







索引
索引是帮助MySQL高效获取数据的排好序的数据结构(容易忽略的点:排好序)(形象点就是教科书的目录)
索引存储在文件里(也就是说有IO操作)

二叉树与红黑树的比较
- 二叉树:当数据依次递增时,二叉树就相当于一个链表一样,查询效率就会降低。

从上面我们发现,红黑树相比较于二叉树又进步了一些,但红黑树还是有些问题:那就是数据量大的话,红黑树的深度会很深,也就是说深度不可控,这样一来查找数据还是会很耗时
HASH
-
对索引的key进行一次hash计算就可以定位出数据存储的位置
-
很多时候Hash索引要比B+ 树索引更高效
-
仅能满足 “=”,“IN”,不支持范围查询
-
hash冲突问题
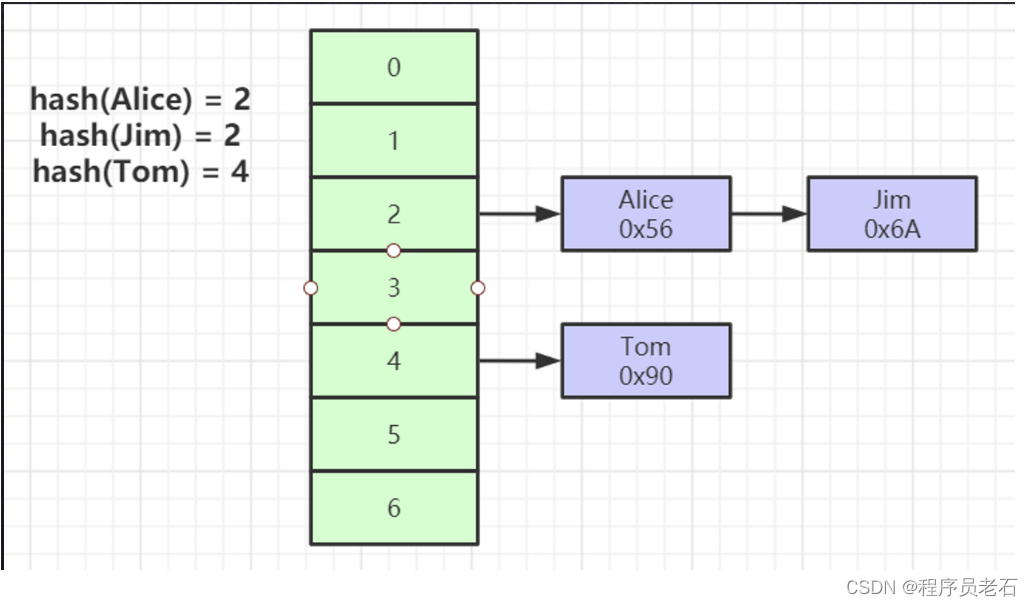

从上面我们发现,相比较于红黑树,hash可以固定“深度”,且映射到磁盘存储引用,这样查找数据直接告诉磁盘数据在哪,查找数据也挺快的,但是 hash 还是有些不足:那就是不能范围查找,比如我们查找Col1>1的数据,当然如果我们查询操作很少的话,我们也可以选择hash数据结构,因为它查找数据挺快的,这也是mysql的索引方法除了B+Tree还有hash.
BTree
- 叶子节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列

从上面看,我们发现BTree又进步了一些,查询速度提高,存储容量也没影响到。当然有人可能会这样想,那我们为什么不把数据全部都存在一个节点,这样深度不就是1了吗?
当然不行了!java拿取数据一般是这样的:java程序–>CPU—>内存---->硬盘,而内存与硬盘的交互是有大小限制的,是一页数据4k左右,所以不能把所有数据都放在一个节点来获取,一般来说节点会尽量预存4K容量。
看到这里,我们知道(4K=节点;节点=小节点*小节点的容量)一个节点是4K,而节点内有几个小节点,那么也就是说,只要我们每个的小节点的data容量越小,那么可以存的节点也就可以更多.
B+Tree
-
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
-
叶子节点包含所有索引字段
-
叶子节点用指针连接,提高区间访问的性能
索引的数据类型假设为bigint,在内存中一般占用8个字节,存放下一个节点的地址大约6个字节,那么跟节点最多可以存放16kb/(8b+6b) = 1170(个)
假设树的高度只有3,第二行叶子节点的数据同样可以存放1170个元素
1170 * 1170 * 16 = 2千多万
如果使用B-Tree,存放2千多万条数据,那么树的高度要远远大于3,因此B-Tree的查找效率比B+Tree的慢
查找col=30的元素顺序:
1、首先是查询根节点数据,将根节点的数据全部加载到RAM常驻内存区域(一次磁盘I/O),再将30这个元素放到内存区域查找
2、通过折半查找算法,找到30在15和56之间,再向下查找,将15,20,49这组数据放到内存中
3、再到内存中查找,以此类推

B+Tree通过把data不放在非叶子节点来增加度(小节点),一般会一百个以上使得深度是3~5,从而减少查询次数。并且,叶子节点之间会有指针,数据又是递增的,这使得我们范围查找可以通过指针连接查找,而不再从上面节点往下一个个找。
结论:B+Tree 既减少查询次数又提供了很好的范围查询
MyISAM索引实现(非聚集)
MyISAM索引文件和数据文件是分离的,数据.MYD+结构.frm+索引.MYI三个文件
那myisam的索引是什么样的?

InnoDB索引实现(聚集)
- 数据文件本身就是索引文件
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
- 为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
使用主键来组织整张表的数据构建为一个B+Tree结构,如果没有自增的主键,mysql底层会建一个隐藏列,使用这个隐藏列来组织整张表的数据构建B+Tree结构。 - 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)

在InnoDB中主键索引就是聚集索引,其他的索引都是非聚集索引
联合索引的底层存储结构长什么样?

索引类型
mysql索引类型normal,unique,full text的区别是什么?
-
normal:表示普通索引
-
unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique
-
full textl: 表示 全文搜索的索引。 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
总结,索引的类别由建立索引的字段内容特性来决定,通常normal最常见。
谈谈你对聚簇索引的理解
- 聚簇索引:
- 将数据存储和索引放到了一块,找到了索引也就找到了数据
- 一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。
- 非聚簇索引:
- 将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行。
- MyISAM通过key_buffer把索引先缓存到了内存中,当需要访问数据时(通过索引访问数据),在内存中直接查找索引,然后通过索引找到磁盘相应数据。这也就是为什么索引不在key buffer命中时,速度慢的原因
聚集索引⼀个表只能有⼀个,⽽⾮聚集索引⼀个表可以存在多个。聚集索引存储记录是物理上连续存在,⽽⾮聚集索引是逻辑上的连续,物理存储并不连续。

















 2613
2613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









