







1、聚集索引(主键索引)
将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据(所有字段的值)
2、非聚集索引(辅助索引)
将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
总结:
在存储引擎为 InnoDB 的表中,主键索引的类型是聚簇索引,辅助索引的类型是都是非聚簇索引。结合上边对聚簇索引、非聚簇索引的定义,我们可以知道,InnoDB 的表中主键索引中的叶子点上存储了行数据(所有字段的值,而辅助索引叶子节点存储了索引列的值和主键值。
2.1、聚集索引和非聚集索引图解:
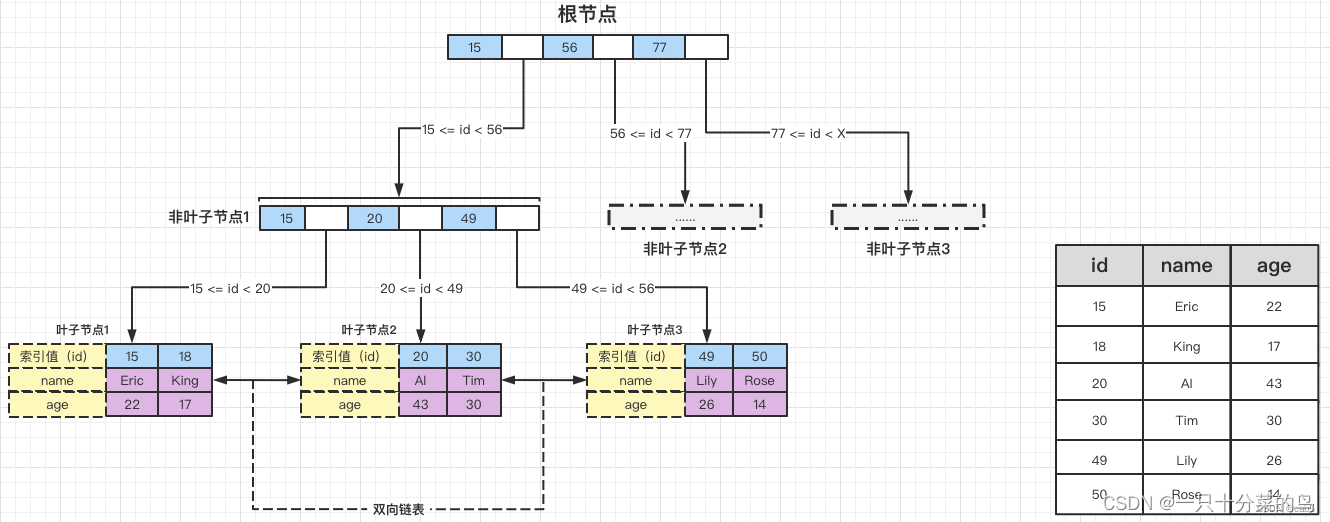
InnoDB的聚集索引
InnoDB的非聚集索引

图示根据主键查询的过程:

整个查询的过程如下:
- 查询 id(主键) 为 18 的数据,SELECT id, name, age WHERE id = 18。
- 首先在「根节点:节点一」上,id = 18 落在了 15 <= id < 56 范围之内,这样我们就知道了下级节点「非叶子节点:节点2-1」的地址。
- 根据【步骤2】得到的「非叶子节点:节点2-1」的地址,找到对应的「非叶子节点:节点2-1」。然后,id = 18 又落在了 15 <= id < 20 范围之内,这样我们就知道了再下一级节点「叶子节点:节点3-1」的地址。
- 根据【步骤3】得到的「叶子节点:节点3-1」的地址,找到对应的「叶子节点:节点3-1」。最后,在「叶子节点:节点3-1」这个节点上找到 id = 18 对应的数据 {“id”: 18, “name”: “King”, “age”: 17}
2.2、MyISAM
在存储引擎为 MyISAM 的表中,主键索引和辅助索引的类型都是非聚簇索引。两棵 B+Tree 的结构完全一致,只是存储的内容不同,主键索引 B+Tree 的节点存储了「主键」+「数据记录的地址」,辅助键索引 B+Tree 存储了「索引列的值」+「数据记录的地址」。还有一点不同是主键索引中的 key 必须是唯一的,而辅助索引中的 key 可以重复。
MyISAM-主键索引

MyISAM-辅助索引(非聚簇索引)
3、索引覆盖
索引中已经包含了所有需要读取的列数据的查询方式称为覆盖索引(或索引覆盖)。
简单来说查询时减少回表次数了。
如果非聚簇索引的叶子节点上有我们想要的返回的数据(字段),那就不需要回表了。
例如:
name 和 idcard 字段创建了一个联合索引(非聚簇索引),
我们只想返回 主键、name、idcard 这 3 个字段(SELECT id, name, idcard WHERE name = “那XX”),
因为 name、idcard 作为一个联合索引已经在辅助索引上的叶子节点上存有 name、idcard 的具体值,所以就不需要再回表操作了(除非 SELECT 里再增加一个 address 字段,这样就需要回表了)。
4、索引下推
索引条件下推就是 “过滤的动作 尽量由 下层的存储引擎层 通过 使用索引 来完成,而不需要上推到 Server 层进行处理。
索引下推,严格来说应该叫「索引条件下推」。该功能是 MySQL 数据库 5.6 版本添加的,用于优化数据查询,默认情况处于开启状态。我们可以通过如下命令来开启和关闭「索引条件下推」功能:
开启
SET optimizer_switch = 'index_condition_pushdown=on'
关闭
SET optimizer_switch = 'index_condition_pushdown=off'
下面通过一个例子来说下什么是「索引条件下推」,首先我们假设有这么一张表:
- 表名:t_user
- 字段:id,name,mobile
- 辅助索引:name + mobile(索引名:name_mobile_normal)
下面,让我们来分别看下关闭和开启「索引条件下推」这两种情况,下边这个查询语句的执行计划有怎样的不同
EXPLAIN SELECT * FROM t_user WHERE name = 'A' AND mobile LIKE '%138'关闭「索引条件下推」

开启「索引条件下推」

从上边,我们可以看到,关闭「索引条件下推」时候 Extra 是 Using where;开启「索引条件下推」时候 Extra 是 Using index condition。
索引下推案例:
select * from t_user where name like 'L%' and age = 17;这条语句从最左匹配原则上来说是不符合的,原因在于只有name用的索引,但是age并没有用到。
不用索引下推的执行过程:
第一步:利用索引找出name带'L'的数据行:LiLei、Lili、Lisa、Lucy 这四条索引数据
第二步:再根据这四条索引数据中的 id 值,逐一进行回表扫描,从聚簇索引中找到相应的行数据,将找到的行数据返回给 server 层。
第三步:在server层判断age = 17,进行筛选,最终只留下 Lucy 用户的数据信息。
使用索引下推的执行过程:
第一步:利用索引找出name带'L'的数据行:LiLei、Lili、Lisa、Lucy 这四条索引数据
第二步:根据 age = 17 这个条件,对四条索引数据进行判断筛选,最终只留下 Lucy 用户的数据信息。
(注意:这一步不是直接进行回表操作,而是根据 age = 17 这个条件,对四条索引数据进行判断筛选)
第三步:将符合条件的索引对应的 id 进行回表扫描,最终将找到的行数据返回给 server 层。
比较二者的第二步我们发现,索引下推的方式极大的减少了回表次数。
索引下推需要注意的情况:
下推的前提是索引中有 age 列信息,如果是其它条件,如 gender = 0,这个即使下推下来也没用














 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









