







一、什么是Xpath?
XPath(XML Path Language)是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
由于HTML文档本身就是一个标准的XML页面,因此我们可以使用XPath的语法来定位页面元素。
二、可以使用的工具?
下面这些浏览器插件可以快速获取或验证元素的xpath或css
- chrome插件:ChroPath、SelectorGadget、Xpath Helper【获取、验证】;
- google浏览器开发者模式——>Console标签【验证】
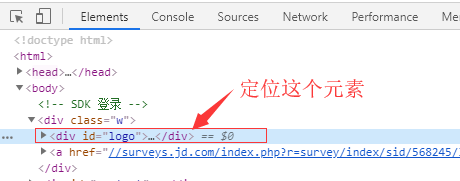
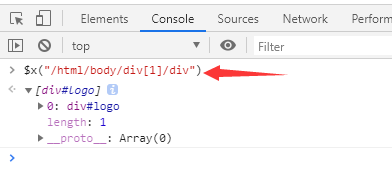
2.1 在chrome-console中定位
基本格式:$x("xpath表达式")
- 绝对定位:
$x("/xpath表达式") - 相对定位:
$x("//xpath表达式")
三、Xpath节点
节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
节点关系
父(Parent):每个元素以及属性都有一个父。
子(Children):元素节点可有零个、一个或多个子。
同胞(Sibling):拥有相同的父的节点。
先辈(Ancestor):某节点的父、父的父,等等。
后代(Descendant):某个节点的子,子的子,等等。
四、Xpath用法
1.选取节点
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 绝对路径,从根节点选取。 |
| // | 相对路径,从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
例如:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /html/form/input | 查找/html/form下的所有input元素 |
| //* | 定位所有元素,其中 通配符*表示未知的元素 |
| //form/* | 查找form节点下的所有元素 |
| //*/input | 查找所有input元素 |
| //input | 查找所有input元素 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
2.属性定位
格式:[@属性=‘属性名’]
//*[@属性名称='属性值'] #@ 代表以属性定位,后面可以接标签中任意属性
//*[@id='username'] #通过ID定位
//*[@class='logo'] #通过Class定位
//*[@name='user'] #通过Name定位
3.标签定位
当标签的属性重复时,Xpath提供了通过标签来进行过滤。
格式://要定位的标签
将 * 换位任意标签名,则可根据标签进行筛选
//input[@placeholder='用户名'] # 根据input标签筛选,然后再根据属性'placeholder'进行筛选
4.层级过滤
当标签页重复时,Xpath提供了层级过滤。
建议:能用属性定位解决的,尽量少用层级过滤。
原因:一般html页面做好后,除非大改版否则很少会改属性,一般情况会去调整html层级关系。
//form/div/input[@placeholder="用户名"] # 支持通过 / 进行层级递进,找到符合层级关系的标签
//form/div[@class='login-user']/input # 当层级都重复时,可以通过单个层级的属性进行定位
5.索引过滤
一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。可以通过索引过滤解决。
//select[@name='city'][1]/option[1] # 通过索引,在List中定位属性,与python的索引有些差别,Xpath从1开始
6.逻辑运算
上面几种如果都用上了之后还重复的话,我们就可以使用Xpath提供的终极神器,逻辑运算定位。and 或 or
//select[@name='city' and @size='4' and @multiple="multiple"] #通过and来缩小过滤的范围,只有条件都符合时才能定位到
//select[@name='city' or @size='4'] # or就相反了,只要这些筛选中,其中一个出现那么久匹配到了
我们做UI自动化,是为了定位到唯一的元素,所以一般不用or
7.谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
/bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
8. 选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
9. XPath 轴
轴可定义相对于当前节点的节点集。
语法:轴名称::标签名
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
10.位置路径表达式
位置路径可以是绝对的,也可以是相对的。
绝对路径起始于正斜杠( / ),而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:
绝对位置路径:/step/step/…
相对位置路径:step/step/…
每个步均根据当前节点集之中的节点来进行计算。
步的语法:
轴名称::节点测试[谓语]
步(step)包括:
- 轴(axis):定义所选节点与当前节点之间的树关系
- 节点测试(node-test):识别某个轴内部的节点
- 零个或者更多谓语(predicate):更深入地提炼所选的节点集
| 例子 | 结果 |
|---|---|
| child::book | 选取所有属于当前节点的子元素的 book 节点。 |
| attribute::lang | 选取当前节点的 lang 属性。 |
child::* | 选取当前节点的所有子元素。 |
attribute::* | 选取当前节点的所有属性。 |
| child::text() | 选取当前节点的所有文本子节点。 |
| child::node() | 选取当前节点的所有子节点。 |
| descendant::book | 选取当前节点的所有 book 后代。 |
| ancestor::book | 选择当前节点的所有 book 先辈。 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
child::*/child::price | 选取当前节点的所有 price 孙节点。 |
11.XPath 运算符
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
12.常用函数
- 字符串查找函数: contains()
语法:contains(string1,string2),表示如果 string1 包含 string2,则返回 true,否则返回 false。 - 获取元素的文本内容: text()
- 从起始位置匹配字符串:starts-with ()
//a[contains(@href, 'baidu.com')] # 定位href属性中包含'baidu.com'的所有a元素
//a[text()='你好'] # 链接文本等于“你好”的所有a元素(精确匹配)
//a[starts-with(@href, '/ads')] # 链接href属性是以/ads开头的所有a元素
//a[contains(text(), '你好')] # 链接文本包含“你好”的所有a元素(模糊匹配)
更多函数请参考:http://www.w3school.com.cn/xpath/xpath_functions.asp
参考:
http://www.w3school.com.cn/xpath/index.asp
https://www.jianshu.com/p/820dcd013993















 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









