本文转载自 http://blog.csdn.net/ironyoung/article/details/49455343
-
BP(backward propogation)神经网络
简单理解,神经网络就是一种高端的拟合技术。教程也非常多,但实际上个人觉得看看斯坦福的相关学习资料就足够,并且国内都有比较好的翻译:
三篇文章,详细的数学推导已经在里面,不赘述了。下面记录我在实现过程中碰到的一些总结与错误.
-
神经网络的过程
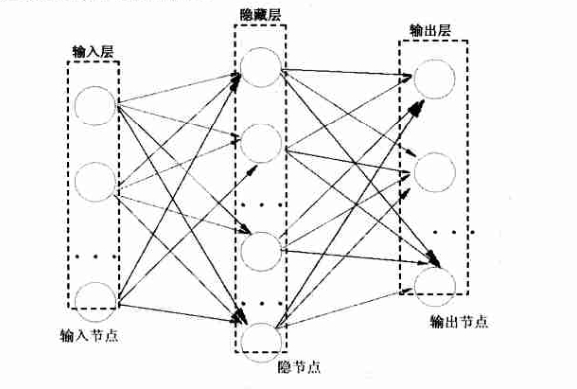
- 简单说,就是我有一堆已知的输入向量(每个向量可能有多维),每次读取一个向量(可能会有多维度),每个特征维度成为上图的输入层中一个输入节点。
- 每个维度的数值,将自己的一部分按照权值分配送给隐藏层。写程序时第一次的权值怎么办呢?其实(-1,1)随机化(绝不是0~1随机化)就好了,后续会逐渐修正。
- 这样隐含层每个节点同样有了自己的数值,同样道理,乘以权值再经过激活函数(根据需求选择,分类问题一般是 sigmoid 函数,数值拟合一般是 purelin 函数,也有特殊函数),最后传给输出节点。每个输出节点的每个值对应输出向量的一个特征维度
至此,我们完成了一次 forward pass 过程,方向是:输入层
⇒
输出层。
- 熟悉神经网络的同学肯定知道,神经网络使用时有“训练”、“测试”两部分。我们现在考虑训练过程。每次 forward pass 过程之后,输出层的值与真实值之间,存在一个差,这个差记为
δ
。 此时我们根据公式,将误差作为参数传给隐藏层节点。
- 这些误差有什么用呢?还记得我们各个层之间的随机化的权值么?就是用来修正这个权值的。同理,修改输入层与隐藏层之间的权值,我们的视角到达输入层。
至此,我们完成了一次 backward pass 过程,方向是:输入层
⇐
输出层。
第一个样本的一套做完了,即 forward pass + backward pass。
接下来呢?再做第二个样本的一套,并把误差与上一个样本误差相加;第三个样本的一套,加误差;……第N个样本的一套,加误差。等到所有样本都过了一遍,看误差和是否小于阈值(根据实际情况自由设定)时。如果不小于则进行下一整套样本,即:
- 清零误差;第一个样本,加误差;第二个样本,加误差;……第N个样本,加误差。误差和是否小于阈值……
- 误差和达到阈值,妥了,不训练了
此时输入一个测试样本,将各个特征维度的数值输入到输入层节点,一次 forward pass,得到的输出值就是我们的预测值。
-
易错点
既然这么通俗易懂,为什么实现中会出现错误呢?下面说说几个遇到的错误:
- 输入节点,究竟是每个样本的特征维度一个节点?还是每个样本一个节点?以为每个样本对应一个输出节点,是错误的。答案是每个特征一个输入节点;
- bias 必不可少!bias 是一个数值偏移量,不受上一层神经元的影响,在每个神经元汇总上一层的信息之后,都需要进行偏移之后再作为激活函数的输入。开头教程中有说明,这是为什么呢?举个例子,如果我们学习 XOR 问题,2个输入节点是0、0,如果没有 bias 所有隐含层节点都是同一个值,产生对称失效问题;
- 神经网络有多少隐含层、每个隐含层多少神经元、学习效率,都是需要调试的。没有确解,但要保证每次循环中,样本的误差和呈下降趋势
C++实现代码:
#pragma once
#include <iostream>
#include <cmath>
#include <vector>
#include <stdlib.h>
#include <time.h>
using namespace std;
#define innode 2
#define hidenode 4
#define hidelayer 1
#define outnode 1
#define learningRate 0.9
inline double get_11Random()
{
return ((2.0*(double)rand()/RAND_MAX) - 1);
}
inline double sigmoid(double x)
{
double ans = 1 / (1+exp(-x));
return ans;
}
typedef struct inputNode
{
double value;
vector<double> weight, wDeltaSum;
}inputNode;
typedef struct outputNode
{
double value, delta, rightout, bias, bDeltaSum;
}outputNode;
typedef struct hiddenNode
{
double value, delta, bias, bDeltaSum;
vector<double> weight, wDeltaSum;
}hiddenNode;
typedef struct sample
{
vector<double> in, out;
}sample;
class BpNet
{
public:
BpNet();
void forwardPropagationEpoc();
void backPropagationEpoc();
void training (static vector<sample> sampleGroup, double threshold);
void predict (vector<sample>& testGroup);
void setInput (static vector<double> sampleIn);
void setOutput(static vector<double> sampleOut);
public:
double error;
inputNode* inputLayer[innode];
outputNode* outputLayer[outnode];
hiddenNode* hiddenLayer[hidelayer][hidenode];
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
#include "BPnet.h"
using namespace std;
BpNet::BpNet()
{
srand((unsigned)time(NULL));
error = 100.f;
for (int i = 0; i < innode; i++)
{
inputLayer[i] = new inputNode();
for (int j = 0; j < hidenode; j++)
{
inputLayer[i]->weight.push_back(get_11Random());
inputLayer[i]->wDeltaSum.push_back(0.f);
}
}
for (int i = 0; i < hidelayer; i++)
{
if (i == hidelayer - 1)
{
for (int j = 0; j < hidenode; j++)
{
hiddenLayer[i][j] = new hiddenNode();
hiddenLayer[i][j]->bias = get_11Random();
for (int k = 0; k < outnode; k++)
{
hiddenLayer[i][j]->weight.push_back(get_11Random());
hiddenLayer[i][j]->wDeltaSum.push_back(0.f);
}
}
}
else
{
for (int j = 0; j < hidenode; j++)
{
hiddenLayer[i][j] = new hiddenNode();
hiddenLayer[i][j]->bias = get_11Random();
for (int k = 0; k < hidenode; k++) {hiddenLayer[i][j]->weight.push_back(get_11Random());}
}
}
}
for (int i = 0; i < outnode; i++)
{
outputLayer[i] = new outputNode();
outputLayer[i]->bias = get_11Random();
}
}
void BpNet::forwardPropagationEpoc()
{
for (int i = 0; i < hidelayer; i++)
{
if (i == 0)
{
for (int j = 0; j < hidenode; j++)
{
double sum = 0.f;
for (int k = 0; k < innode; k++)
{
sum += inputLayer[k]->value * inputLayer[k]->weight[j];
}
sum += hiddenLayer[i][j]->bias;
hiddenLayer[i][j]->value = sigmoid(sum);
}
}
else
{
for (int j = 0; j < hidenode; j++)
{
double sum = 0.f;
for (int k = 0; k < hidenode; k++)
{
sum += hiddenLayer[i-1][k]->value * hiddenLayer[i-1][k]->weight[j];
}
sum += hiddenLayer[i][j]->bias;
hiddenLayer[i][j]->value = sigmoid(sum);
}
}
}
for (int i = 0; i < outnode; i++)
{
double sum = 0.f;
for (int j = 0; j < hidenode; j++)
{
sum += hiddenLayer[hidelayer-1][j]->value * hiddenLayer[hidelayer-1][j]->weight[i];
}
sum += outputLayer[i]->bias;
outputLayer[i]->value = sigmoid(sum);
}
}
void BpNet::backPropagationEpoc()
{
for (int i = 0; i < outnode; i++)
{
double tmpe = fabs(outputLayer[i]->value-outputLayer[i]->rightout);
error += tmpe * tmpe / 2;
outputLayer[i]->delta
= (outputLayer[i]->value-outputLayer[i]->rightout)*(1-outputLayer[i]->value)*outputLayer[i]->value;
}
for (int i = hidelayer - 1; i >= 0; i--)
{
if (i == hidelayer - 1)
{
for (int j = 0; j < hidenode; j++)
{
double sum = 0.f;
for (int k=0; k<outnode; k++){sum += outputLayer[k]->delta * hiddenLayer[i][j]->weight[k];}
hiddenLayer[i][j]->delta = sum * (1 - hiddenLayer[i][j]->value) * hiddenLayer[i][j]->value;
}
}
else
{
for (int j = 0; j < hidenode; j++)
{
double sum = 0.f;
for (int k=0; k<hidenode; k++){sum += hiddenLayer[i + 1][k]->delta * hiddenLayer[i][j]->weight[k];}
hiddenLayer[i][j]->delta = sum * (1 - hiddenLayer[i][j]->value) * hiddenLayer[i][j]->value;
}
}
}
for (int i = 0; i < innode; i++)
{
for (int j = 0; j < hidenode; j++)
{
inputLayer[i]->wDeltaSum[j] += inputLayer[i]->value * hiddenLayer[0][j]->delta;
}
}
for (int i = 0; i < hidelayer; i++)
{
if (i == hidelayer - 1)
{
for (int j = 0; j < hidenode; j++)
{
hiddenLayer[i][j]->bDeltaSum += hiddenLayer[i][j]->delta;
for (int k = 0; k < outnode; k++)
{ hiddenLayer[i][j]->wDeltaSum[k] += hiddenLayer[i][j]->value * outputLayer[k]->delta; }
}
}
else
{
for (int j = 0; j < hidenode; j++)
{
hiddenLayer[i][j]->bDeltaSum += hiddenLayer[i][j]->delta;
for (int k = 0; k < hidenode; k++)
{ hiddenLayer[i][j]->wDeltaSum[k] += hiddenLayer[i][j]->value * hiddenLayer[i+1][k]->delta; }
}
}
}
for (int i = 0; i < outnode; i++) outputLayer[i]->bDeltaSum += outputLayer[i]->delta;
}
void BpNet::training(static vector<sample> sampleGroup, double threshold)
{
int sampleNum = sampleGroup.size();
while(error > threshold)
{
cout << "training error: " << error << endl;
error = 0.f;
for (int i = 0; i < innode; i++) inputLayer[i]->wDeltaSum.assign(inputLayer[i]->wDeltaSum.size(), 0.f);
for (int i = 0; i < hidelayer; i++){
for (int j = 0; j < hidenode; j++)
{
hiddenLayer[i][j]->wDeltaSum.assign(hiddenLayer[i][j]->wDeltaSum.size(), 0.f);
hiddenLayer[i][j]->bDeltaSum = 0.f;
}
}
for (int i = 0; i < outnode; i++) outputLayer[i]->bDeltaSum = 0.f;
for (int iter = 0; iter < sampleNum; iter++)
{
setInput(sampleGroup[iter].in);
setOutput(sampleGroup[iter].out);
forwardPropagationEpoc();
backPropagationEpoc();
}
for (int i = 0; i < innode; i++)
{
for (int j = 0; j < hidenode; j++)
{
inputLayer[i]->weight[j] -= learningRate * inputLayer[i]->wDeltaSum[j] / sampleNum;
}
}
for (int i = 0; i < hidelayer; i++)
{
if (i == hidelayer - 1)
{
for (int j = 0; j < hidenode; j++)
{
hiddenLayer[i][j]->bias -= learningRate * hiddenLayer[i][j]->bDeltaSum / sampleNum;
for (int k = 0; k < outnode; k++)
{ hiddenLayer[i][j]->weight[k] -= learningRate * hiddenLayer[i][j]->wDeltaSum[k] / sampleNum; }
}
}
else
{
for (int j = 0; j < hidenode; j++)
{
hiddenLayer[i][j]->bias -= learningRate * hiddenLayer[i][j]->bDeltaSum / sampleNum;
for (int k = 0; k < hidenode; k++)
{ hiddenLayer[i][j]->weight[k] -= learningRate * hiddenLayer[i][j]->wDeltaSum[k] / sampleNum; }
}
}
}
for (int i = 0; i < outnode; i++)
{ outputLayer[i]->bias -= learningRate * outputLayer[i]->bDeltaSum / sampleNum; }
}
}
void BpNet::predict(vector<sample>& testGroup)
{
int testNum = testGroup.size();
for (int iter = 0; iter < testNum; iter++)
{
testGroup[iter].out.clear();
setInput(testGroup[iter].in);
for (int i = 0; i < hidelayer; i++)
{
if (i == 0)
{
for (int j = 0; j < hidenode; j++)
{
double sum = 0.f;
for (int k = 0; k < innode; k++)
{
sum += inputLayer[k]->value * inputLayer[k]->weight[j];
}
sum += hiddenLayer[i][j]->bias;
hiddenLayer[i][j]->value = sigmoid(sum);
}
}
else
{
for (int j = 0; j < hidenode; j++)
{
double sum = 0.f;
for (int k = 0; k < hidenode; k++)
{
sum += hiddenLayer[i-1][k]->value * hiddenLayer[i-1][k]->weight[j];
}
sum += hiddenLayer[i][j]->bias;
hiddenLayer[i][j]->value = sigmoid(sum);
}
}
}
for (int i = 0; i < outnode; i++)
{
double sum = 0.f;
for (int j = 0; j < hidenode; j++)
{
sum += hiddenLayer[hidelayer-1][j]->value * hiddenLayer[hidelayer-1][j]->weight[i];
}
sum += outputLayer[i]->bias;
outputLayer[i]->value = sigmoid(sum);
testGroup[iter].out.push_back(outputLayer[i]->value);
}
}
}
void BpNet::setInput(static vector<double> sampleIn)
{
for (int i = 0; i < innode; i++) inputLayer[i]->value = sampleIn[i];
}
void BpNet::setOutput(static vector<double> sampleOut)
{
for (int i = 0; i < outnode; i++) outputLayer[i]->rightout = sampleOut[i];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
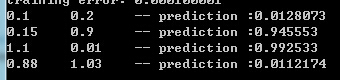
- 最后是 main 函数(我们这里使用典型非线性问题:XOR 测试):
#include "BPnet.h"
int main()
{
BpNet testNet;
vector<double> samplein[4];
vector<double> sampleout[4];
samplein[0].push_back(0); samplein[0].push_back(0); sampleout[0].push_back(0);
samplein[1].push_back(0); samplein[1].push_back(1); sampleout[1].push_back(1);
samplein[2].push_back(1); samplein[2].push_back(0); sampleout[2].push_back(1);
samplein[3].push_back(1); samplein[3].push_back(1); sampleout[3].push_back(0);
sample sampleInOut[4];
for (int i = 0; i < 4; i++)
{
sampleInOut[i].in = samplein[i];
sampleInOut[i].out = sampleout[i];
}
vector<sample> sampleGroup(sampleInOut, sampleInOut + 4);
testNet.training(sampleGroup, 0.0001);
vector<double> testin[4];
vector<double> testout[4];
testin[0].push_back(0.1); testin[0].push_back(0.2);
testin[1].push_back(0.15); testin[1].push_back(0.9);
testin[2].push_back(1.1); testin[2].push_back(0.01);
testin[3].push_back(0.88); testin[3].push_back(1.03);
sample testInOut[4];
for (int i = 0; i < 4; i++) testInOut[i].in = testin[i];
vector<sample> testGroup(testInOut, testInOut + 4);
testNet.predict(testGroup);
for (int i = 0; i < testGroup.size(); i++)
{
for (int j = 0; j < testGroup[i].in.size(); j++) cout << testGroup[i].in[j] << "\t";
cout << "-- prediction :";
for (int j = 0; j < testGroup[i].out.size(); j++) cout << testGroup[i].out[j] << "\t";
cout << endl;
}
system("pause");
return 0;
}






















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









