







 本章探讨Python中的字符串(Unicode字符序列)和字节数据类型,包括Unicode字符串的编码与解码,UTF-8的优势,以及字节和字节数组的操作。讲解了如何使用struct模块处理二进制数据,还涉及位运算符和正则表达式在处理字符串中的应用。
本章探讨Python中的字符串(Unicode字符序列)和字节数据类型,包括Unicode字符串的编码与解码,UTF-8的优势,以及字节和字节数组的操作。讲解了如何使用struct模块处理二进制数据,还涉及位运算符和正则表达式在处理字符串中的应用。
本章将学到许多操作数据的方法,它们大多与下面这两种内置的Python数据类型有关。
- 字符串
Unicode字符组成的序列,用于存储文本数据。 - 字节和字节数组
8比特整数组成的序列,用于存储二进制数据。
文本字符串
Unicode
Python3中的Unicode字符串
Python3中的字符串是Unicode字符串而不是字节数组(一个字符一个字节的意思)。
这是与Python2相比最大的差别。在Python2中,我们需要区分普通的以字节为单位的字符串以及Unicode字符串。
如果你知道某个字符的Unicode ID,可以直接在Python字符串中引用这个ID获得对应字符。下面是几个例子:
1. 用\u及4个十六进制的数字就可以从Unicode 256个基本多语言平面中指定某一特定字符。其中,
- 前两个十六进制数字用于指定平面号(00到FF)
- 后面两个数字用于指定该字符位于平面中的位置索引
00号平面即为原始的ASCII字符集,字符在该平面的位置索引与它的ASCII编码一致。例子\u01FF(平面号0x01,索引为0xFF)
2. 我们需要使用更多的比特位来存储那些位于更高平面的字符。Python为此而设计的转义序列以\U开头,后面紧跟着8个十六进制的数字,其中最左一位需要为0。(前6位仍然为平面号,最后两位为索引号,因此’\u01aa’等价于’\U000001aa’)
- 你也可以通过\N{name}来应用某一字符,其中name为该字符的标准名称,这对所有平面的字符均使用。在Unicode字符名称索引页可以查到字符对应的标准名称。
Python中的unicodedata模块提供了下面两个方向的转换函数:
- lookup() —— 接受不区分大小写的标准名称,返回一个Unicode字符;
- name()——接受一个Unicode字符,返回大写形式的名称;
def unicode_test(value):
import unicodedata
name = unicodedata.name(value)
value2 = unicodedata.lookup(name)
print('value="%s", name="%s", value2="%s"' % (value, name, value2))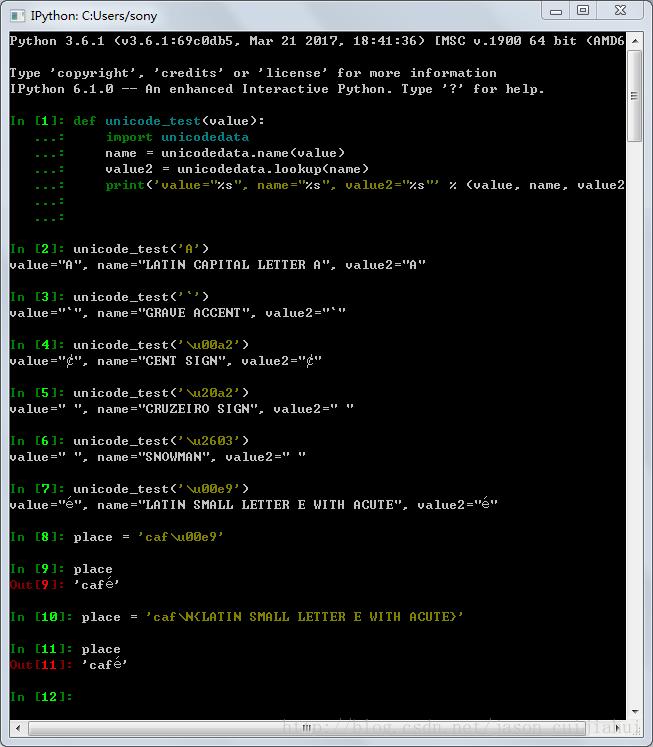
注意,unicode_test(‘\u2603’)的结果,正常应该会显示一个雪人,但实际上什么都没有。问题主要是来源于使用的字体自身的限制。没有任何一种字体涵盖了所有Unicode字符,但缺失对应字符的图片时,会以占位符的形式显示。
字符串函数len可以计算字符串中Unicode字符的个数,而不是字节数:
>>> len('$')
1
>>> len('\U0001f47b')
1 注意
Unicode字符串只是一种符号,具体在计算机上如何存储是另外一回事。比如’\U0001f47b’不代表它占用了计算机的4个字节进行存储。具体如何存储是看编码和解码方式
使用UTF-8编码和解码
对字符串进行处理,并不需要在意Python中Unicode字符的存储细节。
但当需要与外界进行数据交互时则需要完成两件事情:
- 将Unicode字符串编码为字节
- 将字节解码为Unicode字符串
如果Unicode包含的字符种类不超过64000中,我们就可以将字符ID统一存储在2字节中。遗憾的是,Unicode所包含的字符串种类远不止如此。诚然,我们可以将字符ID统一编码在3或4字节中,但这会使空间开销(内存和硬盘)增加3到4倍。
因此,UTF-8动态编码方案应运而生。这种方案会动态地为每一个Unicode字符分配1到4字节不等:
- 为ASCII字符分配1字节
- 为拉丁语系(除西里尔语)的语言分配2字节
- 为其他的位于基本多语言平面的字符分配3字节
- 为剩下的字符集分配4字节,这包括一些亚洲语言及符号
UTF-8shi Python、Linux以及HTML的标准文本编码格式。这种编码方式简单快速、字符覆盖面广、出错率低。
在代码中全都使用UTF-8编码会是一种非常棒的体验,你再也不需要不停地转换各种编码格式。如果你创建Python字符串时使用了从别的文本源(例如网页)复制粘贴过来的字符串,一定要确保文本源使用的是UTF-8编码。将Latin-1或者Windows 1252复制粘贴为Python字符串的错误及其常见,这样得到的字节序列是无效的,会产生许多后续隐患。
Unicode 和 UTF-8 有何区别?
举一个例子:It’s 知乎日报你看到的unicode字符集是这样的编码表:
| 字符 | Unicode编码(16进制) |
|---|---|
| I | 0049 |
| t | 0074 |
| ‘ | 0027 |
| s | 0073 |
| 0020 | |
| 知 | 77e5 |
| 乎 | 4e4e |
| 日 | 65e5 |
| 报 | 62a5 |
每一个字符对应一个十六进制数字。计算机只懂二进制,因此,严格按照unicode的方式(UCS-2),应该这样存储:
| 字符 | Unicode编码(2进制) |
|---|---|
| I | 00000000 01001001 |
| t | 00000000 01110100 |
| ‘ | 00000000 00100111 |
| s | 00000000 01110011 |
| 00000000 00100000 | |
| 知 | 01110111 11100101 |
| 乎 | 01001110 01001110 |
| 日 | 01100101 11100101 |
| 报 | 01100010 10100101 |
这个字符串总共占用了18个字节,但是对比中英文的二进制码,可以发现,英文前9位都是0!浪费啊,浪费硬盘,浪费流量。怎么办?UTF。
UTF-8是这样做的:
1. 单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
2. n个字节的字符(n>1),第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
于是,”It’s 知乎日报“就变成了:
| 字符 | UTF-8 |
|---|---|
| I | 01001001 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









