







redis源码剖析(基础数据结构篇)——字典(哈希)
最近在研究redis源码,感觉受益匪浅,想写一个系列的文章,意在与大家分享心得。首先来个基础数据结构篇吧,让同学们先了解一下redis的基础数据结构,本文主要介绍的就是第一个数据结构——字典。
字典在redis中用dict表示,其实就是一个hash表。dict结构体是非常重要的,因为不仅是我们普通的redis用户会使用它,redis内部的高性能存储也是由dict实现的。hash表的实现相信很多同学都很熟悉,但是要实现一个灵活、高性能、高扩展性的hash也是一件有技术含量的事情,各位同学不要小看了它啊。特别注意,redis中的数据存储类型Hash不等价于本文所描述的dict,这个我们在后续文章中会提到。
下面,我们就先来看看字典相关的结构体定义。
一、字典相关数据结构的定义
1、dict定义
在redis中,dict结构体就表示一个字典,即一个hash表。以下是它的具体定义:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progressif rehashidx == -1 */
int iterators; /* number of iteratorscurrently running */
} dict;我们再来看看type中到底存了什么东西。
2、dictType定义
typedef struct dictType {
unsigned int (*hashFunction)(const void*key);
void *(*keyDup)(void *privdata, const void*key);
void *(*valDup)(void *privdata, const void*obj);
int (*keyCompare)(void *privdata, constvoid *key1, const void *key2);
void (*keyDestructor)(void *privdata, void*key);
void (*valDestructor)(void *privdata, void*obj);
} dictType;可以看出,正是这个设计将dict结构体变得异常灵活,用户可以通过自定义dictType内容实现dict的多样性。redis内部已经预定义了多种dictType值,我选了几个罗列在下面。
1)命令哈希表的dictType值
dictType commandTableDictType = {
dictSdsCaseHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCaseCompare, /* key compare */
dictSdsDestructor, /* key destructor */
NULL /* val destructor */
};2)字典类型的dictType值
dictType hashDictType = {
dictEncObjHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictEncObjKeyCompare, /* key compare */
dictRedisObjectDestructor, /* key destructor */
dictRedisObjectDestructor /* val destructor */
};3)超时表的dictType值
dictType keyptrDictType = {
dictSdsHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* key compare */
NULL, /* key destructor */
NULL /* val destructor */
};4)整个redisDB哈希表的dictType值
dictType dbDictType = {
dictSdsHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* key compare */
dictSdsDestructor, /* key destructor */
dictRedisObjectDestructor /* val destructor */
};3、dictht定义
dictht表示具体的哈希表实现,具体的定义如下:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;实际上,dictht是一个基于链表的哈希表实现,也就是说table[index]存储的是一个单向链表,如图所示。
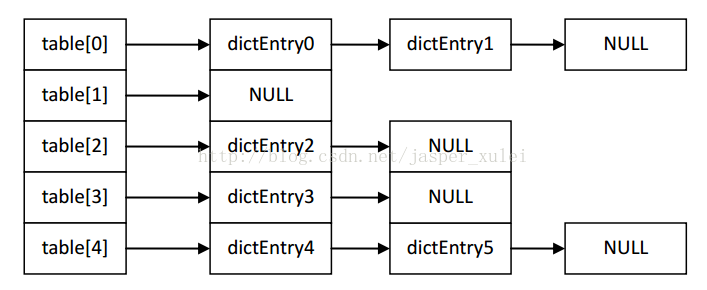
图中,我们假设size=5,dictEntryX表示不同的dictEntry数据。我们可以看到,这种数据结构可以很好的解决哈希算法中的冲突现象——凡是key address相同的dictEntry,都放入同一个链表中。
这里还要提一下redis的哈希方法。redis的哈希方法是针对某一个key,通过某个哈希算法,算出一个hash值,但这个hash值并不是最终的key address,key address通过式子key_addr=hash & sizemask得到。在size=2^n时,这个式子与取余的效果相同,但比取余快很多。所以,redis在设置size时,都会将size设置为2^n的形式。如果同学们还想了解更多的话,请参照另外一篇文章——“redis中几种哈希函数的研究”。
4、dictEntry定义
dictEntry表示一个key/value对,同时又是一个链表节点,它的定义很好理解,如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;
} dictEntry;可以看出dictEntry支持任何类型的key/value值。
5、dictIterator定义
dictIterator是dict专用的迭代器,它有两种类型——safe迭代器和unsafe迭代器,safe迭代器只有读权限,unsafe迭代器具有读写权限,但是其操作也受一定的限制。首先我们来看看他的定义:
typedef struct dictIterator {
dict *d;
int table, index, safe;
dictEntry *entry, *nextEntry;
long long fingerprint; /* unsafe iteratorfingerprint for misuse detection */
} dictIterator;在定义中,d保存迭代器相关的dict指针。table取0或1,是dict结构体重ht数组的下标,表示当前位置是在哪个哈希表上(主还是副)。index是当前哈希表的下标,它与table一起,唯一确定了元素位置。safe取0或1,0表示unsafe迭代器,1表示safe迭代器。entry指明当前元素,nextEntry指明当前元素的下一个元素,fingerprint表示dict指纹,它的作用是保证在unsafe模式下,用户的操作不会使迭代器失效。
现在我们来具体说说safe迭代器与unsafe迭代器。
safe迭代器很简单,就是一个只读的迭代器,用户只能用它依次读取dict中的内容。
unsafe迭代器则允许用户通过该迭代器对dict的内容进行修改,但这是有限制的,用户的修改不能改变主副哈希表的地址和总大小,不能在两个哈希表上添加/删除元素。即,dict结构体中的ht[0].table,ht[0].size,ht[0].used,ht[1].table,ht[1].size和ht[1].used这六个变量。那如何能保证用户不会修改这些东西呢?在使用unsafe迭代器时,redis会为迭代器对应的dict生成一个指纹,该指纹包含了上述的六个变量。当用户操作结束后,redis会再次针对那六个变量重新生成指纹,对比新旧指纹。如果新旧指纹不相同,则程序报错。redis是利用64位mix算法(64 bit mix function)生成指纹的,具体内容可参照“redis中几种哈希函数的研究”。
另外,遍历操作是很耗时的,在数据量较大时,我们应当尽量避免。
二、可扩展字典的实现原理
字典容量的动态扩展是dict实现中最复杂的一个过程,它包括两部分——expand和rehash。expand过程负责单纯的内存扩展,rehash过程负责把原来内存区域的数据拷贝到新内存区域中。下面我们就来看看redis如何实现动态扩展。
基本思路是这样的,在dict中设两个哈希表,ht[0]和ht[1]。对于dict本身而言,存在两种状态——正常状态和rehashing状态。正常状态指的是不存在rehash过程的状态,此状态下dict内部只使用ht[0]。当判断需要扩展内存时,redis会开始expand过程,扩展ht[1]的内存,使得ht[1]的容量足以容纳下当前的数据,之后dict就会进入到rehashing状态。在rehashing状态下,redis会间断性的把ht[0]中的数据rehash到ht[1]中,直到ht[0]中的数据完全转移到ht[1]中,此时我们再free掉ht[0]的内存,将ht[0]重定向到ht[1]的内存空间上,并返回到正常状态。这就完成了一次动态扩展的过程,期间需要注意的有以下几点:
1、redis采用两种方法将数据从ht[0]中rehash到哈希表ht[1]中。第一种是设置一个定时器,redis会定时的完成一部分数据的转移;第二种是在dict进行各种基本操作的时候,夹杂着一条数据项的转移过程。
2、在rehashing状态下,dict的基本操作将与正常状态下不同。首先,在插入操作时,正常状态下数据会插入到ht[0],而rehashing状态下会插入到ht[1];其次,在执行查找和删除操作时,正常状态下只涉及ht[0],rehashing状态下涉及ht[0]与ht[1];最后,在rehashing状态下,不能再进行resize、rehash、expandrehash、expand等操作。
3、进行容量扩充即正常状态转rehashing状态的时机有以下几点:
- 已用的条目数大于等于ht[0]的容量时,此时扩充的容量为与已用条目数最接近的2的n次方数。容量不够了自然要扩充,这个不用多说;
- 已用条目数量与ht[0]的容量的比例达到一定上限时,此时扩充的容量为与已用条目数的两倍最接近的2的n次方数。这个有点预分配的意思,意思就是在ht[0]快满的时候进行分配。
4、如果在rehashing状态下又出现了需要扩容的情况,则系统报错。其实这种状况很难出现,因为在rehashing状态下,每进行一次基本操作都会夹带着进行一次数据转移,基本操作的次数多了,其数据转移的速度也会随之加快。















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









