







1 数仓基础
1.1 概念
数据仓库(Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持。
仓库解读:
- 不“生产”任何数据,其数据来源于不同外部系统
- 同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用
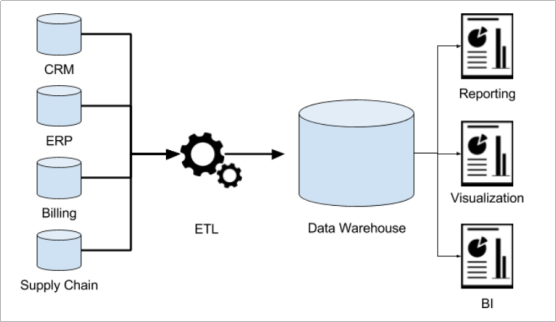
1.2 数仓需求引出
信息用于两处:操作型记录的保存+分析型决策的制定
-
操作型记录的保存:
1)公司下辖多条业务线,各业务线的业务正常运营需要记录维护多种不同信息.引出联机事务处理系统(OLTP)
2)OLTP的主要任务是执行联机事务和查询处理,基本特征是前台接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果
3)关系型数据库是OLTP典型应用,比如:Oracle、Mysql、SQL Server等
-
分析型决策的制定
1)针对业务数据的增多和运营的许多问题的产生,制定相关的解决措施,瞎拍桌子是肯定不行的。
2)最稳妥办法就是:基于业务数据开展数据分析,基于分析的结果给决策提供支撑。也就是所谓的数据驱动决策的制定
3)问题:数据分析,数据库可以吗
答案:可以,但没必要.
具体为什么不在OLTP开展分析?
- OLTP核心是面向业务,支持业务,支持事务,业务主要为读和写,读的压力明显大于写的压力
- 数据分析对海量的数据读取,服务器压力大
- OLTP数据存储时间受限
- 数据的不同表的字段类型属性不统一
因此:
- OLTP仅适用于数据规模小的业务低谷期,为解决以上问题,数仓雏形出现
- 这种数据分析平台具有面向分析,支持分析的特点,并且和OLTP系统解耦合
- 数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境,公司就可以基于分析决策需求。我们把这种面向分析、支持分析的系统称之为OLAP(联机分析处理)系统。数据仓库是OLAP一种。
1.3 主要特征
数据仓库是面向主题性(Subject-Oriented )、集成性(Integrated)、非易失性(Non-Volatile)和时变性(Time-Variant )数据集合,用以支持管理决策 。
-
面向主题性
主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。
-
集成性
主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构–>数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总
-
非易失性
数据仓库是分析数据的平台,而不是创造数据的平台,通过数仓去分析数据中的规律,而不是去创造修改其中的规律
-
时变性
数据仓库的数据需要随着时间更新,以适应决策的需要
1.4 多角度对比
1 ) 联机事务处理OLTP(On-Line Transaction Processing)对比 联机分析处理OLAP(On-Line Analytical Processing)
| OLTP | OLAP | |
|---|---|---|
| 数据源 | 仅包含当前运行日常业务数据 | 整合来自多个来源的数据,包括OLTP和外部来源 |
| 目的 | 面向应用,面向业务,支撑事务 | 面向主题,面向分析,支撑分析决策 |
| 焦点 | 当下 | 主要面向过去、面向历史 实时数仓 |
| 任务 | 读写操作 | 大量读而很少写操作 |
| 响应时间 | 毫秒 | 秒、分钟、小时或者天取决于数据量和查询复杂性 |
| 数据量 | 小数据,MB,GB | 大数据,TP,PB |
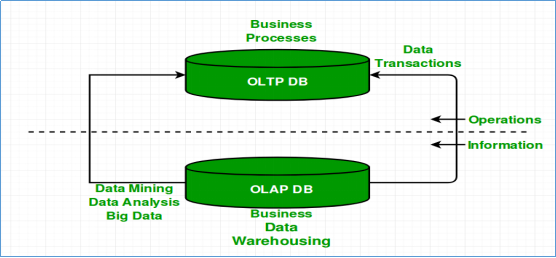
2 ) 数据库和数据仓库,二者基本毫无关系
| 数据库 | 数据仓库 | |
|---|---|---|
| 别名 | RDBMS | DW |
| 典型代表 | Mysql | Hive |
| 处理系统 | OLTP | OLAP |
| 主要特征 | 面向业务 | 面向主题 |
| 存储数据 | 业务数据 | 历史数据 |
| 目的 | 捕获数据 | 分析数据 |
说明:数仓不是大型的数据库,尽管数仓的存储规模大,另外数仓也并不是要取代数据库
补充:
数据集市作为数仓的子集,由面向多主题改为面向指定主题,从而开展各种应用
1.5 数仓分层架构
按照数据流入流出数仓的过程,数仓最基本分为三个层:操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA).
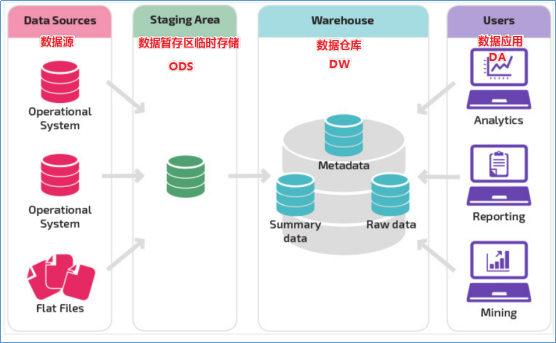
为什么分层?
- 清晰数据结构
- 数据血缘追踪
- 减少重复开发
- 复杂问题简单化
- 屏蔽原始数据的异常
2 Apache Hive入门
2.1 概述
Apache Hive是一款由Facebook实现并开源建立在Hadoop之上的数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
核心功能职责是将HQL解析编译为MapReduce程序,然后将程序提交到Hadoop集群执行.
映射:文件和表之间的对应关系(指元数据)
Hive特殊在于其数仓的两种能力(存储数据的能力 , 分析数据的能力)都是借助Hadoop的HDFS,MapReduce实现
2.2 优缺点
优点:
- 使用类SQL语法,避免写Map Reduce程序,学习成本低
- 适合海量数据的分析与计算
- 支持用户自定义函数
缺点:
-
Hive自动生成的MapReduce作业,通常不够智能化
具体表现为:生成的mr过多,加上mr的缺点:不擅长DAG计算(每步都需要落盘),后期使用 spark替换mr
-
不擅长数据挖掘,无法实现效率更高的算法
-
hive的执行延迟比较高
-
=粒度较粗,调优困难
-
不支持实时查询和行级别更新
原因:hive分析的数据存储在hdfs上,不支持随机写,只支持追加写,所以不能update和delete,只能select和insert
总结:由于hive运行于Hadoop之上,其缺点基本受限于hadoop
2.3 hive功能实现
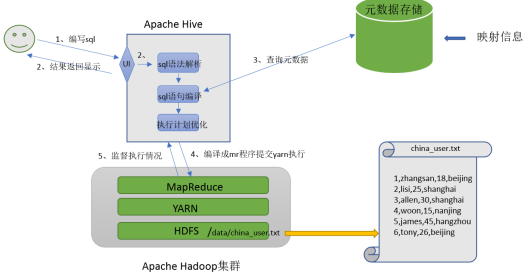
- 用户编写sql
- Hive对SQL语法解析,检查语法错误
- 通过查询元数据编译SQL语句看是否能执行,并优化
- 将SQL编译成mr程序提交yarn执行
- 监督执行情况
- 最终将sql的执行结果封装返回显示给用户
2.4 hive架构.组件
hive架构图
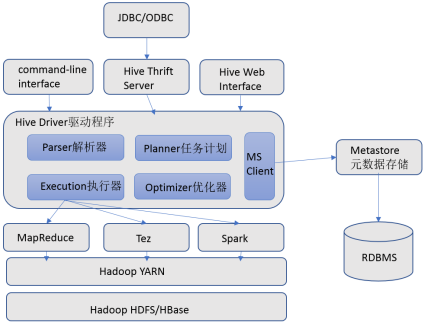
hive组件:
用户接口,元数据管理,Driver驱动程序,执行引擎
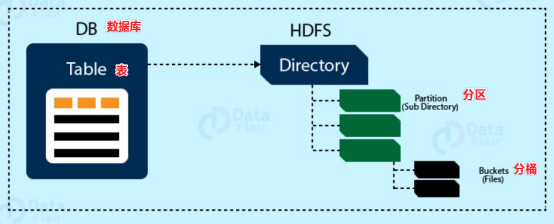
2.5 hive数据模型
2.6 Hive对比Mysql
Hive不是大型数据库,也不是要取代Mysql承担业务数据处理
| Apache Hive | Mysql | |
|---|---|---|
| 定位 | 数据仓库 | 数据库 |
| 使用场景 | 离线数据分析 | 业务数据事务处理 |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Local FS |
| 执行引擎 | MR,Tez,Spark | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 常见操作 | 导入数据,查询 | 增删改查 |
3 Hive安装部署
3.1 安装流程
-
修改Hadoop相关配置
修改core-site.xml配置文件:
1)hadoop.proxyuser.用户名.hosts(该用户允许通过代理访问的主机节点)
2)hadoop.proxyuser.用户名.groups(该用户允许通过代理用户所属组)
3)hadoop.proxyuser.用户名.users(该用户允许通过代理的用户)
修改yarn-site.xml配置文件:
1)yarn.nodemanager.resource.memory-mb(NM使用内存)
2)yarn.scheduler.minimum-allocation-mb(容器最小内存)
3)yarn.scheduler.maximum-allocation-mb(容器最大内存)
4)yarn.nodemanager.vmem-check-enabled(虚拟内存检查:关闭)
-
起集群
-
将hive包解压缩后改名为hive,将其bin目录添加到环境变量
-
将hive/lib/lib/log4j-slf4j-impl-2.10.0.jar改为bak后缀,解决日志jar包冲突
-
这时如果使用命令schematool -dbType derby -initSchema初始化元数据库,则hive目录下会生成derby.log日志文件和元数据存储目录metastore_db,此时hive将数据存储在hdfs上,元数据存储在hive自带的Derby元数据库
但是:
hive默认使用的元数据库derby,不支持多客户端共享元数据,即不支持多客户端并发访问(悲观锁:同时只允许一个客户端操作)
因此,我们需要将Hive的元数据地址改为MySQL
-
将derby.log和metastore_db删除,顺便将hdfs上目录删除,开始将元数据存储位置修改为MySql
-
安装并登录MySql
-
将Hive元数据配置到MySql:
1)将MySQL的JDBC驱动拷贝到Hive的lib目录下
2)hive/conf/下新建hive-site.xml文件
3)登录MySQL,在其中新建Hive元数据库
4)初始化Hive元数据库
总结:从安装流程可以看出,hive将元数据存放mysql中,数据存放在HDFS中,自己啥也不存,将sql语句转为对应的mr执行
3.2 元数据服务
引出:
截止到完成以上流程,hive 访问mysql方式为直接连接,没使用服务,当多hive客户端并发访问(mysql没有乐观锁),并发太高,服务器压力过大,为此进行优化,添加元数据服务,使用桥接的中转方式,负责将请求转发给mysql,(该方式只暴露该服务的地址,保护了hive元数据的安全)
步骤:
- 在hive-site.xml文件中添加hive.metastore.uris的值为thrift://hadoop102:9083
- 启动hive --service metastore(这种启动方式会占用前台界面)
- 启动hive
3.3 jdbc服务
-
hive-site.xml中添加如下配置
1)hive.server2.thrift.bind.host(指定hiveserver2连接的host)
2)hive.server2.thrift.port(指定hiveserver2连接的端口号)
3)hive.server2.active.passive.ha.enable(hiveserver2的高可用参数)
-
使用jdbc方式访问hive,该服务也是前台进程:hive --service hiveservice2
-
启动beeline客户端:beeline -u jdbc:hive2://hadoop102:10000 -n 用户名
3.4 hive服务启动脚本
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
3.5 参数配置方式
-
配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
用户自定义配置会覆盖默认配置,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
-
命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
仅对本次hive启动有效
-
参数声明方式
可以在HQL中使用SET关键字设定参数
仅对本次hive启动有效
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。















 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









