







上篇我们分析了CB,CF算法的原理,这里我们补充一下推荐系统的推荐场景的流程图:
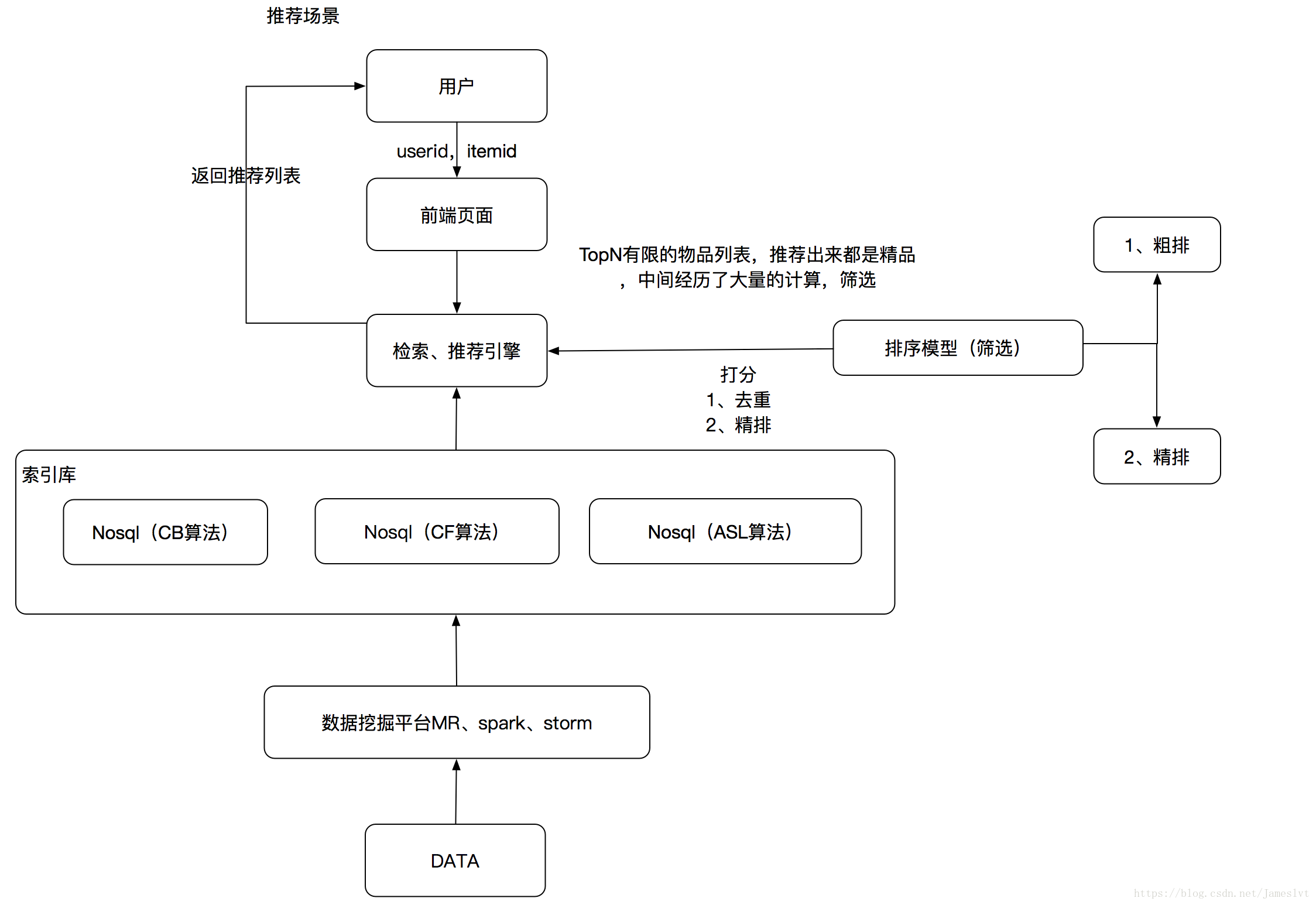
从推荐场景的流程图中,我们可以看到,最重要的部分就是这个索引库怎么计算得到,当然,不同的算法之间的实现方式不一样,首先我们来说一下CB算法,CB算法的实现主要是基于用户的历史行为(引入用户属性 CB)和用户当下购买的物品(引入item属性)进行推荐,主要的实现方法是正排—》倒排索引式的实现方法,那么接下来我们来看下代码:
CB实现方式:倒排索引
1、要处理的用户数据(当然这部分数据是已经收集好的,用来直接处理的数据),假如小猪同学听了这么多音乐,左边代表音乐编号,右边是音乐名称

知道了原始数据,那么假如小猪同学一天,又登陆的这个某某音乐平台,我们怎么基于CB算法来给小猪同学推荐音乐,当然,只是推荐TopN的音乐,接下来我们用代码的方式分析一下,说下这里我们在场景图中的Nosql数据库我们用到的是redis数据库:
首先我们要将原始的数据进行倒排索引归纳整理,把正排表先转换为倒排表,这里我们说下思路:
就是说我们要先把小猪同学听的音乐通过分词的方式把里面的重要的信息给提取出来,同时给音乐中的每个词做一个tfidf(这里我们就把上几次博客中的技术都给结合起来)计算出出各个词在相应的音乐中的权重值,
TF-IDF 公式:
TF 1、词频(TF)= 某个词在文章中出现的次数/文章的总词数
2、词频(TF)= 某个词在文章中出现的次数/该文出现次数最多的词出现的次数
IDF 反文档频率(IDF)= log(语料库的文档总数/包含该词文档的数+1)
TF-IDF = 词频(TF)* 反文档频率(IDF)
当然这个分词用结巴调用接口直接就可以实现,那么上面是不同的用户听的不同的音乐,接下来我们要根据不同用户听的不同音乐来给用户推荐排名靠前的(TopN)音乐,这个是我们代码实现的目的,我们来看下如何用MapReduce实现这个CB算法中的倒排索引功能,这里我们需要说明一下,由于我们的数据是要往Nosql数据库中去存储,这里的nosql使用的是redis数据库,存储以key-value的形式去存储,这个key我们用每个截取汉字对应的id来存储,当然value也使用每个音乐的名称,所以下面我们需要把对应的token转换成id。
-
原始数据

-
map实现,这个map实现的是将上面的musicName通过使用结巴分词模块下的TFIDF计算进行词的切分和TFIDF权重值的计算,输出的结果是musicId,musicName,切分词以及权重值
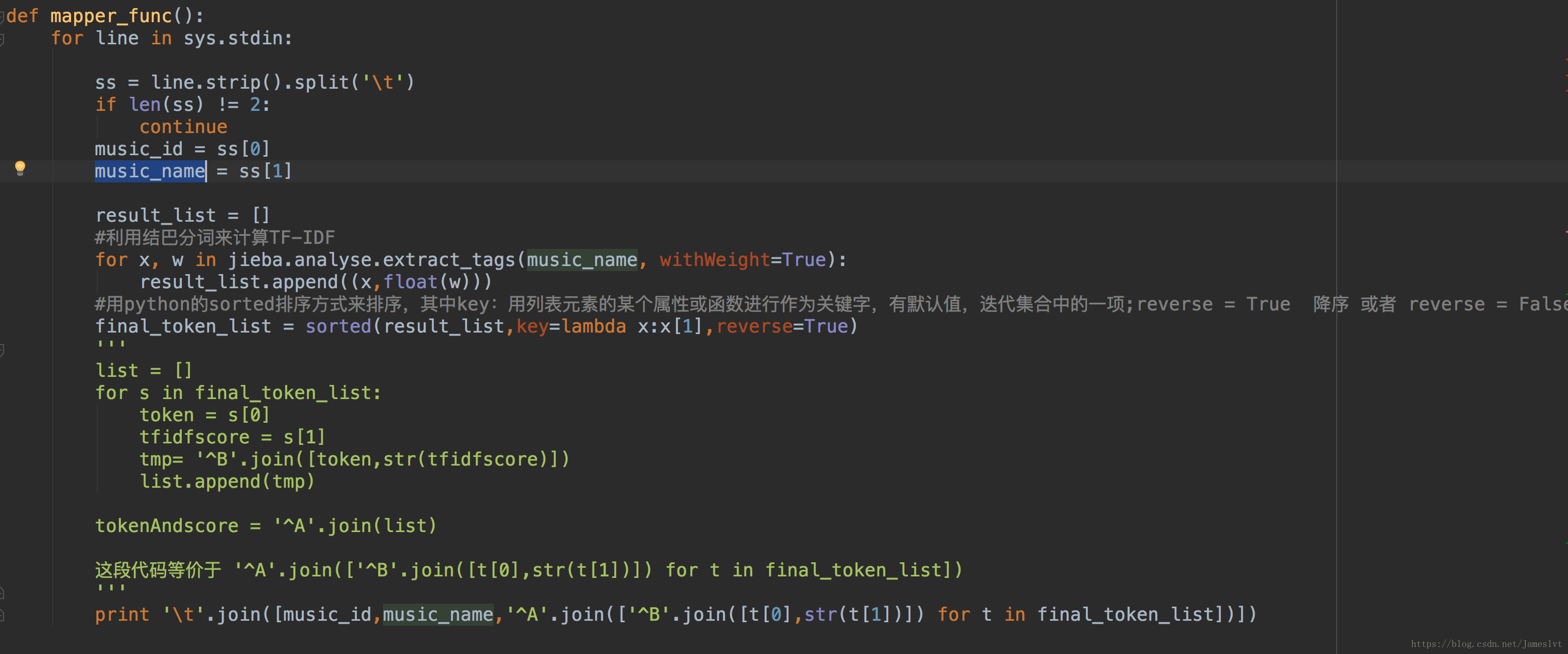
Map输出的结果,中间可以看出来musciId musicName 分词权重是以tab分割开,token(分的词)和权重值是以^B分割,每个分词是以^A分割

-
Map_inverted ,将上次出来的结果进行转换,输出以token,Name,权重值
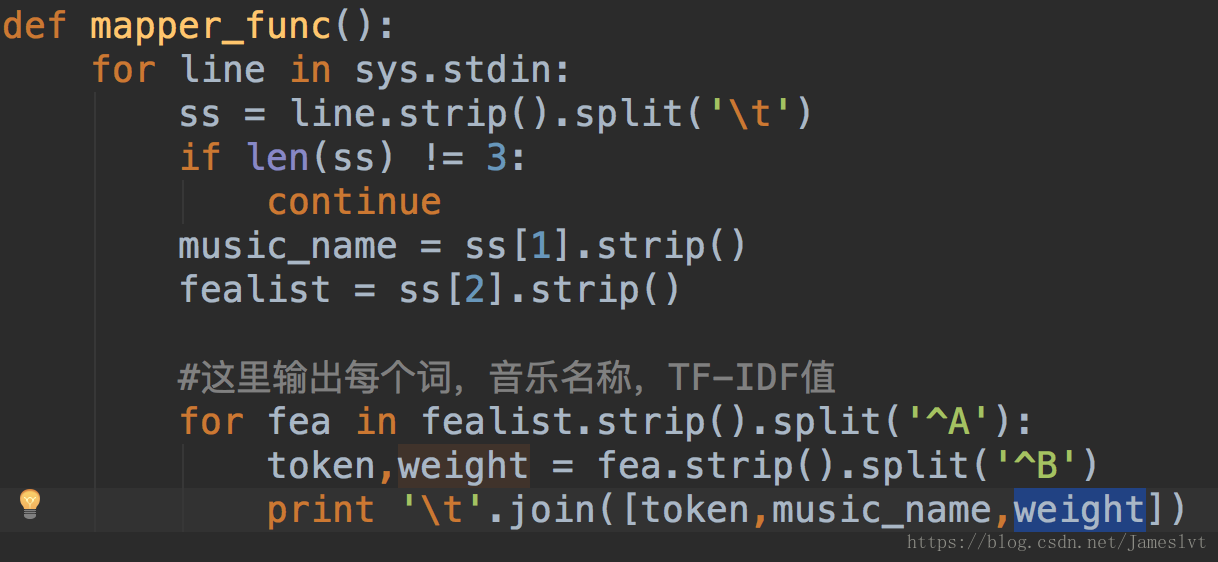
-
red_inverted ,最后我们进行reduce计算,将包含相同token的musicName 归纳起来,并且输出该词在当前音乐中的权重值
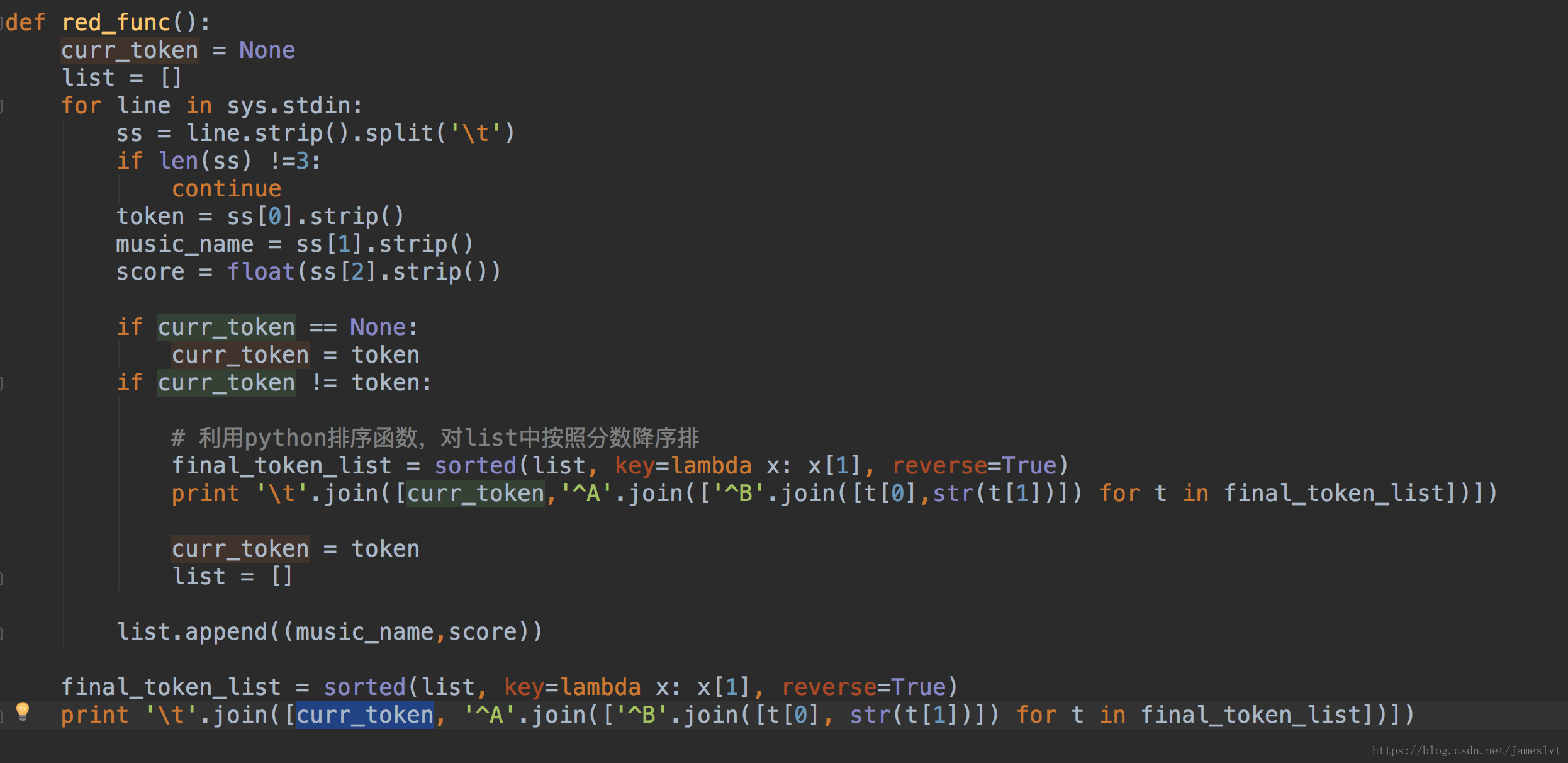
reduce输出结果:

到这里倒排索引已经基本实现完成,但是在真实的场景中,我们需要这个有什么作用呢?从场景图中可以看到是做推荐,或是搜索引擎使用,这就要求我们把上面的数据存放在Nosql数据库,但是数据库一般存放汉字都会多多少少出现一些问题,我们可以通过id的方式进行转换,就可以完美解决该类问题,下面就来看下怎么实现搜索引擎或者说是怎么实现转换
-
首先生成每个截取好的token对应的id,将原始的文件进行切分并且生成id,我们来下结果

token对应转换成的id
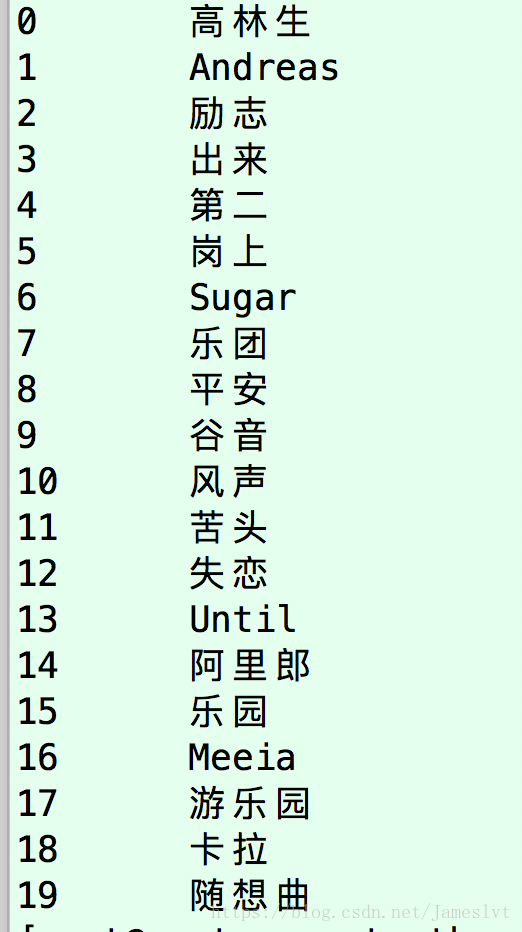
-
转换好以后,接下来我们需要把第一次redce输出的结果进行转换,把token换成id,musicName换成musicId
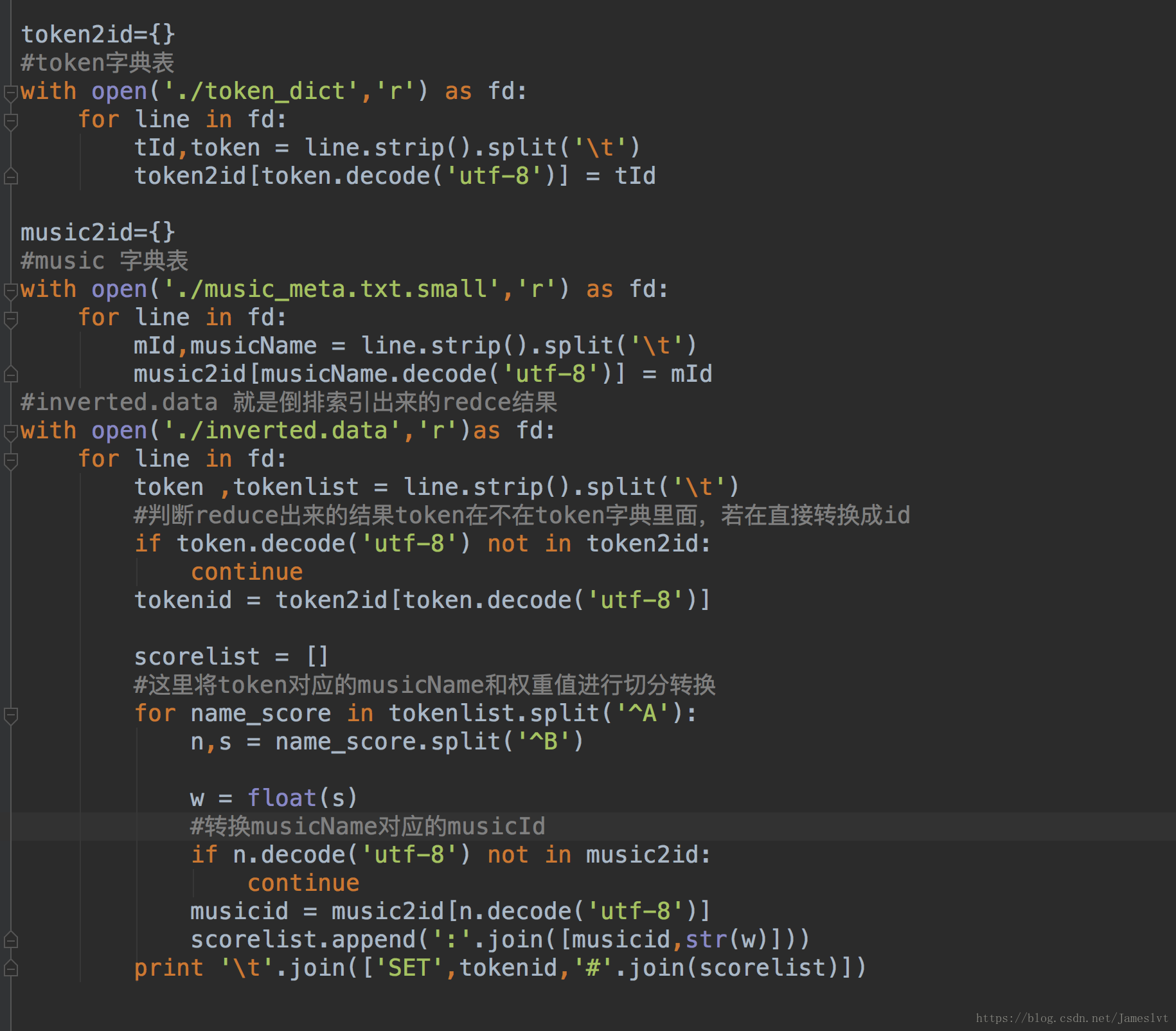
-
转换好以后,我们进行数据插入,在上一次输出结果后,我们输出来一个SET 这个是往redis数据插入数据的语句,最后我们看下怎么从数据库查询出来并且转换成汉字的过程,下面的代码注释很详细可以看一下。
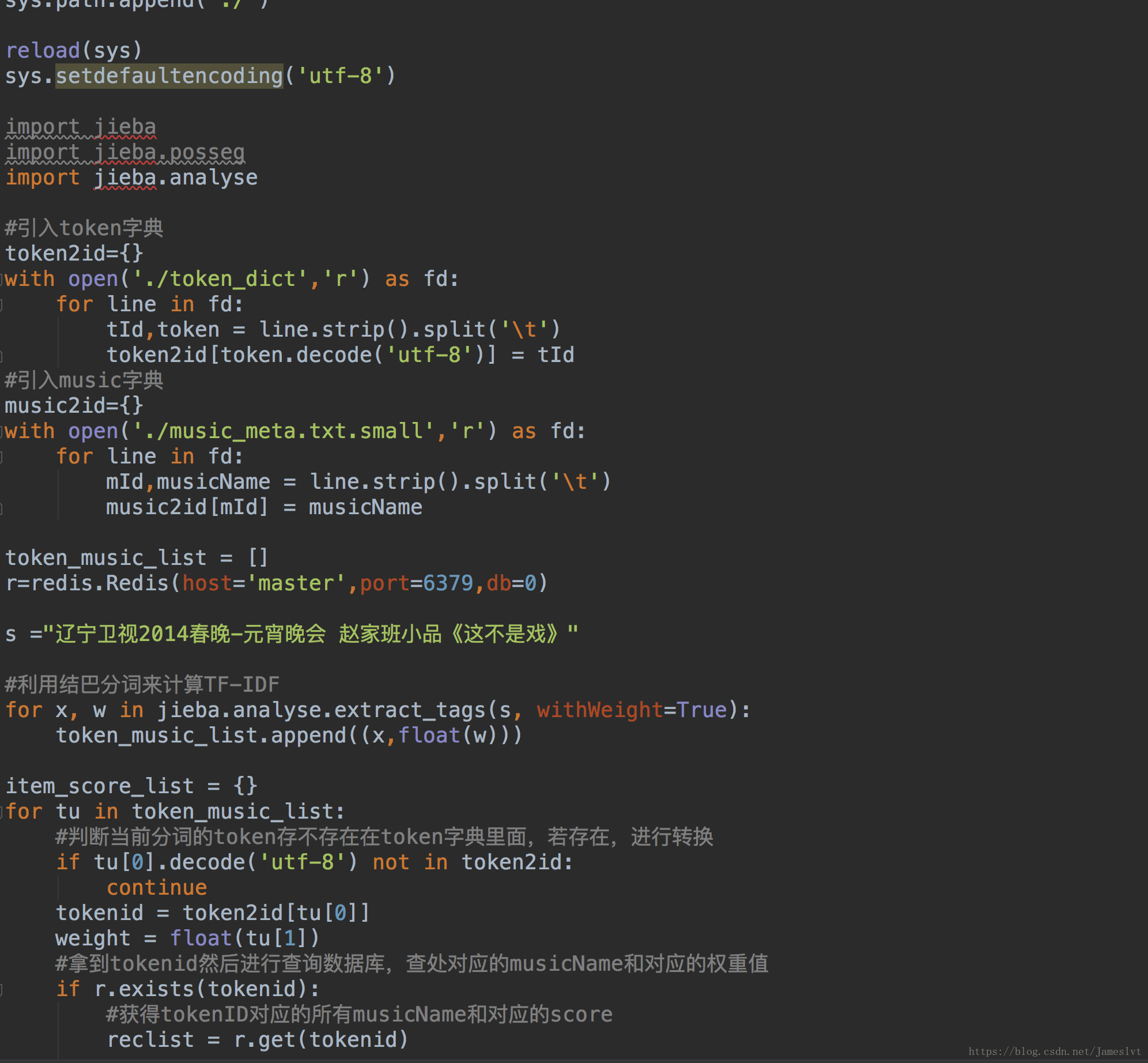
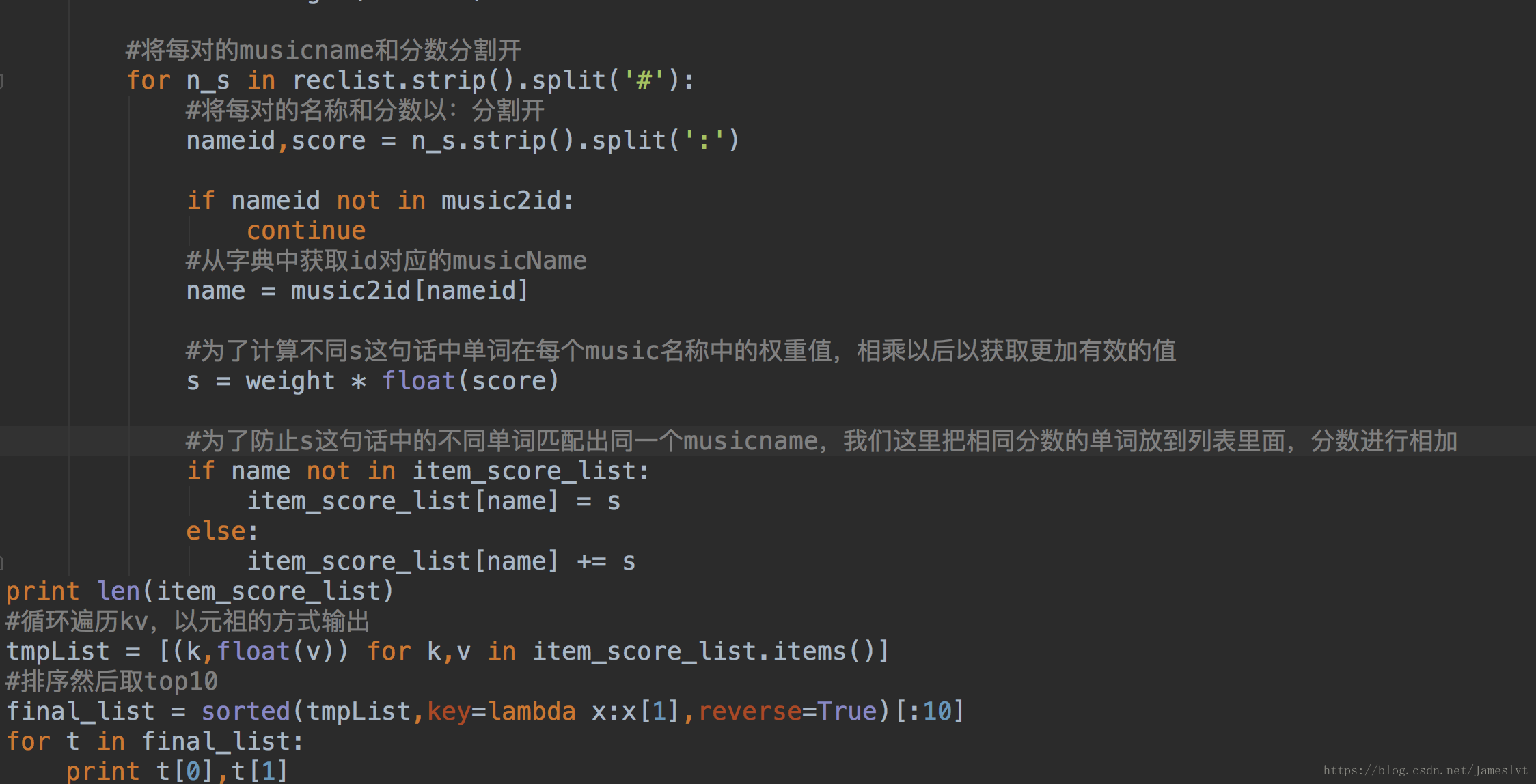
上述就是所有的代码实现过程,那么我们来看下页面最后的结果,搜索引擎的实现,这里简单的做个推荐或是查询

至此我们就讲完推荐之CB算法的实现。那么接下来我们来讲解CF算法的实现。
CF算法的实现
CF算法实现有两种方式:
-
倒排方式
-
分块的方式
这里我们先介绍一下第一中方式的实现,也就是倒排的方式,在讲解之前,我们需要先看一下CF中代码方式实现过程中需要用的公式,上次在理论的部分我们用电影说过一个计算公式,这个仅仅是理论部分,那么在实践部分,我们怎么来实现相似度的计算呢,当然上次输的那个公式也适用,这里我们用cos相似度计算公式:

我们来解释一下这个公式:不要看这个公式复杂,接下来我们来拆解一下,首先我们先把左边的遮住

右边这部分相当于一个用户对i和j有评分用户的集合,我们可以把他看成一个数字,-1后也是一个数字,分母+lamda是为了防止分母为0
我们近似可以把上下看成一个相同的常量,给约去,这个对于我们求相似度没有任何帮助,接下来我们来看下主要的公式:

这个公式上面是R(ui)*R(uj)什么是Rui,就是用户对item i的打分,对j的打分,分母是进行模的计算,然后结合分子我们拆开成左右看,是不是就是求单位向量,对于某一个用户来说,分母是不是固定值,不管对哪个item,但是分母是不是一样,那么我们能不能把分母直接用分子除了以后再相乘,这种是不是在我们写代码的时候就方便多了,至于
张三买个:A :0.5 B:0.3
李四买个:A :0.2 B:0.3
王五买个:A :0.3 B:0.4
那么我们怎么求AB的相似度,即0.5*0.3+0.2*0.3+0.3*0.4 这个就是AB的相似度,那么上面那个公式是不是我们求的cos公式,
CF-倒排实现
我们知道代码计算部分使用的相似度是如何计算的,那么我们来看下怎么做:
-
MapReduce实现的过程
-
在map阶段将每个用户评分组合成pair,以item1,item2,item1score,item2score 形式输出,以item1+item2作为排序
-
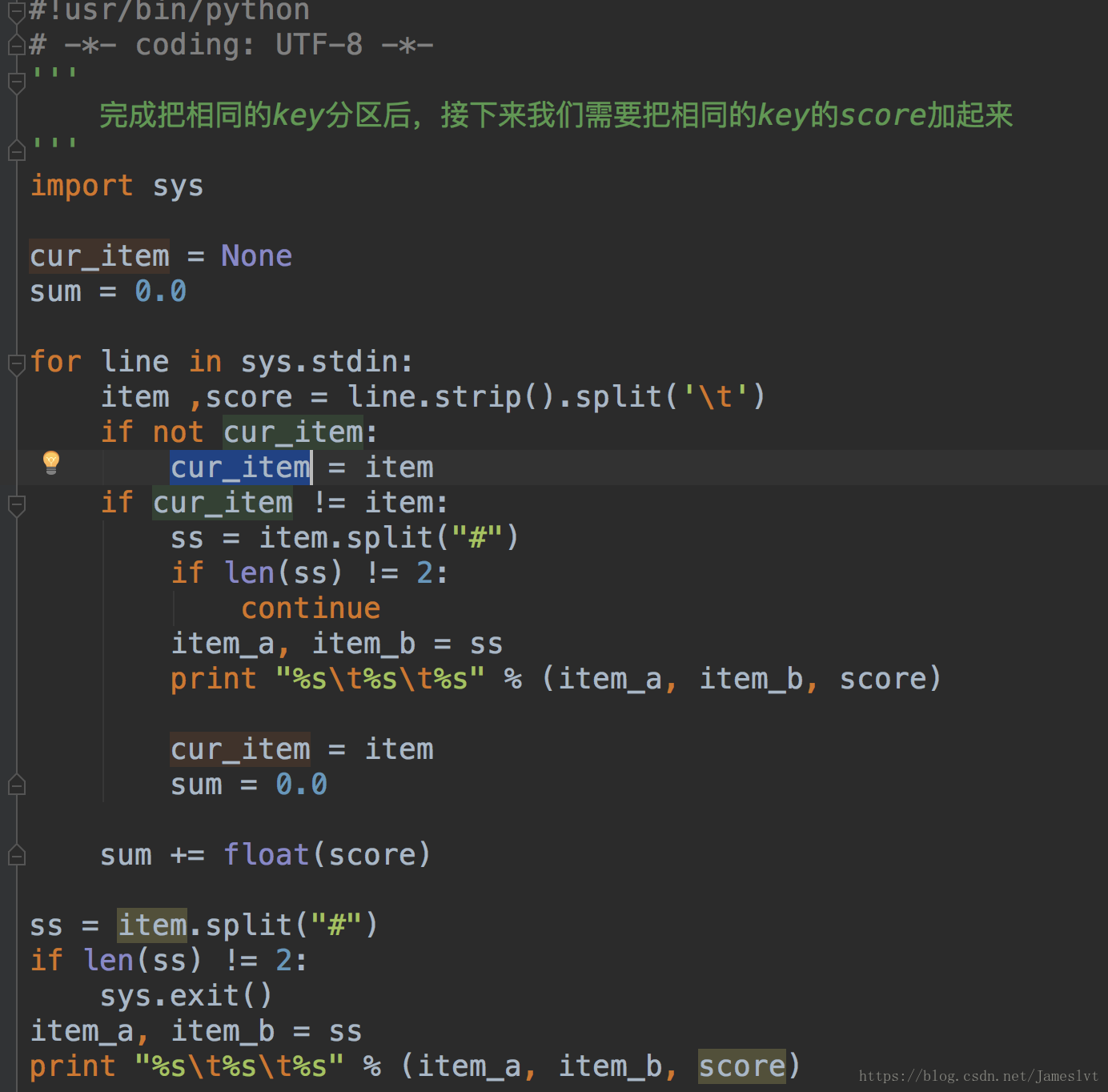
在reduce阶段将相同的item1+item2分数进行相加
代码实现:
-
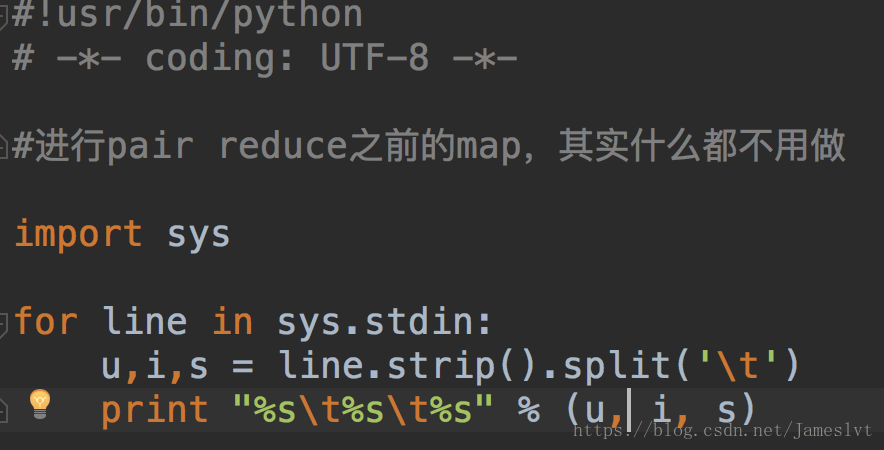
进行归一化
-
两两取pair
-
相同的pair进行求和
归一化阶段:
map

reduce
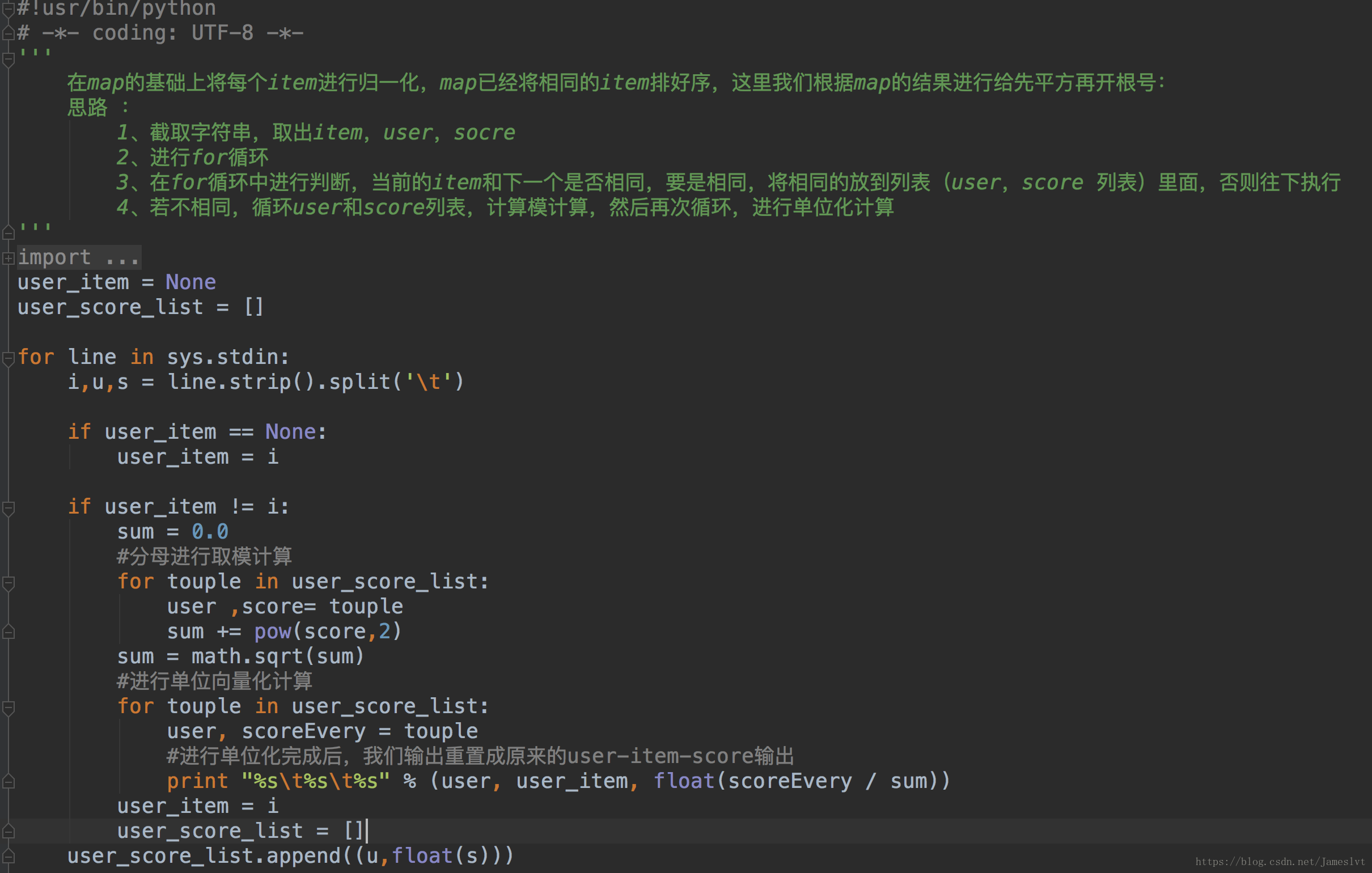
两两取pair:
map阶段:
reduce阶段:

求和阶段:
map:

reduce:
以上就是CF算法中倒排方式的实现,但是倒排式有个很明显的缺点,在中间过程进行pair对的时候,数据会膨胀的很厉害,不进行人工干预,很容易造成OOM(out of memory)的风险,内存爆掉,假如没有问题,也会非常慢。
CF-分块式实现
一般我们不使用分块式,经常使用倒排式,这里我们说一下原理
一个UI矩阵乘以UI转置等于UU矩阵,主要思想就是,把UI矩阵切分成很多行,并且在不同的节点上执行,但是转置矩阵必须在每个节点是包含所有的UI的转置信息,最后得到各个小块的UU再合并。

但是这种分块式有个大的缺点就是转置矩阵,在每台节点上的内存中存储,这个必然会造成内存不够用,操作性很差,所以一般我们不使用分块式。














 4143
4143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









