









为什么基于数学原理的程序会那么难以实现?因为缺乏一定的训练。事实上,基于数学定理的算法并不比「数据结构与算法」的算法复杂更多(前提是对数学原理的深入理解),它们往往并不需要高级的数据结构作为支撑(除非算法本身即是基于图、基于树、基于hash散列),也不要高级的语法特性完成某一功能,算法所赖以实现的基石仍是基本的循环分判断等机制。
为什么基于数学原理的程序会那么难以阅读?因为缺乏程序语言向数学公式的转换的训练,还是缺乏训练。(迷失在茫茫的记号(notation)、变量(variant)之海,不明白其中的变量所代表的数学意义,etc)。
demo演示
学习任何一门知识或者技术的方法,还应当遵循马克思哲学体系关于认识论的部分,即:认识的两次飞跃,从感性认识上升为理性认识,再从理论回归实践。两个过程互为因果,循环往复,交替向前,直至建立起对一门科学对一个领域全面而深入的认识。
这个观点是怎么来的呢,是看「晓说」来的,高晓松老师(晓松老师也是借鉴「诗经」的创作手法,赋比兴,「关关雎鸠,在河之洲,窈窕淑女,君子好逑」,悲伤还是欢愉,看门见山,直抒胸臆)。在讲台湾,将日本,将欧洲,都会先说感官,衣食住行,国民性,这些浅表的,然后庖丁解牛,深入内部,探究其根源,而不是一上来就是历史、就是深刻、就是宏观叙事,一来容易接受,二则也较为有趣。
神经网络拓扑结构示意图:
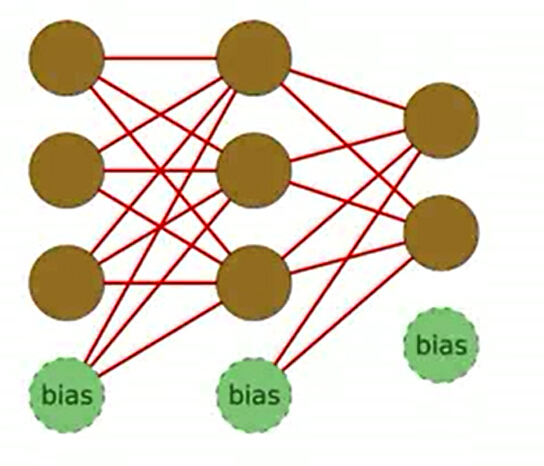
该网络的拓扑结构为3-3-2,3 inputs,2 outputs。
所适配的训练样本集自然(3个输入值,2个输出值),根据不同的样本,反复更新神经元之间的权值,所要学习的参数(也即权值)的个数为(3+1)*3+(3+1)*2,加1表示bias neuron(其输出值为1)也参与向下一层(layer)的传播。
神经网络的执行流程
这里我们以一个小应用(神经网络解异或(xor)问题)来说明神经网络的基本处理流程,建立起感官认识。
首先generate如下格式的数据集(用以训练):
topology: 2 4 1 // 代表神经网络拓扑结构,即该神经网络共三层(three layers),每一层神经元的个数分别为2,4,和1个。
in: 0 1 // 输入为0、1时,输出为1,等四种情况,即为异或问题
out: 1
in: 0 1
out: 1
in: 1 0
out: 1
…
程序读取该训练集,分别对每一个样本进行训练(input values -> forward propagation 前向,target values -> backward propagation 后向),实现权值的更新(整个训练过程得到的就是神经元之间的权值)。
while(!trainData.isEof()) // trainData是输入文件流
{
vector<double> inputVals, targetVals;
trainData.getNextInputs(inputVals);
myNet.feedWard(inputVals);
trainData.getTargetOutputs(targetVals)
myNet.backProg(targetVals);
}
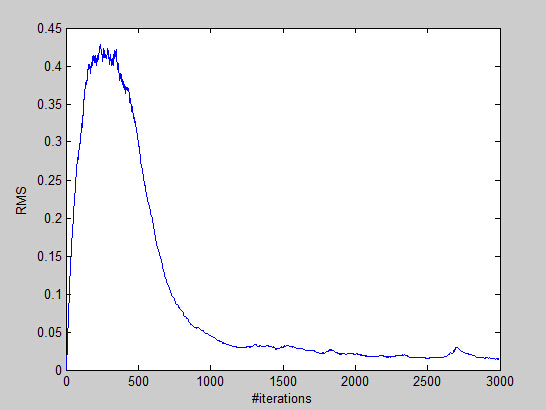
下图为每次的训练误差(RMS:Root Mean Square)随训练样本增加的变化情况:
算法流程及规格
常用记号
为了下文表述问题的方便,这里先引入一些记号(notation),记号并不多,也不复杂,刚好作为类结构设计(面向对象)Neuron中的成员变量(member variables):
-
Wlij
:
l−1
层第
i
个神经元(neuron)到第
vector<double> m_outputVals; slj :加权和(weighted sum), 或者通俗地说就是最终的的得分值score- xlj :对上一层的加权和weighted sum转换后的神经元的输出值
m_outputVals = Neuron::transferFcn(weighted_sum);- δlj :其定义式为 δlj=∂en∂slj ,
double m_gradient;传递函数(transfer function)设计:
算法流程
神经网络的全部难点正在于反向传播计算权值梯度 δlj 。
这里先总体、定性地说明神经网络的算法流程。
1. Initialization:初始化各层(layer)神经元(neuron)的权重(weight, Wlij );
2. Feed forward:前向更新各层各神经元的输入( xli );
slj=∑i=0dl−1Wlij⋅xl−1i
xlj=tanh(slj)
3. Back Propagation:后向更新各个神经元的权值梯度(delta weight, δli ),已知神经元共 L 层
δli={∑k=0dl−1−1δl+1kWljk}tanh′(slj)
又根据 en=(yn−xL1)2 ,可知对于输出层来说:
δLj=−2(yn−xL1)tanh′(slj)
4. Update:更新权重 Wlij←Wlij+ηxl−1iδlj ,更新的顺序应当是从后往前,也即更新倒数第二层向最后一层的权重,然后倒数第三层向倒数第二层的权重,这本身也符合权值扩散的方向(总不能反过来,第二层向第一层,第三层向第二层)。Cpp实现
好的数据结构设计是算法完成的一半。
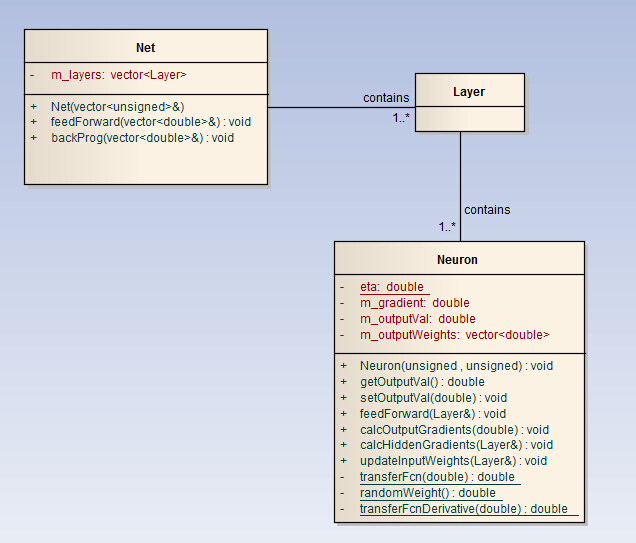
类结构设计
UML类图
核心代码段分析
Net 类构造
Net::Net(const vector<unsigned> &topology) { unsigned numLayers = topology.size(); for (unsigned layerNum = 0; layerNum < numLayers; ++layerNum) { m_layers.push_back(Layer()); unsigned numOutputs = layerNum == topology.size() - 1 ? 0 : topology[layerNum + 1]; // never forget to add a bias neuron in each layer. for (unsigned neuronNum = 0; neuronNum <= topology[layerNum]; ++neuronNum) { m_layers.back().push_back(Neuron(numOutputs, neuronNum)); cout << "Made a Neuron!" << endl; } // output value of bias neuron in each layer equals 1.0 m_layers.back().back().setOutputVal(1.0); } }Neuron类构造
Neuron::Neuron(unsigned numOutputs, unsigned myIndex):m_myIdx(myIdx) { for (unsigned c = 0; c < numOutputs; ++c) m_outputWeights.push_back(Neuron::rndomWeight()); }Neuron::feedForward() 前向
void Neuron::feedForward(const Layer &prevLayer) { double weighted_sum = 0.0; for (unsigned n = 0; n < prevLayer.size(); ++n) { weighted_sum += prevLayer[n].getOutputVal() * prevLayer[n].m_outputWeights[m_myIdx]; } m_outputVal = Neuron::transferFunction(weighted_sum ); }Net::backProg()
void Net::backProp(const vector<double> &targetVals) { //1. Calculate overall net error(RMS of output neuron errors) Layer &outputLayer = m_layers.back(); m_error = 0.0; for (unsigned n = 0; n < outputLayer.size() - 1; ++n) { double delta = targetVals[n] - outputLayer[n].getOutputVal(); m_error += delta * delta; } m_error /= outputLayer.size() - 1; // get average error squared m_error = sqrt(m_error); // RMS //2. Implement a recent average measurement m_recentAverageError = (m_recentAverageError * m_recentAverageSmoothingFactor + m_error) / (m_recentAverageSmoothingFactor + 1.0); //3. Calculate output layer gradients for (unsigned n = 0; n < outputLayer.size() - 1; ++n) { outputLayer[n].calcOutputGradients(targetVals[n]); } //4. Calculate hidden layer gradients for (unsigned layerNum = m_layers.size() - 2; layerNum > 0; --layerNum) { Layer &hiddenLayer = m_layers[layerNum]; Layer &nextLayer = m_layers[layerNum + 1]; for (unsigned n = 0; n < hiddenLayer.size(); ++n) { hiddenLayer[n].calcHiddenGradients(nextLayer); } } //5. For all layers from outputs to first hidden layer, // update connection weights for (unsigned layerNum = m_layers.size() - 1; layerNum > 0; --layerNum) { Layer &layer = m_layers[layerNum]; Layer &prevLayer = m_layers[layerNum - 1]; for (unsigned n = 0; n < layer.size() - 1; ++n) { layer[n].updateInputWeights(prevLayer); } } }
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











