







hadoop是java开发的,其运行的环境必须是java环境,在vmvare中安装CentOS7并配置网络和jdk环境中已配置好,这里不再重复说明。
由于伪分布式需要一台电脑

修改IP和主机名分别为192.168.18.101和node01(具体操作可以参考vmvare安装那篇)
设置本机到主机的映射
vi /etc/hosts
在问答末尾添加

关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
关闭selinux
vi /etc/selinux/config
SELINUX=disabled

编辑profile,在最后添加两行
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin

ssh免密设置
ssh localhost
执行ssh localhost有两个作用,1、验证自己还没免密 2、被动生成了 /root/.ssh目录(这个目录最好不要自己创建,涉及到权限配置,最好自动生成)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
注:
如果A想免密登录到B:
A: ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
B: cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
结论:B包含了A的公钥,A就可以免密的登陆,你去陌生人家里得撬锁,去女朋友家里:拿钥匙开门
创建Hadoop安装目录
mkdir /opt/bigdata
上传Hadoop压缩包到跟目录下,然后解压缩
tar xf hadoop-2.10.1.tar.gz
将解压缩的文件夹移动到新创建的目录下
mv hadoop-2.10.1 /opt/bigdata/
配置Hadoop环境变量
vi /etc/profile
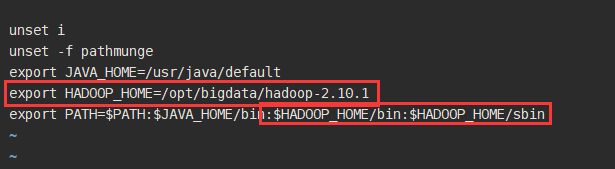
加载文件命令
source /etc/profile
配置hadoop的角色
cd $HADOOP_HOME/etc/hadoop
必须给Hadoop配置JAVAHOME要不ssh过去找不到这个环境变量的,所有要修改
vi hadoop-env.sh
export JAVA_HOME=/usr/java/ default

给出NameNode角色在哪里启动
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/ hadoop/local/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>配置DN这个角色再哪里启动
vi slaves
node01
初始化运行
hdfs namenode -format

启动
cd /var/bigdata/hadoop/local/dfs
start-dfs.sh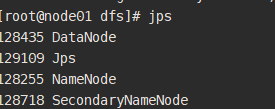
第一次: datanode和secondary角色会初始化创建自己的数据日录
访问 http://node01:50070
修改windows:C:\windows\System32\drivers\etc\hosts
192.168.18.101 node01
验证知识点
//观察ediflog的id是不是再fsimage的后边
cd /var/bigdata/hadoop/local/dfs/name/current
//SNN 只需要从NN拷贝最后时点的FSimage和增量的Editlog
cd /var/bigdata/hadoop/local/dfs/secondary/current
//hadoop命令创建目录(hdfs dfs 可以查看帮助)
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
hdfs dfs -put hadoop*.tar.gz /user/root
cd /var/bigdata/hadoop/local/dfs/data/current/BP-281175a-23-192.168.150.11-15327683431/current/finalized/subdir0/subdir0
//生成一个1到100000的文件
for i in `seq 100000`;do echo "hello hadoop $i" >> data.txt;done
//设置block为1M切割,然后上传data.txt文件到当前目录下
hdfs dfs -D dfs.blocksize=1048576 -put data.txt
cd /var/bigdata/hadoop/local/dfs/data/current/BP-281175a-23-192.168.150.11-15327683431/current/finalized/subdir0/subdir0
检查data.txt被切割的块,看数据是什么样子















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









