







Spark概述
1.Spark or Hadoop?
Hadoop的MapReduce和Spark同为计算框架,使用时如何选择?
1)MR由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。Spark就是在传统的MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD。
2)Spark所基于的scala语言恰恰擅长函数的处理。
3)Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法.
4)Spark和Hadoop的根本差异是多个任务之间的数据通信问题 : Spark多个任务之间数据通信是基于内存,而Hadoop是基于磁盘。
5)Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式。
6)Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互
7)Spark的缓存机制比HDFS的缓存机制高效。
2.意味着Spark能完全替代MR?
Spark确实会比MapReduce更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择.
3.Spark核心模块

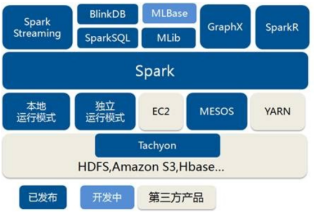
Spark运行环境
1.Local模式
1)启动Local环境:进入解压缩后的路径,执行如下命令bin/spark-shell --master local[4]
2)提交应用:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
1) --class 表示要执行程序的主类
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
2.Standalone模式
1)只使用Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式,Spark的Standalone模式体现了经典的master-slave模式。
2)提交应用:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
格式:
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]
3)参数说明:
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| –class | Spark程序中包含主函数的类 | |
| –master | Spark程序运行的模式 | 本地模式:local[*]、spark://linux1:7077、Yarn |
| –executor-memory 1G | 指定每个executor可用内存为1G | 符合集群内存配置即可,具体情况具体分析。 |
| –total-executor-cores 2 | 指定所有executor使用的cpu核数为2个 | |
| –executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用jar,包含依赖。这个URL在集群中全局可见。 比如hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的path都包含同样的jar | |
| application-arguments | 传给main()方法的参数 |
3.Yarn模式
1)不同于独立部署模式下由Spark自身提供计算资源,降低了和其他第三方资源框架的耦合性,Spark主要是计算框架,而不是资源调度框架,因此强大的Yarn环境下Spark的工作更强.
2)提交应用:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
4.Windows模式
1)启动本地环境:执行解压缩文件路径下bin目录中的spark-shell.cmd
2)命令行提交应用:
spark-submit
--class org.apache.spark.examples.SparkPi
--master local[2]
../examples/jars/spark-examples_2.11-2.4.5.jar
10
5.部署模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master及Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn及HDFS | Hadoop | 混合部署 |
Spark运行架构
1.运行架构
采用了标准 master-slave 的结构,Driver表示master,负责管理整个集群中的作业任务调度。图形中的Executor 则是 slave,负责实际执行任务。
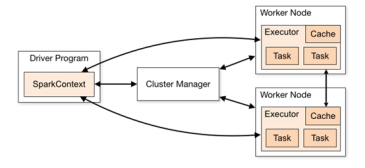
2.核心组件
1)Driver,驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。
Driver在Spark作业执行时主要负责:①将用户程序转化为作业(job)②在Executor之间调度任务(task) ③跟踪Executor的执行情况 ④通过UI展示查询运行情况
2)Executor,计算节点,一个JVM进程,作业中运行具体任务(Task),任务彼此之间相互独立。始终伴随着整个 Spark 应用的生命周期而存在。
Executor有两个核心功能:①负责运行组成Spark应用的任务,并将结果返回给驱动器进程 ②它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
3)Master&Worker,Spark集群的独立部署环境中的两个核心组件.
Master是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于Yarn环境中的RM, Worker也是进程,一个Worker运行在集群中的一台服务器上,由Master分配资源对数据进行并行的处理和计算,类似于Yarn环境中NM。
4)ApplicationMaster,yarn模式下用户向yarn集群提交应用时,用于向资源调度器申请执行任务的资源容器Container,运行用户自己的程序任务job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
简言之,RM(资源)和Driver(计算)之间的解耦合靠的就是ApplicationMaster。
提交流程
Spark应用程序提交到Yarn环境中执行的时候,一般会有两种部署执行的方式:Client和Cluster。两种模式,主要区别在于:Driver程序的运行节点。
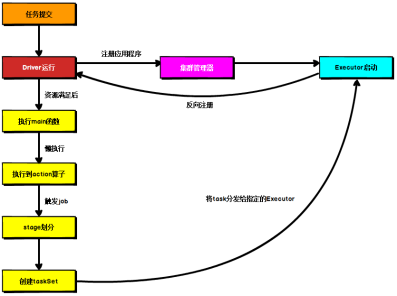
1)在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,
2)随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
3)Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程
4)Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,
5)之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









