







排序算法是在算法学习中最基本的,也是平时最常用的。这里贴出我总结出来的常用算法。
先写一个基础抽象类,所有排序类都继承自该类,sort方法就是具体排序算法的实现:
public abstract class BaseSorter<E extends Comparable<E>> {
public abstract void sort(E[] array);
protected final void swap(E[] array, int from, int to) {
E temp = array[from];
array[from] = array[to];
array[to] = temp;
}
}1、插入排序
插入排序,对于较小的数组时,该方法十分的高效。
最差时间复杂度O(n2),最优时间复杂度O(n),平均时间复杂度O(n2),最差空间复杂度O(n),辅助空间O(1)。
需要辅助空间复杂度O(1)
public class InsertSorter<E extends Comparable<E>> extends BaseSorter<E> {
@Override
public void sort(E[] array) {
for (int i = 1; i < array.length; i++) {
E temp = array[i];
int j = i;
for (; j > 0 && array[j - 1].compareTo(temp) > 0; j--) {
array[j] = array[j - 1];
}
array[j] = temp;
}
// //下面这个代码方便不过交换次数增多,影响性能
// for (int i = 1; i < array.length; i++)
// for (int j = i; j > 0 && array[j - 1].compareTo(array[j]) > 0; j--)
// swap(array, j - 1, j);
}
}
下面是一个数组使用插入排序的过程示例,通过这个能很清楚数组整个过程的排序步骤:

2、冒泡排序
冒泡排序的算法思想很简单,同时效率低。冒泡排序与插入排序拥有相等的执行时间,但两种方法需要交换的次数却很大的不同。
冒泡排序的时间复杂度空间复杂度和插入排序一样。
在最坏的情况冒泡需要O(n2)次交换,而插入只需要O(n)次交换。因此很多地方避免使用冒泡而使用插入替代。
public class BubbleSorter<E extends Comparable<E>> extends BaseSorter<E> {
@Override
public void sort(E[] array) {
for (int i = array.length - 1; i > 0; i--)
for (int j = 0; j < i; j++) {
if (array[j].compareTo(array[j + 1]) > 0)
swap(array, j, j + 1);
}
}
}

3、选择排序
选择排序,先在未排列序列中找到最小(大)元素,存放到排列序列起始位置,然后从剩余未排列序列中继续找到最小(大)元素存放到排列序列末尾。以此类推,直到全部排列完成。
对于n个元素的表进行排序总共最多进行n-1次交换。
最差时间复杂度O(n2),最优时间复杂度O(n2),平均时间复杂度O(n2),最差空间复杂度O(n),辅助空间O(1)
public class SelectSorter<E extends Comparable<E>> extends BaseSorter<E> {
@Override
public void sort(E[] array) {
for (int i = 0; i < array.length; i++) {
int min = i;
for (int j = i+1; j<array.length; j++) {
if(array[j].compareTo(array[min]) < 0) { min = j; }
}
// 查找最小的
if(min != i) swap(array, min, i);
}
}
}

4、希尔排序
希尔排序是插入排序的一种高速而稳定的改进版。由于插入排序的特点:对几乎已经排好序的序列操作时非常高效。因此提出把数据分为若个小块,分别使用插入排序,之后再合并继续插入排序,依次递归直到整个序列都变为有序。
步长的选择是希尔排序的重要部分,先以一定步长排序,再以更小的步长进行排序,最终以步长为1进行排序。下面的代码是使用步长取半的方法,但并不是最好的取步长的方法。
时间复杂度根据取步长的方法而不同,
public class ShellSorter<E extends Comparable<E>> extends BaseSorter<E> {
@Override
public void sort(E[] array) {
int value = 1;
while ((value + 1) * 2 < array.length)
value = (value + 1) * 2 - 1;
for (int n = value; n >= 1; n = (n + 1) / 2 - 1)
shellSort(array, n);
}
private void shellSort(E[] array, int n) {
for (int i = n; i < array.length; i+=n) {
E tmp = array[i];
int j = i;
for (; j > 0 && array[j - n].compareTo(tmp) > 0; j -= n)
array[j] = array[j - n];
array[j] = tmp;
}
}
}
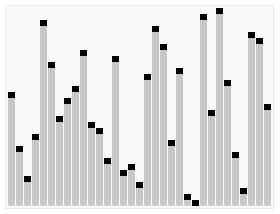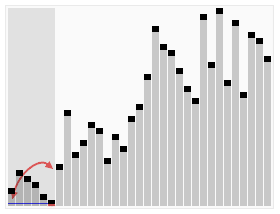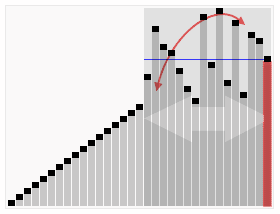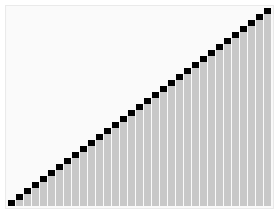
5、快速排序
对于数据比较多的使用快速排序效率是很高的,快排也是目前使用中会用到最多的一种排序算法。快速排序是不稳定的,最差的时候时间度最长,递归的层数就是最大(最差时间复杂度O(n2),这种情况不多)。Java中递归过多层次,有可能会引起栈溢出!
最差时间复杂度O(n2),最优时间复杂度O(n log n),平均时间复杂度O(n log n)
public class QuickSorter<E extends Comparable<E>> extends BaseSorter<E> {
@Override
public void sort(E[] array) {
quickSort(array, 0, array.length - 1);
}
private void quickSort(E[] array, int low, int high) {
if (high - low < 1)
return;
int i = low;
int j = high;
E temp = array[low];
while (i != j) {
// 找到右边数第一个小于枢纽元素的元素
while (i < j && array[j].compareTo(temp) > 0)
j--;
if (i < j) {
array[i] = array[j]; i++;
}
// 找到左边数起第一个大于枢纽元素的元素
while (i < j && array[i].compareTo(temp) <= 0)
i++;
if (i < j) {
array[j] = array[i]; j--;
}
}
// 枢纽元素移到正确位置
array[i] = temp;
quickSort(array, low, i- 1);
quickSort(array, i+ 1, high);
}
}
6、归并排序
归并排序,将两个已经排好序的序列合并成一个序列的操作。
最差时间复杂度O(nlogn),最优时间复杂度O(n),平均时间复杂度O(nlogn),最差空间复杂度O(n)
public class MergeSorter<E extends Comparable<E>> extends BaseSorter<E> {
@Override
@SuppressWarnings("unchecked")
public void sort(E[] array) {
Object[] tmp = new Comparable[array.length];
mergeSort(array, 0, array.length - 1, (E[]) tmp);
}
private void mergeSort(E[] array, int left, int right, E[] tmp) {
if (left < right) {
int mid = (left + right) / 2;
mergeSort(array, left, mid, tmp);
mergeSort(array, mid + 1, right, tmp);
merge(array, tmp, left, mid + 1, right);
}
}
private void merge(E[] array, E[] tmp, int lPos, int rPos, int rEnd) {
int lEnd = rPos - 1;
int tPos = lPos; //tmp position
int lPosInit = lPos;
while (lPos <= lEnd && rPos <= rEnd) {
if (array[lPos].compareTo(array[rPos]) <= 0)
tmp[tPos++] = array[lPos++];
else
tmp[tPos++] = array[rPos++];
}
while (lPos <= lEnd)
tmp[tPos++] = array[lPos++];
while (rPos <= rEnd)
tmp[tPos++] = array[rPos++];
// 将排好序的临时数组中放回源数组
for (; rEnd >= lPosInit; rEnd--)
array[rEnd] = tmp[rEnd];
}
}

7、堆排序
堆排序时利用堆这种近似完全二叉树的数据结果来实现的。
堆结构的特点: 在起始数组为0时: * 父节点i的左子节点位置(2*i+1) * 父节点i的右子节点位置(2*i+2) * 子节点i的父节点位置((i-1)/2)
public class HeapSorter<E extends Comparable<E>> extends BaseSorter<E> {
@Override
public void sort(E[] array) {
buildMaxHeapify(array); heapSort(array);
}
/** * 从最后一个父节点开始依次构建最大堆 */
private void buildMaxHeapify(E[] data) {
int startIndex = getParentIndex(data.length - 1);
for (int i = startIndex; i >= 0; i--)
maxHeapify(data, data.length, i);
}
/**
* 创建最大堆
* @param data 原数组
* @param heapSize 需要创建的最大堆的大小
* @param index 当前需要创建最大堆的位置
*/
private void maxHeapify(E[] data, int heapSize, int index) {
// 当前点于左右子节点比较
int left = getChildLeftIndex(index);
int right = getChildRightIndex(index);
int largest = index;
if (left < heapSize && data[left].compareTo(data[index]) > 0)
largest = left;
if (right < heapSize && data[right].compareTo(data[largest]) > 0)
largest = right;
// 发现原来的data[index]不是最大值
if (largest != index) {
E temp = data[index];
data[index] = data[largest];
data[largest] = temp;
maxHeapify(data, heapSize, largest);
}
}
/** * 排序,最大值放在末尾,数组data虽然原来是最大堆,排序之后就变成递增的了 */
private void heapSort(E[] data) {
for (int i = data.length - 1; i > 0; i--) {
E temp = data[0];
//最大值
data[0] = data[i];
data[i] = temp;
maxHeapify(data, i, 0);
}
}
/** * 父节点位置 */
private int getParentIndex(int current) {
return (current - 1) >> 1;
}
/** * 左子节点位置 */
private int getChildLeftIndex(int current) {
return (current << 1) + 1;
}
/** * 右子节点位置 */
private int getChildRightIndex(int current) {
return (current << 1) + 2;
}
}过程效果图:
















 2868
2868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









