






目录
(1)修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml配置文件
1.前言
在安装Hadoop的教程时,到了伪分布式这一步,总是卡在启动这一步,数据节点不知道为什么就是权限不够开不了,要么就是进程占用,在杀死进程之后,整个Hadoop出现瘫痪。查遍全网的资料,都说要用chown给他777超级权限,但是我试了两天,发现这个方法似乎不太可行(个人看法),但是在之前linux中配置opencv时也遇到过类似问题,最后是使用root换源来解决的。所以我想用root用户来启动hdfs,查阅资料后发现可行,所以重装系统,开始实践。在实践之后,最后顺利启动节点。
(注意:需要修改文件都有原始内容,如果为空可能开错文件!)
话不多说,上教程。
2.安装方法
(1)修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml配置文件
1.core-site.xml
对于core-site.xml文件,我们只需要在其中指定HDFS的地址和端口号。端口号按照官方文档设置为9000即可。
输入如下命令行打开core-site.xml文件:
cd /usr/local/hadoop/etc/hadoop
sudo gedit core-site.xml在文件的中加入如下代码段:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改后的配置文件如下:
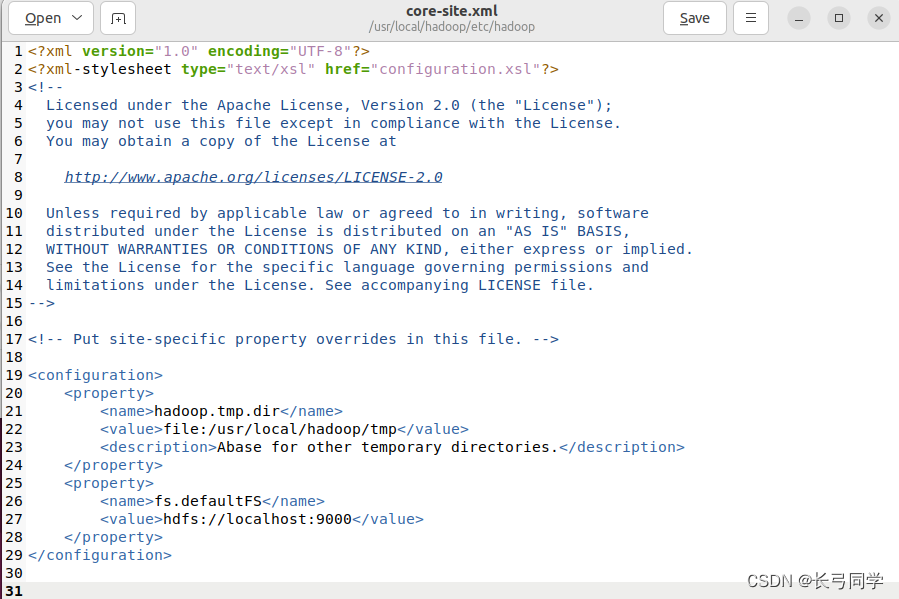
2.hdfs-site.xml
对于hdfs-site.xml文件,这里设置replication值为1,这也是Hadoop运行的默认最小值,它限制了HDFS中同一份数据的副本数量。由于这里采用伪分布式,集群中只有一个节点,因此该值只能设置为1。
输入如下命令行打开文件:
sudo gedit hdfs-site.xml
加入代码段:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改后的文件如下图所示:

3.mapred-site.xml
加入如下代码段:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>4. yarn-site.xml
加入如下代码段:
<configuration>
<property>
<name>yarn.resourcemanger.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>(2)初始化Hadoop系统。
先登录root账户(一开始没有设置root账户需要用“sudo passwd”来初始化密码)
登录root账户命令:
su登录进root后,初始化文件系统:
cd /usr/local/hadoop
./bin/hdfs namenode -format初始化完成后,如下图所示:
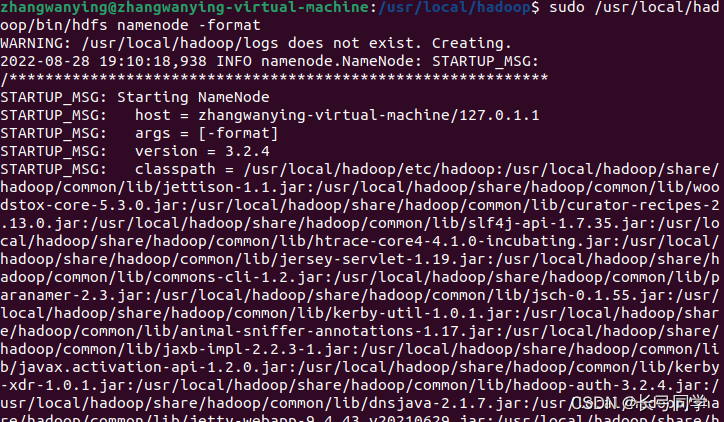

由于要使用root启动hdfs因此我们还需要改变另外几个配置文件。
(3)修改四个启动配置文件的root参数
移到/usr/loacl/hadoop/sbin路径下,修改文件:
cd /usr/hadoop/sbin/用vim编辑器打开文件命令行:
vim 文件名将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootstart-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root(4)修改hadoop-env.sh文件:
输入以下命令行打开文件并修改:
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
在hadoop-env.sh文件中最后一行加入
HADOOP_SHELL_EXECNAME=root
并且在文件中段配置JAVA环境(加入“export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341”),如下图所示

配置完成后执行如下命令行,让文件生效:
$HADOOP_HOME/bin/hdfs --daemon start datanode(5)在root中设置免密码登录
如果直接像单机中一样设置ssh免密码登录,会出现报错“root@localhost's password: localhost: Permission denied, please try again.”,这种情况需要进行以下操作:
1.(此步前需要退出root用户)修改root密码:
sudo passwd root2.辑配置文件,允许以 root 用户通过 ssh 登录:
sudo vi /etc/ssh/sshd_config找到:PermitRootLogin prohibit-password禁用
添加:PermitRootLogin yes
3.重新启动:
sudo service ssh restart启动完毕后可以再次进入root用户修改ssh密钥并设置无密码登录。
设置无密码登录命令行:
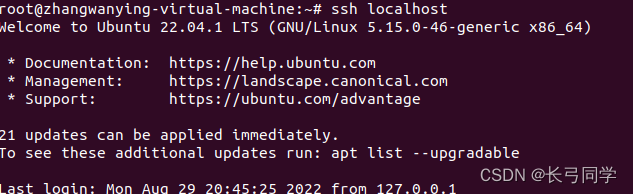
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys结束这一步后可以尝试输入“ssh localhost” 命令行进行无密码登录,如果这一步完成(即可以实现无密码登录ssh),如下图所示:
(6)在root用户中启动hdfs:
cd /usr/local/hadoop
./sbin/start-dfs.sh出现以下结果,即为启动成功(节点生成完毕):

到这一步,就启动成功了。
3.坑总结以及有用的解决方法整理:
(1)在设置ssh无密码登录时输入主机密码报错(配置文件权限问题):
问题root@localhost's password:localhost:permission denied,please try again - 努力中国 - 博客园
(2)启动hdfs时权限不够:
Hadoop localhost: frankxulei@localhost: Permission denied (publickey,password) - 程序员大本营
(3)使用root启动hdfs报错:
使用root配置的hadoop并启动会出现报错 - 猿大侠 - 博客园
(4)Hadoop启动HDFS进程的时候报错,提示权限不够:














 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









