







读写分离
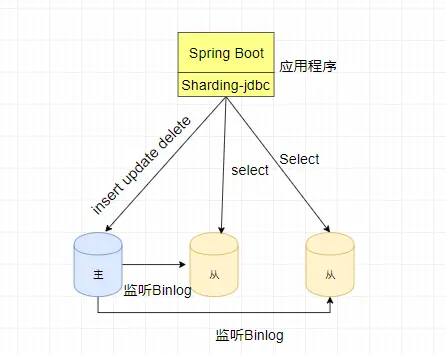
在上一篇文章介绍了如何使用Sharing-JDBC实现数据库的读写分离。读写分离的好处就是在并发量比较大的情况下,将查询数据库的压力 分担到多个从库中,能够满足高并发的要求。比如上一篇实现的那样,架构图如下:
image
数据分表
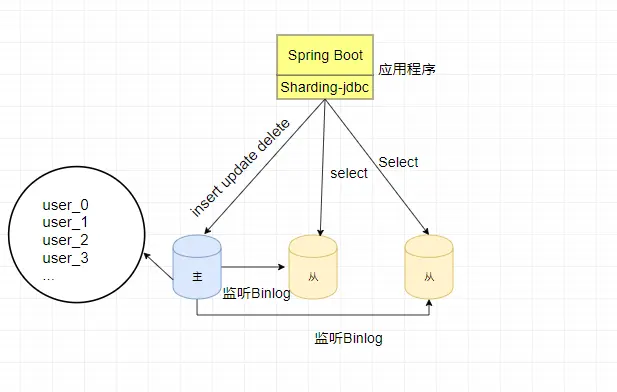
当数据量比较大的时候,比如单个表的数据量超过了500W的数据,这时可以考虑将数据存储在不同的表中。比如将user表拆分为四个表user0、user1、 user2、user3装在四个表中。此时如图所示:
image
案例详解
和上一篇文章使用的数据库是同一个数据库,数据库信息如下:
| 数据库类型 | 数据库 | ip |
|---|---|---|
| 主 | cool | 10.0.0.3 |
| 从 | cool | 10.0.0.13 |
| 从 | cool | 10.0.0.17 |
在主库初始化Mysql数据的脚本,初始化完后,从库也会创建这些表,脚本信息如下:
1. `USE `cool`;`
3. `/*Table structure for table `user_0` */`
5. `DROP TABLE IF EXISTS `user_0`;`
7. `CREATE TABLE `user_0` (`
8. ``id` int(12) NOT NULL AUTO_INCREMENT,`
9. ``username` varchar(12) NOT NULL,`
10. ``password` varchar(30) NOT NULL,`
11. `PRIMARY KEY (`id`),`
12. `KEY `idx-username` (`username`)`
13. `) ENGINE=InnoDB AUTO_INCREMENT=149 DEFAULT CHARSET=utf8;`
15. `/*Table structure for table `user_1` */`
17. `DROP TABLE IF EXISTS `user_1`;`
19. `CREATE TABLE `user_1` (`
20. ``id` int(12) NOT NULL AUTO_INCREMENT,`
21. ``username` varchar(12) NOT NULL,`
22. ``password` varchar(30) NOT NULL,`
23. `PRIMARY KEY (`id`),`
24. `KEY `idx-username` (`username`)`
25. `) ENGINE=InnoDB AU 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









