







HDFS实际应用场景之文件合并
场景
合并小文件,存放到HDFS上。例如:当需要分析来自许多服务器的Apache日志时,各个日志文件可能比较小,然而Hadoop更适合处理大文件,如果将所有的文件合并,再复制上传到HDFS上的话,需要占用本地计算机大量的磁盘空间。采取在向HDFS复制上传文件过程中将小文件进行合并,效果会更好。
开发程序
开发一个PutMerge程序,用于将合并文件后放入HDFS。
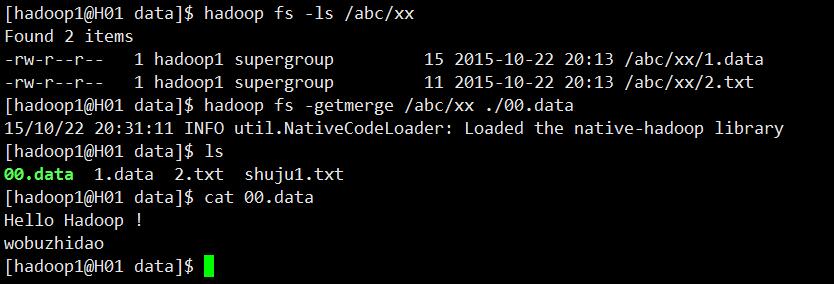
命令getmerge
用于将一组HDFS文件在复制到本地计算机一起进行合并。
代码:putmerge
package hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* 功能:在向HDFS上传复制文件的过程中进行合并文件
*
*
*/
public class PutMerge {
/**
* 复制上传文件,并将文件合并
*
* @param localDir--->本地要上传的文件目录
* @param hdfsFile--->HDFS上的文件名称,包括路径
*/
public static void put(String localDir, String hdfsFile) {
// 1)获取配置信息
Configuration conf = new Configuration();
// 本地路径与HDFS路径
Path localPath = new Path(localDir);
Path hdfsPath = new Path(hdfsFile);
try {
// 获取本地文件系统
FileSystem localFs = FileSystem.getLocal(conf);
// 获取HDFS文件系统
FileSystem hdfs = FileSystem.get(conf);
// 本地文件系统中指定目录中的所有文件
FileStatus[] status = localFs.listStatus(localPath);
// 打开HDFS上文件的输出流
FSDataOutputStream out = hdfs.create(hdfsPath);
// 循环遍历本地文件
for (FileStatus fileStatus : status) {
// 获取文件
Path path = fileStatus.getPath();
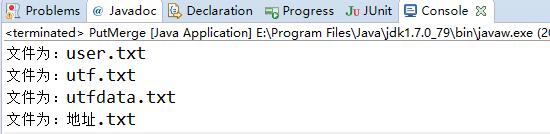
System.out.println("文件为:" + path.getName());
// 打开文件输入流
FSDataInputStream in = localFs.open(path);
// 进行流的读写操作
byte[] buf = new byte[1024];
int len = 0;
while ((len = in.read(buf)) != -1) {
out.write(buf, 0, len);
}
in.close();
}
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String localDir = "E:/java_workspace/Hadoop Project/测试putmerge";
String hdfsFile = "hdfs://H01:9000/dataa/测试putmerge.txt";
put(localDir, hdfsFile);
}
}
















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









