







表设计优化
1 普通表
1.1 Hive查询基本原理
-
创建数据库(chapter_6)
-
创建表(tb_login),hdfs上自动在数仓的数据库目录下创建表目录

-
关联数据:使用load命令将数据加载到表中,数据会被自动放入hdfs中对应表目录下
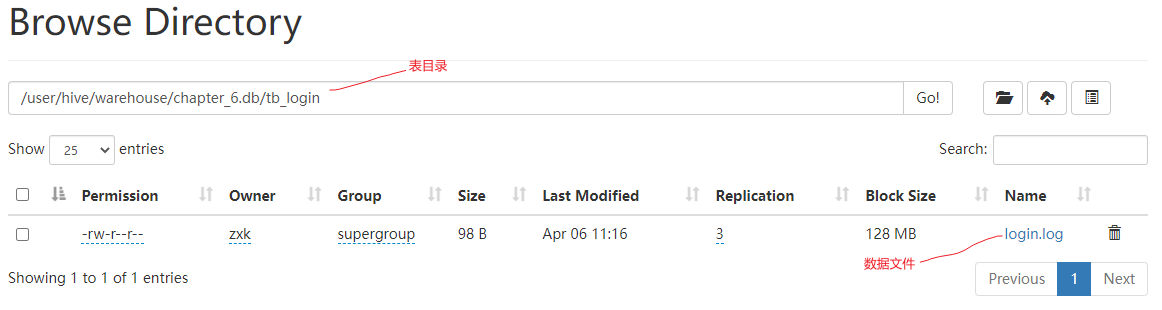
-
当执行查询计划时,Hive使用表的最后一级目录作为底层处理数据的输入
在元数据库metastore中表现为:
1)在TBLS表中根据表明查得SD_ID
2)SDS元数据表中的记录查询SD_ID对应的HDFS的表目录位置,即底层处理数据的输入
-
使用explain+query命令查看执行计划依赖的数据
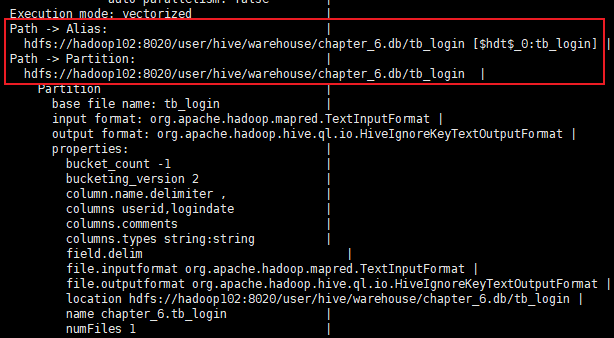
1.2 结构问题
- 大量不必要的数据被程序加载,在程序中被过滤,导致大量不必要的计算资源的浪费
- 大量的磁盘和网络的IO的损耗。
- 考虑到以上因素,使用分区裁剪思想
2 分区表
2.1 设计思想
- 将数据按照查询的条件【一般都以时间】进行划分分区存储,将不同分区的数据单独使用一个HDFS目录来进行存储
- 当底层实现计算时,根据查询的条件,只读取对应分区的数据作为输入,减少不必要的数据加载,提高程序的性能
2.2 查询基本原理
-
按登录日期(logindate)分区创建分区表(tb_login_part)
-
将登录数据写入分区表(insert+select),hdfs中自动在表目录下创建每个分区的目录
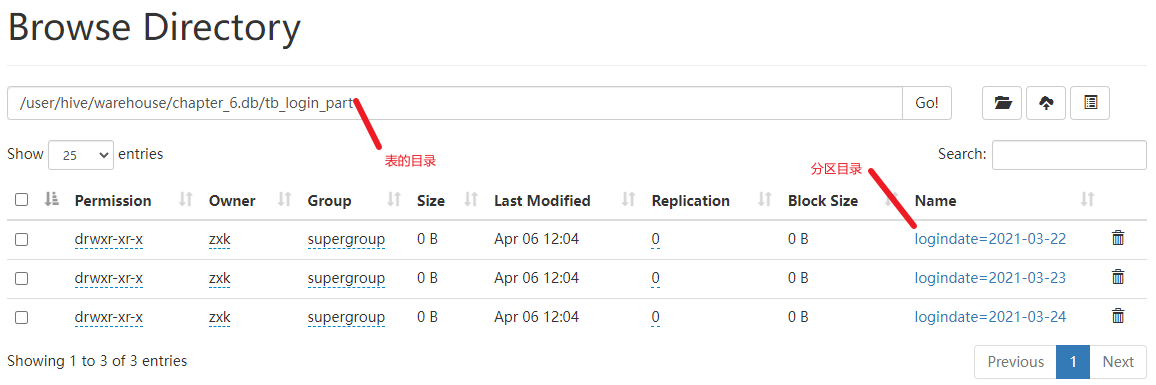
-
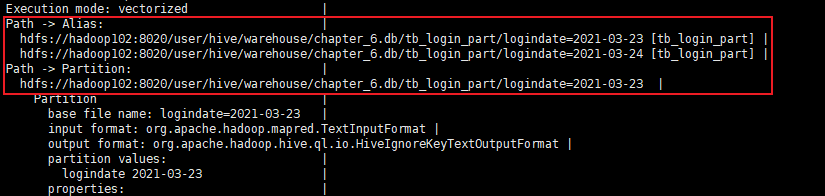
按分区字段(logindate)过滤查询
在元数据库中表现为:
1)元数据中记录该表为分区表并且查询过滤条件为分区字段,所以找到该分区对应的HDFS目录
2)加载对应分区的目录作为计算程序的输入
-
查看执行计划
3 分桶表
3.1 join的问题
如果有两张非常大的表要进行Join,两张表的数据量都很大,Hive底层通过MapReduce实现时,无法使用MapJoin提高Join的性能,只能走默认的ReduceJoin,而ReduceJoin必须经过Shuffle过程,相对性能比较差,而且容易产生数据倾斜
3.2 设计思想
-
分桶表是将数据划分不同的文件进行存储
-
底层是多个reducer将数据划分到不同分区(mr中的分区)生成多个文件
-
如果有两张表按照相同的划分规则【按照Join的关联字段】将各自的数据进行划分,在Join时,就可以实现Bucket与Bucket的Join,避免不必要的比较
-
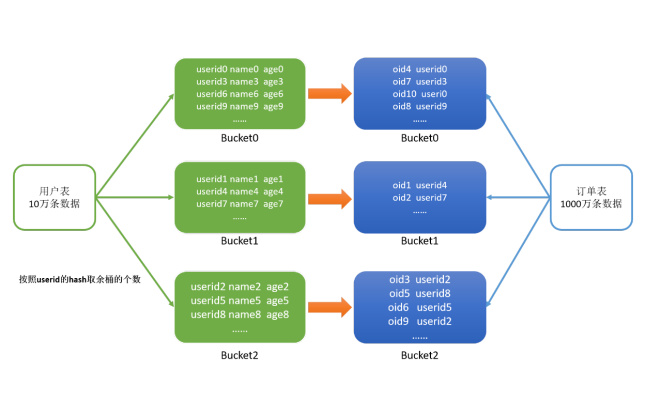
例如:
1)有两张表,订单表有1000万条,用户表有10万条,两张表的关联字段是userid,现在要实现两张表的Join。
2)订单表和用户表都按userid的hash取模来分桶
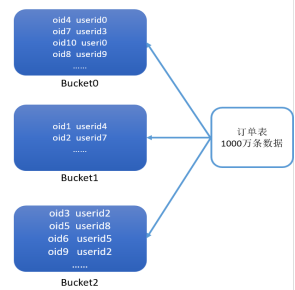
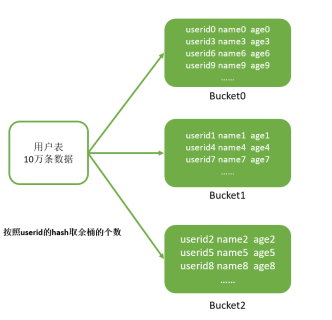
3)join时,只需要将两张表的Bucket0与Bucket0进行Join,Bucket1与Bucket1进行Join,Bucket2与Bucket2进行Join即可
4)不用让所有的数据挨个比较,降低了比较次数,提高了Join的性能
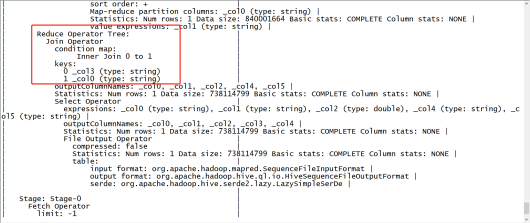
3.3 分桶表join
-
普通表join执行计划(inner join)
-
分桶的Join执行计划(开启分桶SMB join)
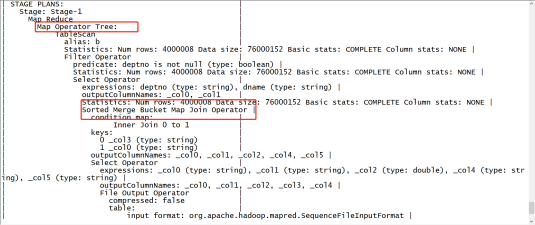
4 索引
- 索引功能支持是从Hive0.7版本开始,到Hive3.0不再支持
- 索引表不会自动更新,必须手动执行更新
- 整体性能较差,维护相对繁琐
- 实际工作场景中,一般不推荐使用Hive Index,推荐使用ORC文件格式中的索引或者物化视图来代替Hive Index提高查询性能















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









