







 文章讲述了作者在机器学习和运筹学交叉领域的研究,通过在一阶段模型中加入文本数据特征并使用TF-IDF和BiGRU处理,展示了如何发表高质量论文。实验结果比较了几种方法,强调掌握核心方法对阅读和撰写论文的重要性。
文章讲述了作者在机器学习和运筹学交叉领域的研究,通过在一阶段模型中加入文本数据特征并使用TF-IDF和BiGRU处理,展示了如何发表高质量论文。实验结果比较了几种方法,强调掌握核心方法对阅读和撰写论文的重要性。
前段时间收到了欧洲岗位制博士的offer,最近也是开始写论文了,争取9月开学前写一篇。我的博士研究方向计划做机器学习和运筹学的结合,也是我之前写的一篇学习笔记相关的内容。所以这个文献阅读的合集也大都会是相关的文献阅读。
机器学习和运筹学的结合
华仔,公众号:算法设计与优化学习笔记8——报童模型扩展(数据驱动方法SAA;大数据驱动方法ERM:机器学习和运筹学的有机结合)含gurobi求解代码
上一篇阅读的文献是一篇来自EJOR的带有不可观测特征的一阶段模型,这一次是一篇来自IJPE的带有文本评论数据的一阶段模型,可见换汤不换药,只要抓住一个核心的点(比如一阶段模型),融合一点新的东西(不可观测特征、文本数据)就可以发一篇同等级别的文章,这两个期刊对于大多数博士、硕士来说也算是很不错的期刊了吧,所以,be confident!

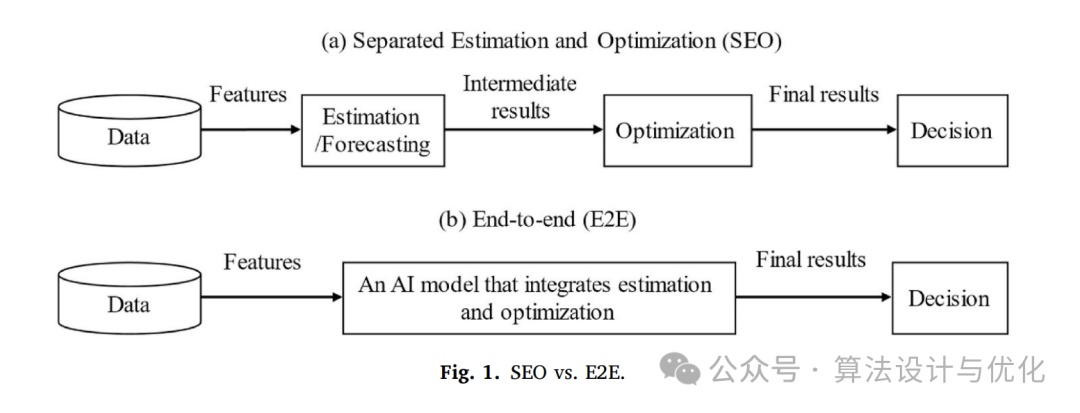
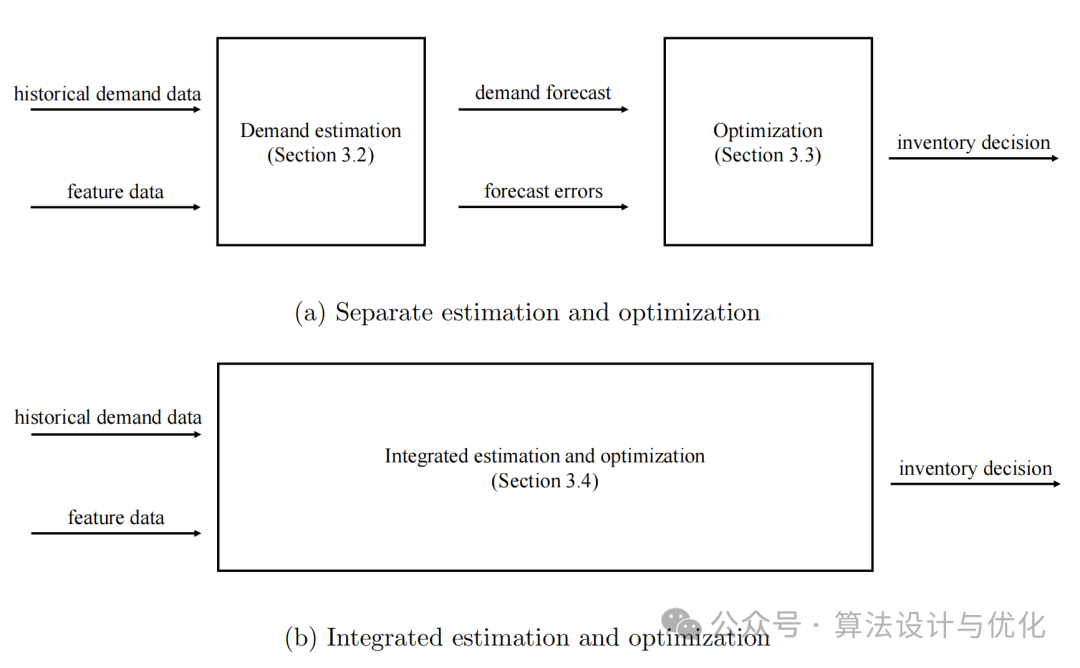
那这篇文章的核心就是在一阶段模型的基础上增加了一列文本数据特征,是不是很简单。下面第一个图(本文)画的是两阶段模型和一阶段模型的区别,与第二个图(Huber2019)中的图有点类似吧。所以看文章不仅仅是学习内容,还有学习画图技巧,虽然这个图也不高级哈哈!
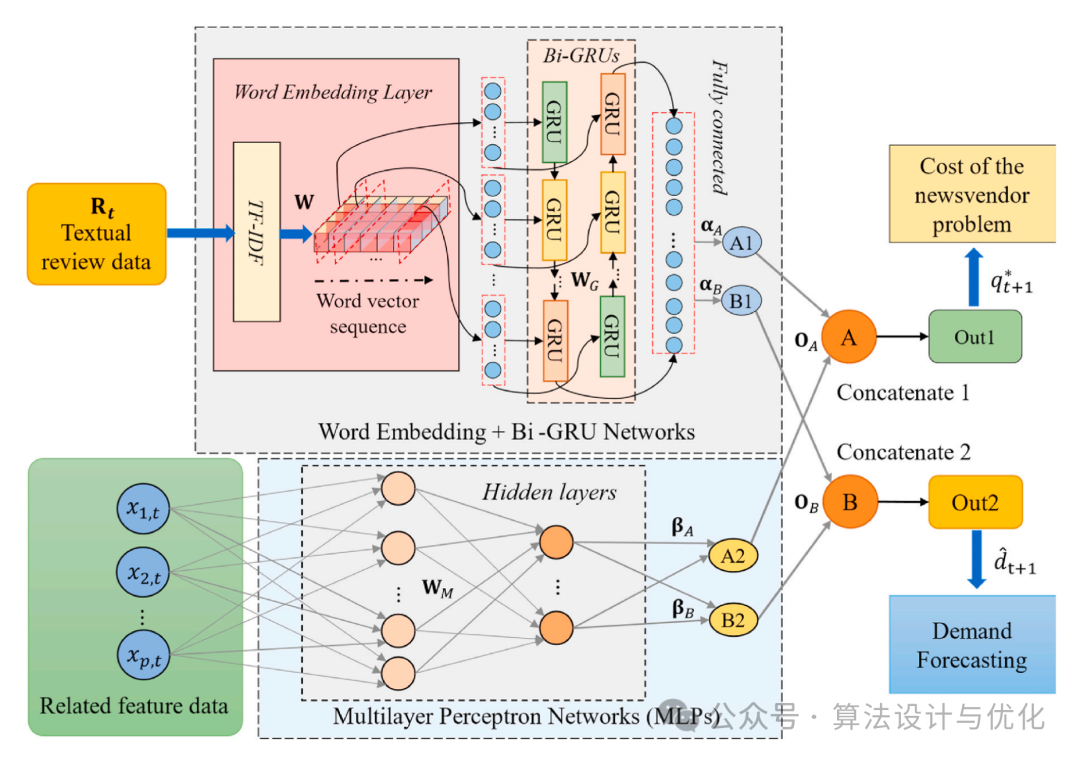
下图是本文的模型网络图,上面是文本数据模块,首先,通过TF-IDF进行分词、不重要词的过滤和独热编码矩阵变换,只保留重要信息;然后,将独热编码矩阵转换为等长的字向量序列,作为BiGRU网络的输入;最后,BiGRU网络的输出结果连接到一个全连接层,输出订单量和预测的需求量 ;(其实就是魔改网络——炼丹)
下面是其他特征模块,用了一个简单的MLP,输出订单量和预测的需求量 ,再将两个模块的输出连接起来作为最终结果。
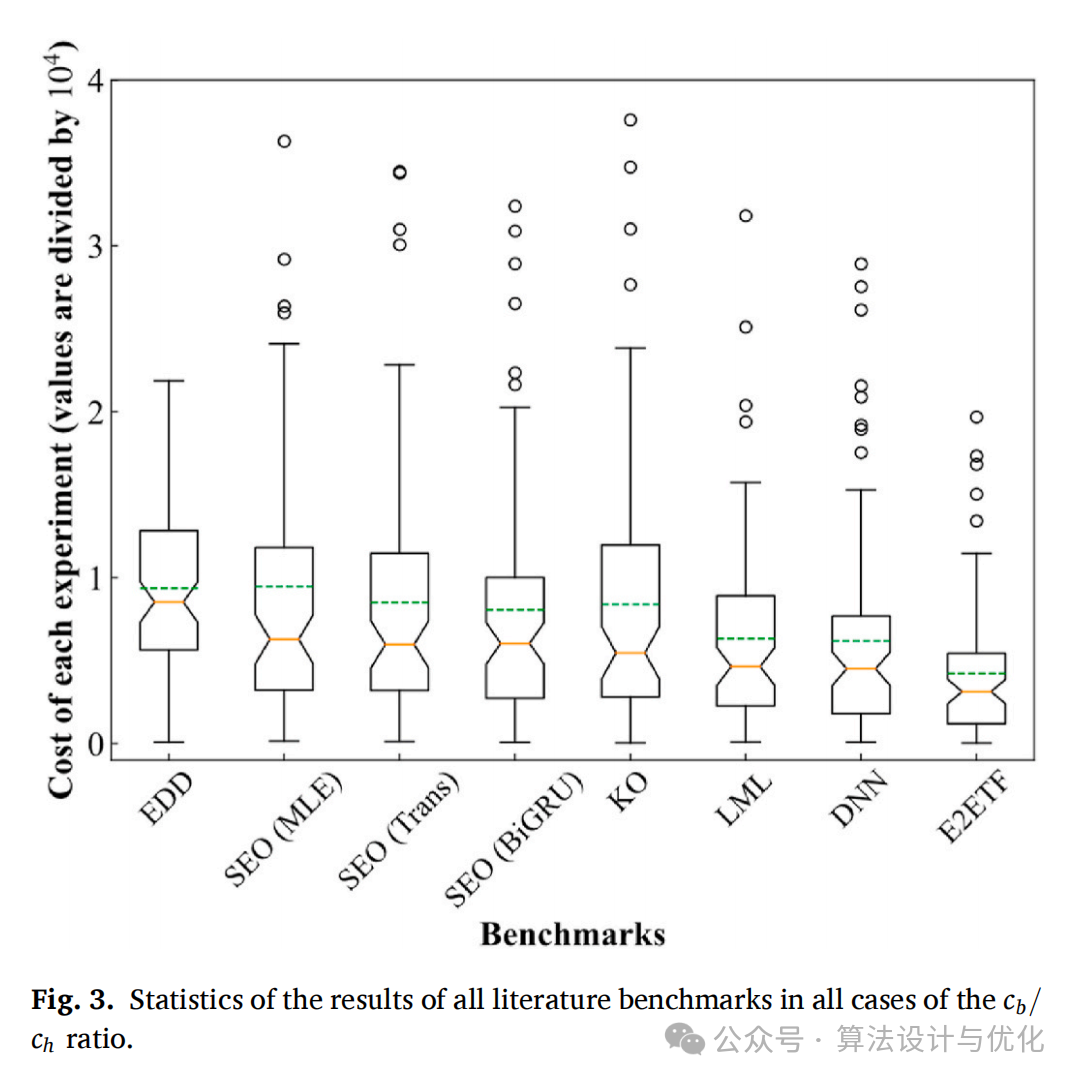
然后作者进行了试验分析,实验结果如下图所示:对比方法还是那几个方法嘛,EDD就是SAA,SEO就是两阶段模型,KO是核优化和ERM算法是一个级别的,LML就是一阶段模型用的线性模型,DNN就是一阶段模型用的非线性模型。
后面作者还做了消融实验(深度学习必做,就是有一个模块和没一个模块的区别)。
总的来说,就是多加了一个文本特征,而上一篇是多加了一个不可观测特征,所以朋友们,掌握秘诀了吗,哈哈哈哈!所以,只要掌握论文的核心方法,读文献还是很快的!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









