







 本文介绍了网络爬虫的基本原理,包括深度优先和广度优先的爬行策略,并以抓取当当网图书信息为例,详细阐述了如何查看网页结构、设定数据规则,并使用jsoup.jar进行HTML解析。通过SpringBoot框架实现,涉及model、mapper、请求工具类和解析类的编写,最后进行了Postman测试和数据库入库操作。文章强调理解爬虫基础的重要性,提示注意反爬机制和不同网站的爬虫规则。
本文介绍了网络爬虫的基本原理,包括深度优先和广度优先的爬行策略,并以抓取当当网图书信息为例,详细阐述了如何查看网页结构、设定数据规则,并使用jsoup.jar进行HTML解析。通过SpringBoot框架实现,涉及model、mapper、请求工具类和解析类的编写,最后进行了Postman测试和数据库入库操作。文章强调理解爬虫基础的重要性,提示注意反爬机制和不同网站的爬虫规则。
本文代码等仅作学习记录使用
一、爬虫原理
网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。简单的说,就是讲你上网所看到页面上的内容获取下来,并进行存储。网络爬虫的爬行策略分为深度优先和广度优先。
(1)、深度优先
深度优先搜索策略从起始网页开始,选择一个URL进入,分析这个网页中的URL,选择一个再进入。如此一个链接一个链接地抓取下去,直到处理完一条路线之后再处理下一条路线。深度优先策略设计较为简单。然而门户网站提供的链接往往最具价值,PageRank也很高,但每深入一层,网页价值和PageRank都会相应地有所下降。这暗示了重要网页通常距离种子较近,而过度深入抓取到的网页却价值很低。同时,这种策略抓取深度直接影响着抓取命中率以及抓取效率,对抓取深度是该种策略的关键。
(2)、广度优先:
广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。
二、抓取结构和规则
1.结构查看
本文主要介绍基础的抓取方式,以html格式为例
以当当网书籍页面为例,如图
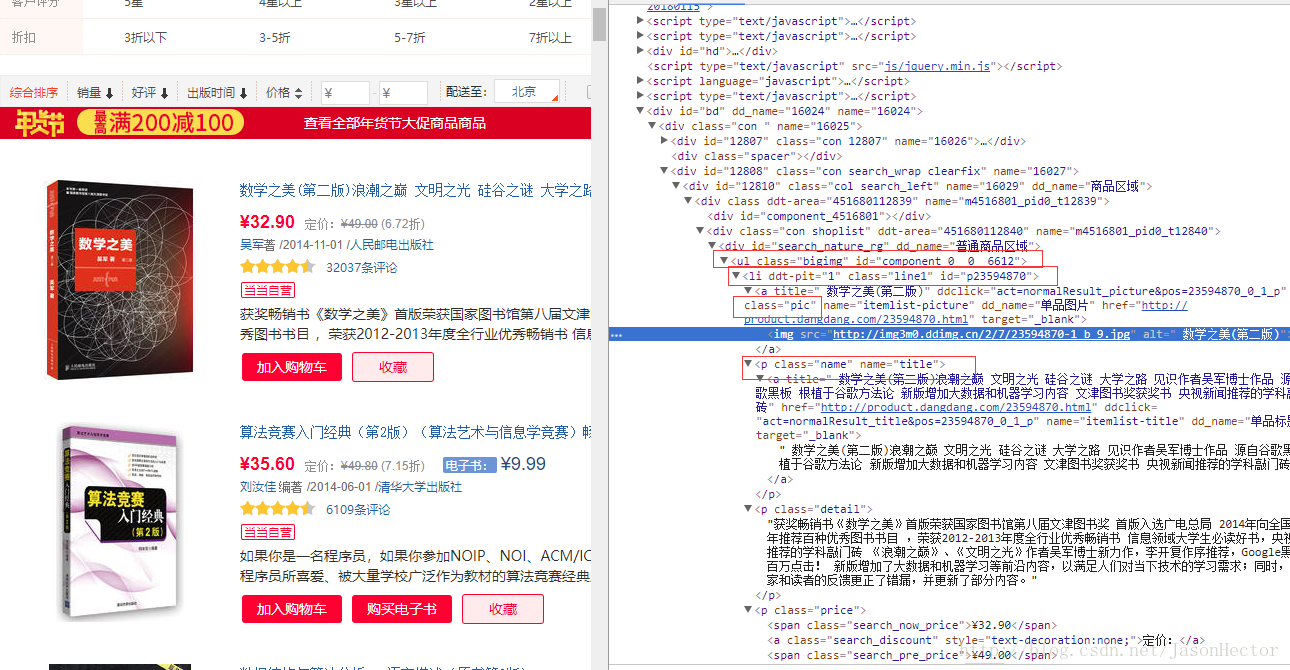
从图中可以看出 ,网页中的图书列表是一个以 ul 开始的 li标签遍历列表
我们需要的就是每个li标签中的数据,每个li标签相当于一个java中的对象。
2.html数据规则
从上图能看出每条数据外层都具备带有class [CSS样式]的标签,如下图
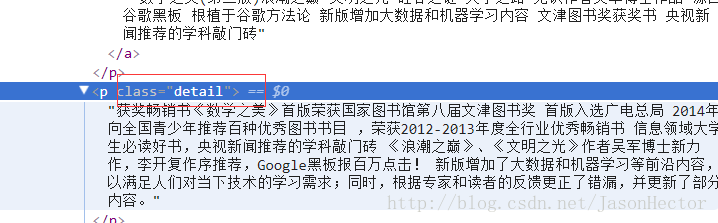
java 具有相对应的jar包来对html或xml数据结构进行解析,本文用的jar包为
三、代码实现
1.类展示
我用的springboot微框架 单纯抓取的话直接写main类就可以
(1)、model类
package com.weixin.model.book;
import com.weixin.model.BaseModel;
import org.apache.ibatis.type.Alias;
/**
* create by frank
* on 2018/01/25
* 书籍信息类
*/
@Alias("dangBook")//mybatis 数据类型绑定
public class DangBook extends BaseModel {
private String title;
private String img;
private String author;
private String publish;
private String detail;
private float price;
private String parentUrl;//父链接,即请求链接
public String getParentUrl() {
return parentUrl;
}
public void setParentUrl(String parentUrl) {
this.parentUrl = parentUrl;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublish() {
return publish;
}
public void setPublish(String publish) {
this.publish = publish;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public String getDetail() {
return detail;
}
public void setDetail(String detail) {
this.detail = detail;
}
public float getPrice() {
return price;
}
p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









