)
Arrays.fill(temp, (byte) (j % 256));
}
log.info("已完成批次:{},累计处理次数:{}", i + 1, (i + 1) * batchSize);
// 短暂休息,让GC有时间回收其他对象
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("线程休息异常", e);
}
}
// 处理剩余次数
for (int i = 0; i < remain; i++) {
Arrays.fill(temp, (byte) (i % 256));
}
log.info("循环创建临时对象完成,总次数:{}", loopCount);
return "优化后循环创建临时对象完成,总次数:" + loopCount;
}
调整JVM参数(增大年轻代比例):
-Xms512m -Xmx512m -XX:+UseG1GC -XX:G1NewSizePercent=40 -XX:G1MaxNewSizePercent=60 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100m -Xlog:gc*:file=./gc_optimized.log:time,tags:filecount=5,filesize=100m
参数说明:
-
-XX:G1NewSizePercent=40:年轻代最小比例为堆内存的40%(512m堆则年轻代最小204.8m);
-
-XX:G1MaxNewSizePercent=60:年轻代最大比例为堆内存的60%(512m堆则年轻代最大307.2m)。
步骤5:验证优化效果
重新生成GC日志(gc_optimized.log),上传到GCEasy对比分析:
-
Young GC Frequency: 1次/35s(优化前1次/5s,大幅降低);
-
GC Throughput: 99.6%(优化前98.5%,提升至推荐阈值以上);
-
Average GC Pause: 45ms(优化前80ms,大幅降低);
-
智能诊断建议:无警告,显示“GC performance is good. No critical issues detected.”(GC性能良好,无严重问题)。
案例2:Full GC频繁导致服务卡顿问题定位与优化
问题现象
服务运行过程中,每15分钟出现一次卡顿(持续约1s),监控显示卡顿时刻发生Full GC,Full GC次数达“4次/小时”,严重影响用户体验。
步骤1:生成并上传GC日志
通过/batchCreateUser接口传入count=200000,生成大量对象进入老年代,触发Full GC,上传GC日志到GCEasy。
步骤2:GCEasy分析定位问题
- 概览模块:
-
GC Throughput: 95.2%(低于推荐阈值99%);
-
Total GC Events: 80(1小时内),其中Young GC: 72,Full GC: 8(2次/15min);
-
Average GC Pause: 280ms,Max GC Pause: 1200ms(卡顿根源);
-
-
内存使用趋势:老年代内存持续上升,每15分钟达到最大堆内存(512m),触发Full GC,Full GC后内存仅下降10%(说明大部分对象无法回收,疑似内存泄漏);
- Full GC详情:
-
Full GC Count: 8次/小时;
-
Avg Full GC Pause: 950ms,Max Full GC Pause: 1200ms;
-
-
智能诊断建议:"Full GC is occurring frequently. This indicates a potential memory leak or insufficient old generation space. The old generation is filling up quickly and Full GC is not able to free up much memory."(Full GC频繁,可能存在内存泄漏或老年代空间不足,老年代快速填满且Full GC无法回收大量内存)。
步骤3:代码层面排查
查看/batchCreateUser接口的业务逻辑,发现用户列表对象在插入数据库后,被存储到了一个静态集合中,且未做清理,导致对象无法被GC回收,持续进入老年代,最终触发Full GC:
// 问题代码:静态集合存储用户列表,无清理逻辑,导致内存泄漏
private static List<User> userCache = Lists.newArrayList();
@GetMapping("/batchCreateUser")
public String batchCreateUser(@RequestParam Integer count) {
// 省略参数校验...
try {
List<User> userList = IntStream.range(0, count)
.mapToObj(i -> new User()
.setUserName("test_user_" + i)
.setAge(20 + i % 30)
.setEmail("test_" + i + "@demo.com")
.setPhone("1380013800" + (i % 10)))
.collect(Collectors.toList());
boolean success = userService.saveBatch(userList);
if (success) {
// 问题根源:静态集合持续添加对象,无清理,导致内存泄漏
userCache.addAll(userList);
log.info("批量创建用户成功,数量:{},缓存用户总数:{}", count, userCache.size());
// ...
}
// ...
} catch (Exception e) {
// ...
}
}
步骤4:优化方案
-
修复内存泄漏:移除静态集合的不当使用,若需要缓存,使用带过期时间的缓存框架(如Caffeine、Redis),避免对象永久驻留内存;
-
清理无用对象:在业务逻辑结束后,及时将不再使用的对象置为null,帮助GC回收;
-
调整G1收集器参数:优化Full GC触发时机和回收效率。
优化后的代码:
// 优化1:移除静态集合,使用带过期时间的Caffeine缓存(添加Caffeine依赖)
// pom.xml添加Caffeine依赖
<!-- Caffeine缓存(带过期时间) -->
<dependency>
<groupId>com.github.benmanes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>
// 配置Caffeine缓存
package com.jam.demo.config;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.TimeUnit;
/**
* 缓存配置
* @author ken
*/
@Configuration
public class CacheConfig {
/**
* Caffeine缓存管理器(设置过期时间,避免内存泄漏)
* @return CacheManager
*/
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
// 配置缓存过期时间:10分钟,自动清理过期对象
cacheManager.setCaffeine(Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10000) // 最大缓存数量,避免缓存过多
);
return cacheManager;
}
}
// 优化后的接口代码
@Slf4j
@RestController
@RequiredArgsConstructor
@Tag(name = "GC测试接口", description = "用于模拟内存压力,生成GC日志")
public class GcTestController {
private final UserService userService;
private final CacheManager cacheManager;
@Operation(summary = "优化后批量创建用户", description = "使用带过期时间的缓存,避免内存泄漏")
@GetMapping("/optimizedBatchCreateUser")
public String optimizedBatchCreateUser(@Parameter(description = "用户数量") @RequestParam Integer count) {
StringUtils.hasText(count.toString(), "用户数量不能为空");
if (count <= 0) {
log.error("用户数量必须大于0");
return "用户数量必须大于0";
}
try {
List<User> userList = IntStream.range(0, count)
.mapToObj(i -> new User()
.setUserName("test_user_" + i)
.setAge(20 + i % 30)
.setEmail("test_" + i + "@demo.com")
.setPhone("1380013800" + (i % 10)))
.collect(Collectors.toList());
boolean success = userService.saveBatch(userList);
if (success) {
// 优化2:使用带过期时间的缓存,10分钟后自动清理
Cache userCache = cacheManager.getCache("userCache");
if (ObjectUtils.isEmpty(userCache)) {
log.error("用户缓存初始化失败");
return "用户缓存初始化失败";
}
// 按用户ID缓存,避免批量缓存大量对象
userList.forEach(user -> userCache.put(user.getId(), user));
log.info("批量创建用户成功,数量:{},缓存用户数量:{}", count, userList.size());
// 优化3:及时置空无用对象,帮助GC回收
userList = null;
return "优化后批量创建用户成功,数量:" + count;
} else {
log.error("批量创建用户失败");
return "批量创建用户失败";
}
} catch (Exception e) {
log.error("批量创建用户异常", e);
return "批量创建用户异常:" + e.getMessage();
}
}
}
// 优化G1收集器参数,减少Full GC频率
-Xms1024m -Xmx1024m -XX:+UseG1GC -XX:G1ReservePercent=20 -XX:InitiatingHeapOccupancyPercent=45 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100m -Xlog:gc*:file=./gc_full_gc_optimized.log:time,tags:filecount=5,filesize=100m
参数说明:
-
-Xms1024m -Xmx1024m:增大堆内存,减少老年代压力;
-
-XX:G1ReservePercent=20:设置老年代预留空间比例(20%),避免老年代快速填满;
-
-XX:InitiatingHeapOccupancyPercent=45:G1触发混合回收的堆占用阈值(45%),提前进行回收,避免触发Full GC。
步骤5:验证优化效果
重新生成GC日志(gc_full_gc_optimized.log),上传到GCEasy分析:
-
Full GC Count: 0次/小时(优化前8次/小时,彻底解决Full GC频繁问题);
-
GC Throughput: 99.8%(优化前95.2%,提升至推荐阈值以上);
-
Max GC Pause: 280ms(优化前1200ms,卡顿问题彻底解决);
-
内存使用趋势:老年代内存稳定在30%左右,无持续上升趋势,混合回收(G1的Mixed GC)能有效回收老年代对象,无需触发Full GC。
案例3:GC吞吐量过低问题定位与优化
问题现象
服务GC吞吐量仅为92%,低于推荐阈值99%,导致服务响应时间变长(平均响应时间从200ms上升到500ms),影响系统并发能力。同时监控显示,高并发场景下(如秒杀活动),吞吐量进一步下跌至85%,出现部分接口超时熔断的情况,直接影响业务可用性。
步骤1:生成并上传高压力GC日志
通过JMeter模拟高并发场景:配置100个并发线程,循环调用/loopCreateTempObj接口(传入loopCount=100000),持续2分钟生成高压力下的GC日志。启动应用时指定JVM参数(G1收集器,堆内存1G):
-Xms1024m -Xmx1024m -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100m -Xlog:gc*:file=./gc_low_throughput.log:time,tags:filecount=5,filesize=100m
测试结束后,将生成的gc_low_throughput.log上传至GCEasy进行分析。
步骤2:GCEasy深度分析定位问题
-
概览模块核心指标:
-
GC Throughput: 92%(严重低于99%推荐阈值);
-
Total GC Time: 48s(10分钟内,占总运行时间的8%);
-
Total GC Events: 320次(Young GC: 315次,Full GC: 5次);
-
Average GC Pause: 150ms(超过100ms合理阈值);
-
Max GC Pause: 380ms(接近500ms超时阈值)。
-
-
吞吐量趋势模块(Throughput Trend): 吞吐量呈“波浪式下跌”趋势——并发请求启动后,吞吐量从初始98%快速跌至85%,随后稳定在92%左右。这表明高并发下的高频对象创建,是导致吞吐量骤降的直接诱因。
-
内存分配与回收趋势:
-
Eden区内存填充速率极快(每秒填充80MB),每3-5秒就触发一次Young GC;
-
每次Young GC回收效率仅60%(正常应≥80%),部分临时对象因存活时间过长晋升至老年代;
-
老年代内存持续增长,10分钟内从150MB升至850MB(接近1G堆上限),触发5次Full GC,进一步拉低吞吐量。
-
-
智能诊断建议:
Critical: GC throughput is low (92%). This is caused by high GC overhead from frequent object allocation and inefficient Young GC recycling. Recommendations: 1. Optimize application code to reduce temporary object creation (e.g., string concatenation, unnecessary serialization); 2. Adjust G1 GC parameters to improve young generation recycling efficiency; 3. Consider switching to ZGC (JDK17+) for high concurrency scenarios to reduce GC pause time.
翻译:GC吞吐量过低(92%),原因是频繁对象分配和Young GC回收效率低导致的高GC开销。建议:1. 优化应用代码减少临时对象创建(如字符串拼接、不必要的序列化);2. 调整G1参数提升年轻代回收效率;3. 高并发场景考虑切换至ZGC(JDK17+)降低GC停顿时间。
-
关键结论: 高并发下频繁创建临时对象(如字符串、字节数组),导致Eden区快速溢出,Young GC频繁触发;同时Young GC回收不彻底,部分对象晋升老年代引发Full GC,大量GC停顿时间挤压业务执行时间,最终导致吞吐量大幅下降。
步骤3:代码层面排查——定位临时对象泛滥根源
查看高并发调用的/loopCreateTempObj接口代码,发现两处核心问题:
// 问题代码片段
@GetMapping("/loopCreateTempObj")
public String loopCreateTempObj(@RequestParam Integer loopCount) {
StringUtils.hasText(loopCount.toString(), "循环次数不能为空");
if (loopCount <= 0) {
log.error("循环次数必须大于0");
return "循环次数必须大于0";
}
for (int i = 0; i < loopCount; i++) {
byte[] temp = new byte[1024]; // 每次循环创建1KB临时字节数组
// 问题1:使用+号拼接字符串,每次生成新String对象
String logMsg = "循环次数:" + i + ",临时对象大小:" + temp.length + "KB";
if (i % 10000 == 0) {
log.info(logMsg); // 高并发下高频日志打印,生成大量字符串对象
}
}
log.info("循环创建临时对象完成,总次数:" + loopCount); // 再次使用+号拼接
return "循环创建临时对象完成,总次数:" + loopCount;
}
问题拆解:
-
字符串拼接问题:使用
+号拼接日志字符串,每次拼接都会创建新的String和char[]对象(String不可变特性)。100并发×100000循环=10^7次拼接,生成10^7个临时字符串对象,直接导致Eden区快速溢出; -
临时字节数组频繁创建:循环内每次都新建1KB的
byte[],无复用机制,进一步加剧内存分配压力; -
日志打印频率过高:每10000次循环打印一次日志,高并发下日志字符串对象累积,增加GC回收负担。
步骤4:分层优化方案——从代码到JVM的全维度优化
针对问题根源,采用“代码层优化→JVM参数优化→收集器升级”的分层方案,确保优化效果可量化、可落地。
4.1 代码层优化——减少临时对象创建
优化1:使用StringBuilder复用字符串拼接
替换+号拼接为StringBuilder复用,避免每次创建新字符串对象:
/**
* 优化1:使用StringBuilder复用,减少字符串拼接临时对象
* @param loopCount 循环次数
* @return 操作结果
*/
@Operation(summary = "优化后循环创建临时对象(字符串拼接优化)", description = "复用StringBuilder减少临时对象,提升GC效率")
@GetMapping("/optimizedLoopCreateTempObj1")
public String optimizedLoopCreateTempObj1(@Parameter(description = "循环次数") @RequestParam Integer loopCount) {
StringUtils.hasText(loopCount.toString(), "循环次数不能为空");
if (loopCount <= 0) {
log.error("循环次数必须大于0");
return "循环次数必须大于0";
}
// 复用StringBuilder,避免每次循环创建新对象
StringBuilder logBuilder = new StringBuilder();
// 复用临时字节数组,减少对象创建
byte[] temp = new byte[1024];
for (int i = 0; i < loopCount; i++) {
// 复用temp对象,仅修改内容(无需新建)
Arrays.fill(temp, (byte) (i % 256));
if (i % 100000 == 0) { // 优化2:降低日志打印频率(从1万次→10万次)
logBuilder.setLength(0); // 重置长度,复用对象
logBuilder.append("循环次数:")
.append(i)
.append(",临时对象大小:")
.append(temp.length)
.append("KB");
log.info(logBuilder.toString());
}
}
// 复用logBuilder打印结束日志
logBuilder.setLength(0);
logBuilder.append("循环创建临时对象完成,总次数:")
.append(loopCount);
log.info(logBuilder.toString());
return logBuilder.toString();
}
优化2:引入对象池复用高频临时对象
对于高频创建的临时对象(如byte[]),使用Caffeine实现轻量级对象池,进一步减少对象创建开销:
// 1. 对象池配置类
package com.jam.demo.config;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.TimeUnit;
/**
* 临时对象池配置(复用高频创建的字节数组)
* @author ken
*/
@Configuration
public class TempObjectPoolConfig {
/**
* 1KB字节数组对象池
* @return LoadingCache<String, byte[]> 键:对象标识,值:1KB字节数组
*/
@Bean
public LoadingCache<String, byte[]> byteArrayPool() {
return Caffeine.newBuilder()
.maximumSize(1000) // 最大缓存对象数(适配100并发)
.expireAfterAccess(5, TimeUnit.MINUTES) // 5分钟无访问自动回收,避免内存泄漏
.build(key -> new byte[1024]); // 无对象时创建新实例
}
}
// 2. 优化后接口(使用对象池复用字节数组)
@Operation(summary = "优化后循环创建临时对象(对象池复用)", description = "使用Caffeine对象池复用字节数组,进一步减少GC压力")
@GetMapping("/optimizedLoopCreateTempObj2")
public String optimizedLoopCreateTempObj2(@Parameter(description = "循环次数") @RequestParam Integer loopCount) {
StringUtils.hasText(loopCount.toString(), "循环次数不能为空");
if (loopCount <= 0) {
log.error("循环次数必须大于0");
return "循环次数必须大于0";
}
StringBuilder logBuilder = new StringBuilder();
for (int i = 0; i < loopCount; i++) {
try {
// 从对象池获取复用的1KB字节数组
byte[] temp = byteArrayPool.get("1kb_byte_array_" + (i % 1000));
Arrays.fill(temp, (byte) (i % 256));
} catch (Exception e) {
log.error("获取对象池字节数组异常", e);
// 降级策略:创建新对象
byte[] temp = new byte[1024];
Arrays.fill(temp, (byte) (i % 256));
}
if (i % 100000 == 0) {
logBuilder.setLength(0);
logBuilder.append("循环次数:")
.append(i)
.append(",临时对象大小:1024KB");
log.info(logBuilder.toString());
}
}
logBuilder.setLength(0);
logBuilder.append("循环创建临时对象完成,总次数:")
.append(loopCount);
log.info(logBuilder.toString());
return logBuilder.toString();
}
4.2 JVM参数优化——提升G1回收效率
针对G1收集器,调整核心参数以提升年轻代回收效率,减少GC停顿时间:
-Xms2048m -Xmx2048m -XX:+UseG1GC -XX:G1NewSizePercent=40 -XX:G1MaxNewSizePercent=60 -XX:MaxGCPauseMillis=50 -XX:G1ReservePercent=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xlog:gc*:file=./gc_optimized_g1.log:time,tags:filecount=5,filesize=100m
参数解读:
-
-Xms2048m -Xmx2048m:增大堆内存至2G,降低内存分配压力; -
-XX:G1NewSizePercent=40 -XX:G1MaxNewSizePercent=60:固定年轻代占比为堆内存的40%-60%(即819MB-1228MB),避免年轻代动态调整过小导致的频繁GC; -
-XX:MaxGCPauseMillis=50:设置最大GC停顿目标为50ms,引导G1优化回收策略(如调整Region大小、回收线程数); -
-XX:G1ReservePercent=20:老年代预留20%空间,避免年轻代对象晋升时老年代空间不足导致的Full GC; -
-XX:InitiatingHeapOccupancyPercent=35:堆内存占用达到35%时触发G1混合回收,提前回收老年代部分对象,减少Full GC风险。
4.3 收集器升级——JDK17+ZGC(高并发终极方案)
JDK17中ZGC已成为稳定版本,支持TB级堆内存,停顿时间稳定在10ms以内,适合高并发场景。升级ZGC的JVM参数:
-Xms4096m -Xmx4096m -XX:+UseZGC -XX:ZGCParallelGCThreads=8 -XX:ZGCCycleDelay=5 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xlog:gc*:file=./gc_optimized_zgc.log:time,tags:filecount=5,filesize=100m
参数解读:
-
-Xms4096m -Xmx4096m:堆内存设置为4G,适配高并发下的内存需求; -
-XX:+UseZGC:启用ZGC收集器; -
-XX:ZGCParallelGCThreads=8:设置并行回收线程数为8(建议为CPU核心数的1/2,如16核CPU设置8线程); -
-XX:ZGCCycleDelay=5:ZGC回收周期延迟5秒,平衡回收效率与CPU开销。
4.4 架构层优化——异步处理非核心逻辑
将日志打印、数据序列化等非核心逻辑异步化,避免阻塞主线程的同时,减少同步场景下的临时对象累积:
// 1. 异步任务配置类
package com.jam.demo.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
/**
* 异步任务配置
* @author ken
*/
@Configuration
@EnableAsync
public class AsyncConfig {
/**
* 日志打印异步线程池
* @return Executor 异步线程池
*/
@Bean("logAsyncExecutor")
public Executor logAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5); // 核心线程数
executor.setMaxPoolSize(10); // 最大线程数
executor.setQueueCapacity(25); // 队列容量
executor.setThreadNamePrefix("LogAsync-"); // 线程名前缀
executor.initialize();
return executor;
}
}
// 2. 异步日志服务类
package com.jam.demo.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
/**
* 异步日志服务
* @author ken
*/
@Slf4j
@Service
public class AsyncLogService {
/**
* 异步打印日志
* @param logMsg 日志内容
*/
@Async("logAsyncExecutor")
public void asyncPrintLog(String logMsg) {
log.info(logMsg);
}
}
// 3. 优化后接口(异步日志打印)
@Operation(summary = "最终优化版循环创建临时对象", description = "整合字符串复用、对象池、异步日志,最大化减少GC压力")
@GetMapping("/finalOptimizedLoopCreateTempObj")
public String finalOptimizedLoopCreateTempObj(@Parameter(description = "循环次数") @RequestParam Integer loopCount) {
StringUtils.hasText(loopCount.toString(), "循环次数不能为空");
if (loopCount <= 0) {
log.error("循环次数必须大于0");
return "循环次数必须大于0";
}
StringBuilder logBuilder = new StringBuilder();
for (int i = 0; i < loopCount; i++) {
try {
// 复用字节数组
byte[] temp = byteArrayPool.get("1kb_byte_array_" + (i % 1000));
Arrays.fill(temp, (byte) (i % 256));
} catch (Exception e) {
log.error("获取对象池字节数组异常", e);
byte[] temp = new byte[1024];
Arrays.fill(temp, (byte) (i % 256));
}
if (i % 100000 == 0) {
logBuilder.setLength(0);
logBuilder.append("循环次数:")
.append(i)
.append(",临时对象大小:1024KB");
// 异步打印日志,避免阻塞主线程
asyncLogService.asyncPrintLog(logBuilder.toString());
}
}
logBuilder.setLength(0);
logBuilder.append("循环创建临时对象完成,总次数:")
.append(loopCount);
asyncLogService.asyncPrintLog(logBuilder.toString());
return logBuilder.toString();
}
步骤5:优化效果验证——GCEasy对比分析
使用相同的JMeter测试脚本(100并发×100000循环),分别对“优化前”“G1参数优化后”“ZGC+全量优化后”三个版本进行测试,生成对应的GC日志并上传GCEasy对比分析。
5.1 核心GC指标对比
| 指标 | 优化前 | G1参数优化后 | ZGC+全量优化后 |
|---|---|---|---|
| GC Throughput | 92% | 97.8% | 99.9% |
| Total GC Time(10min) | 48s | 10.2s | 0.8s |
| Average GC Pause | 150ms | 32ms | 2ms |
| Max GC Pause | 380ms | 75ms | 7ms |
| Young GC频率 | 315次/10min | 78次/10min | 15次/10min |
| Full GC次数 | 5次/10min | 0次/10min | 0次/10min |
5.2 业务指标对比
| 业务指标 | 优化前 | G1参数优化后 | ZGC+全量优化后 |
|---|---|---|---|
| 平均响应时间 | 500ms | 220ms | 180ms |
| 峰值响应时间 | 800ms | 350ms | 210ms |
| 并发能力(QPS) | 600 | 950 | 1200 |
| 接口超时率 | 5% | 0.5% | 0% |
5.3 结论
-
代码层优化(StringBuilder复用、对象池)有效减少了60%的临时对象创建,Young GC频率降低60%;
-
G1参数优化后,吞吐量提升至97.8%,消除了Full GC,业务响应时间缩短56%;
-
ZGC+全量优化后,吞吐量达到99.9%(接近理想状态),最大GC停顿仅7ms,并发能力提升100%,彻底解决了高并发下的吞吐量过低问题。
六、GCEasy进阶技巧——提升分析效率的核心方法
6.1 对比分析功能——量化优化效果
当我们对JVM参数或代码进行优化后,需要精准量化优化效果。GCEasy的“Compare”功能可实现这一需求:
-
点击GCEasy首页的“Compare”按钮;
-
上传优化前(如
gc_low_throughput.log)和优化后(如gc_optimized_zgc.log)的两个GC日志文件; -
生成对比报告,报告将直观展示两个日志的核心指标差异(吞吐量、GC次数、停顿时间等),并生成对比图表,无需手动统计。
6.2 过滤与筛选——聚焦关键时间段
对于大体积GC日志(如100MB以上),可通过GCEasy的“Filter”功能聚焦关键时间段:
-
在分析报告页面,点击顶部“Filter”按钮;
-
选择“Custom Range”,设置需要分析的起始时间和结束时间(如仅分析秒杀活动期间的GC情况);
-
系统将重新生成该时间段的分析报告,过滤无关日志,提升分析效率。
6.3 集成CLI工具——自动化分析
对于需要集成到CI/CD或监控系统的场景,可使用GCEasy的CLI工具(命令行界面)实现自动化分析:
-
下载CLI工具:https://gceasy.io/cli.jsp;
-
执行分析命令(示例):
# 本地日志分析
java -jar gceasy-cli-1.0.0.jar --file ./gc.log --output ./gceasy-report.html
# 远程日志分析(从OSS下载日志)
java -jar gceasy-cli-1.0.0.jar --url https://xxx.oss-cn-beijing.aliyuncs.com/gc.log --output ./gceasy-report.html
-
生成HTML格式报告,可集成到Jenkins、GitLab CI等平台,实现“代码提交→自动测试→GC分析→报告生成”的全流程自动化。
6.4 高级诊断功能——定位复杂问题
对于内存泄漏、并发导致的GC问题,可使用GCEasy的高级诊断功能:
-
内存泄漏检测:在“Memory Leak Detection”模块,GCEasy会分析老年代内存增长趋势,若存在“持续上升且Full GC无法回收”的情况,会标记为“Potential Memory Leak”,并给出可疑对象的存活时间分析;
-
并发压力分析:在“Concurrency Pressure”模块,可查看GC期间的线程数、CPU使用率等指标,判断是否存在“线程过多导致的内存竞争”问题;
-
JVM参数建议:在“JVM Arguments Recommendations”模块,GCEasy会根据当前日志的GC情况,给出针对性的JVM参数调整建议(如堆内存大小、收集器选择、回收线程数等)。
七、核心知识点总结——从原理到实践的关键沉淀
7.1 GC吞吐量的核心逻辑
GC吞吐量 =(总运行时间 - 总GC停顿时间)/ 总运行时间 × 100%,其本质是“业务代码执行时间占总时间的比例”。要提升吞吐量,核心是减少GC停顿时间和GC频率,关键在于:
-
控制对象分配速率:减少临时对象创建,复用高频对象;
-
优化GC回收效率:选择合适的收集器(如高并发选ZGC),调整JVM参数;
-
避免Full GC:Full GC停顿时间是Young GC的10-100倍,应通过参数优化和代码优化彻底避免。
7.2 G1与ZGC的适用场景区分
| 收集器 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| G1 | 中低并发、堆内存<4G | 兼容性好、配置成熟 | 高并发下吞吐量较低 |
| ZGC | 高并发、堆内存≥4G | 低停顿(<10ms)、高吞吐量 | JDK11+支持,需更大内存 |
7.3 临时对象优化的核心原则
-
字符串拼接:优先使用StringBuilder复用,避免
+号拼接;日志打印优先使用参数化日志(如log.info("循环次数:{}", i)); -
高频对象:使用对象池(Caffeine、Apache Commons Pool)复用,减少创建开销;
-
非核心逻辑:异步化处理(如日志打印、序列化),避免同步场景下的对象累积。
7.4 GCEasy分析的核心流程
-
先看概览:通过Summary模块快速判断GC吞吐量、停顿时间、GC次数是否正常;
-
再看趋势:通过Memory Usage Trend、Throughput Trend定位问题触发场景(如高并发、特定业务流程);
-
查详情:通过GC Details by Generation模块区分问题出在Young GC还是Full GC;
-
找建议:参考Diagnostics & Recommendations模块获取优化方向;
-
做验证:使用Compare功能量化优化效果。
八、总结
GCEasy作为GC日志分析的利器,彻底解决了手动分析日志的低效与繁琐问题,让开发者无需深入研究GC日志格式,就能快速定位内存泄漏、GC频繁、吞吐量过低等核心问题。本文从底层原理出发,通过“环境准备→基础使用→进阶实战→技巧总结”的全流程,结合3个生产级案例(Young GC频繁、Full GC卡顿、吞吐量过低),完整覆盖了GCEasy的核心使用场景。


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









