







目录
1. 概述
1.1 分词:
指将一个中文词语拆成若干个词,提供搜索引擎进行查找,比如说:北京大学 是一个词那么进行拆分可以得到:北京与大学,甚至北京大学整个词也是一个语义。可以理解为,输入的一句话,按照它自己定义的规则分为常用词语。
首先,Solr有自己基本的类型,string、int、date、long等等。对于string类型,比如在你的core/conf/manage-schema文件中,配置一个字段类型为string类型,如果查询符合“我是中国人”的数据,它就认为“我是中国人”是一个词语。
但是如果你将该字段设置成了分词,即配置成了text_ik类型,就可能匹配“我”、“中国人”、“中国”、“中”、“人”带有这些字的该字段数据都可能被查询到。这就是分词带来的结果。具体要按照各自的业务来配置是否分词,分词对于大文本字段设置是合理的,但是对于小字段,设置分词是没必要的,甚至有相反的结果。比如你的某一个叫姓名的字段设置了分词,还不如设置string,查询时模糊匹配效果最好,(模糊匹配就是查询条件两边加上*),当然也要看自己业务需求是什么。
1.2 配置目的
通过配置让solr能对中文进行分词
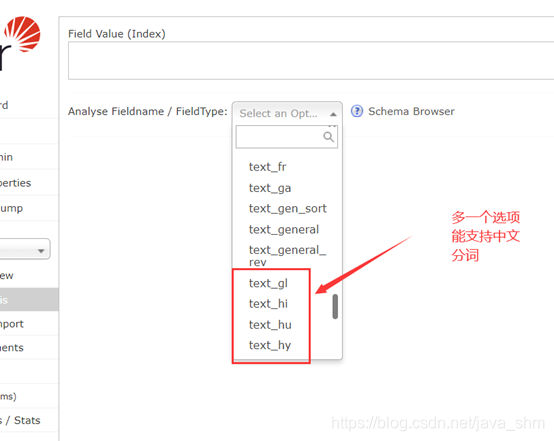
1.3 分词器的选择
之前我们使用jieba分词,效果不是很好。现在有个非常牛逼的分词器,IK 分词器,效果非常好,如果你一直使用solr 那么以后将一直使用IK分词器。中文分词在solr里面是没有默认开启的,需要自己配置一个中文分词器。
目前可用的分词器有smartcn,IK,Jeasy,庖丁。其实主要是两种,一种是基于中科院ICTCLAS的隐式马尔科夫HMM算法的中文分词器,如smartcn,ictclas4j,优点是分词准确度高,缺点是不能使用用户自定义词库;另一种是基于最大匹配的分词器,如IK ,Jeasy,庖丁,优点是可以自定义词库,增加新词,缺点是分出来的垃圾词较多。各有优缺点。
主流还是ik,可以扩展自己的词库,非常方便,加入一些热搜词,主题词,对于搜索而言,非常方便
2. 分词器的配置
2.1 下载
下载ik (5及以上版本通用)
http://files.cnblogs.com/files/zhangweizhong/ikanalyzer-solr5.zip
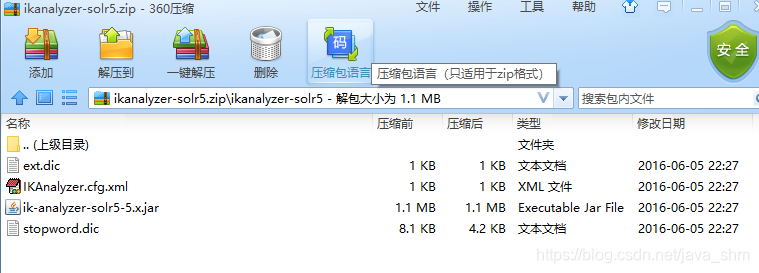
- ext.dic自定义词 如沙雕 在汉语里面不是一个词 ,它只是一个网络用语,可以配置到这里面让它成为一个词
- stopword.dic 停止字典, 如:啊 吧 唉 不作分词
- IKAnalyzer.cfg.xml配置ik的配置文件 不用改
- Jar:如果要使用ik分词要导入的jar包
2.2 修改managed-sahma
<!--添加一个中文分词器IK-->
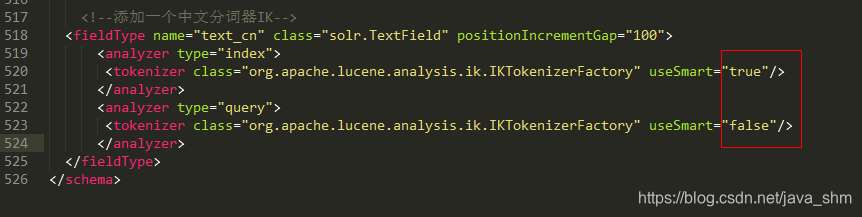
<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
</fieldType>
useSmart 和分词的粒度相关:
- false: 分词的粒度大,一句话里面分的词语少
- true:分词的粒度细,一句话里面分的词语多
那我们在导入时需要的关键字多吗?让索引的数据量少一点。我们的粒度大:false;我们在搜索时需要的关键字多吗?我们想尽可能的覆盖所有的范围,我们的粒度要细:true
把修改后的managed-sahma覆盖到solr
2.3 把IK的配置入到solr
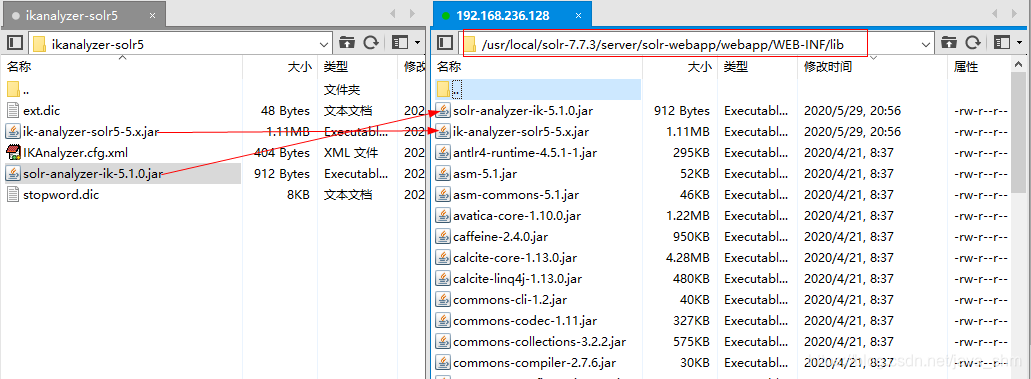
2.3.1 放入jar包
/usr/local/solr-7.7.3/server/solr-webapp/webapp/WEB-INF/lib
2.3.2 放配置
在目录/usr/local/solr-7.7.3/server/solr-webapp/webapp/WEB-INF下创建一个classes目录
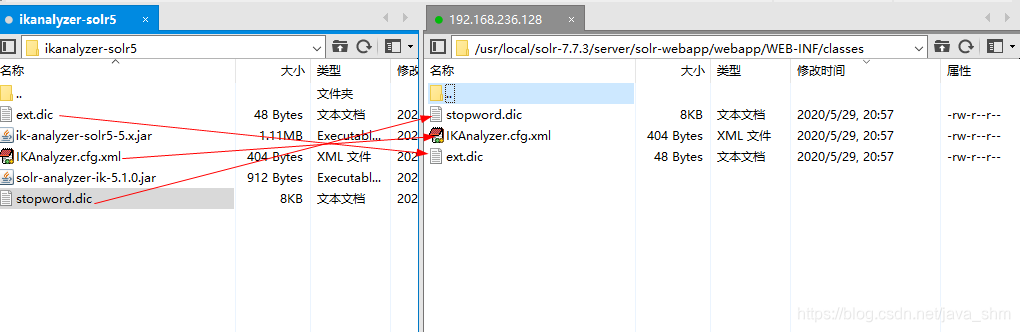
2.4 重启solr分析
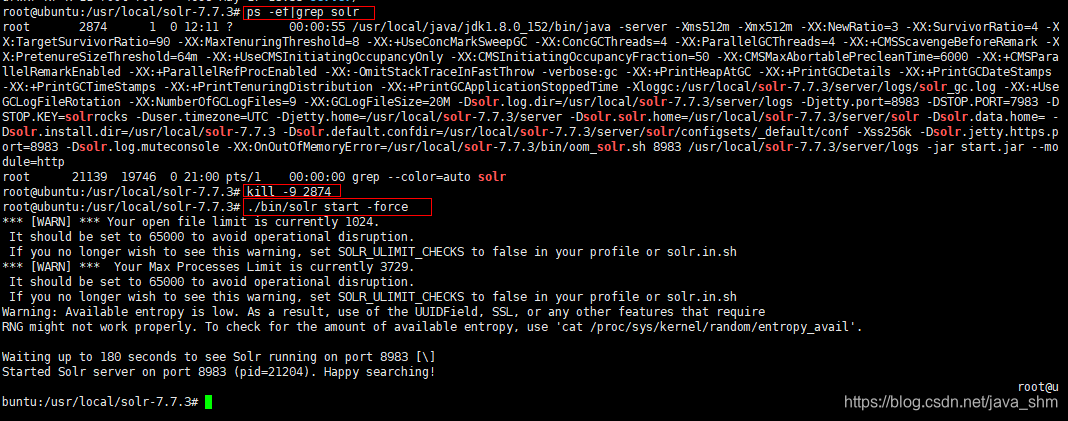
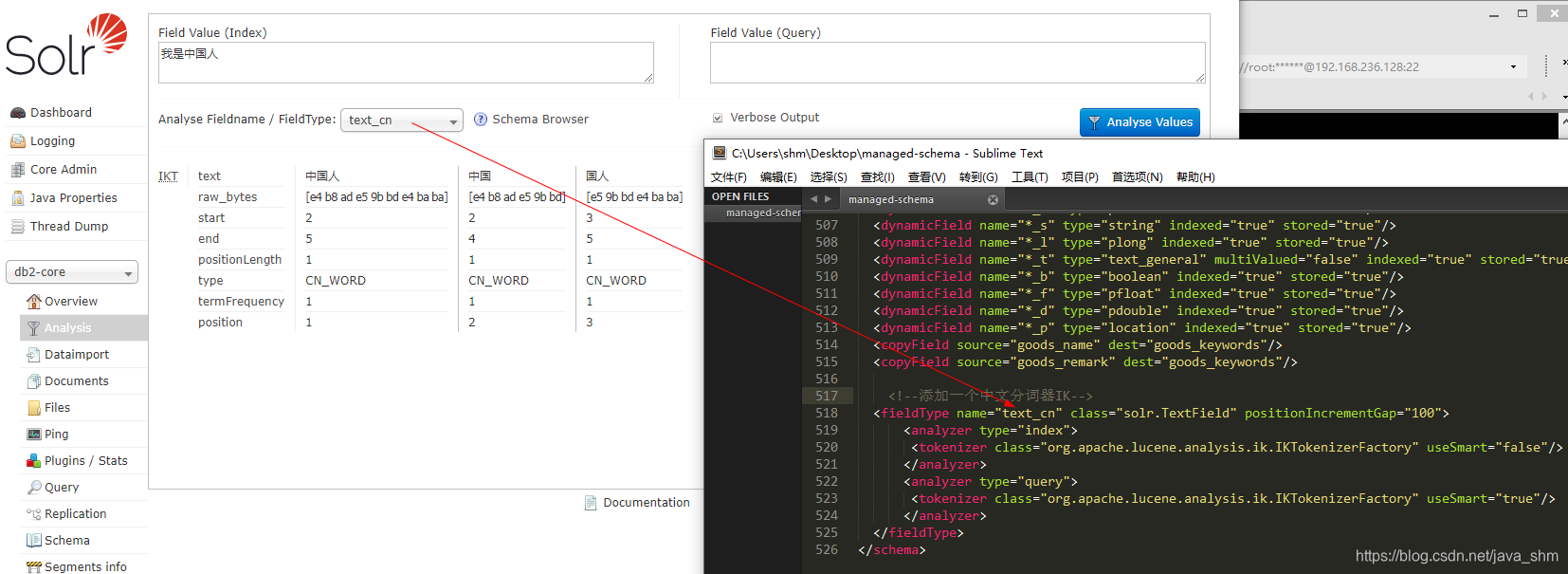
2.5 存在问题
索引时要遵循一个原则:
- 索引时分词的要尽量少
- 搜索时分词尽量多
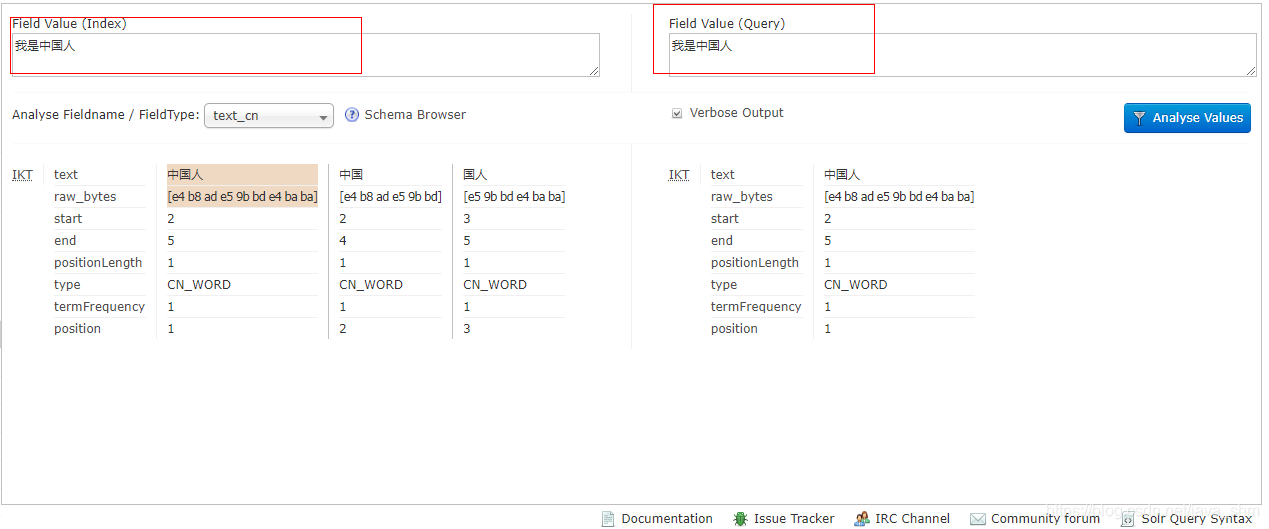
修改配置:
3.中文分词如何使用到属性上
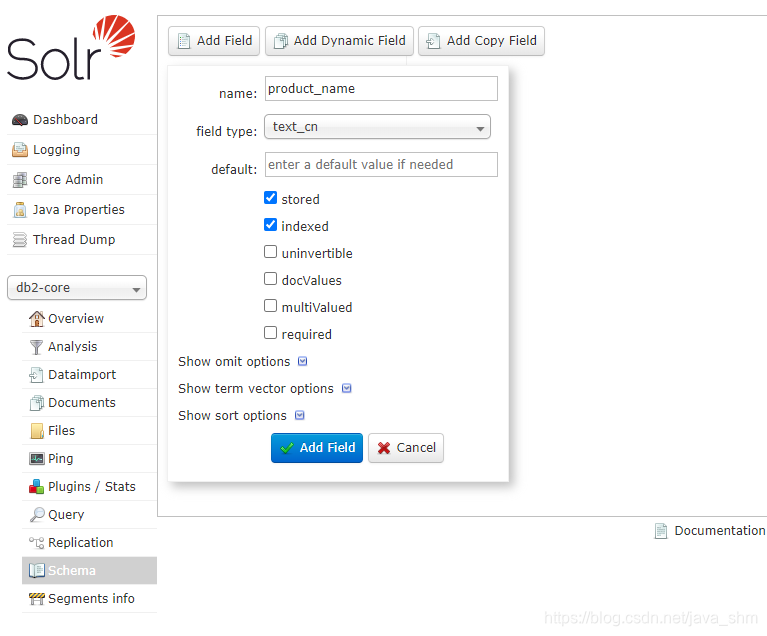
3.1 添加一个属性
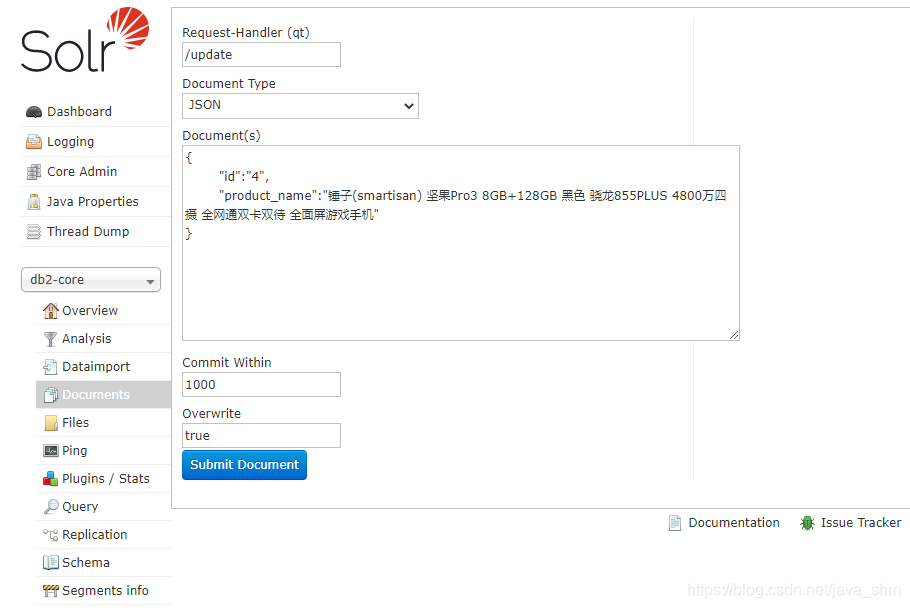
3.2 添加数据
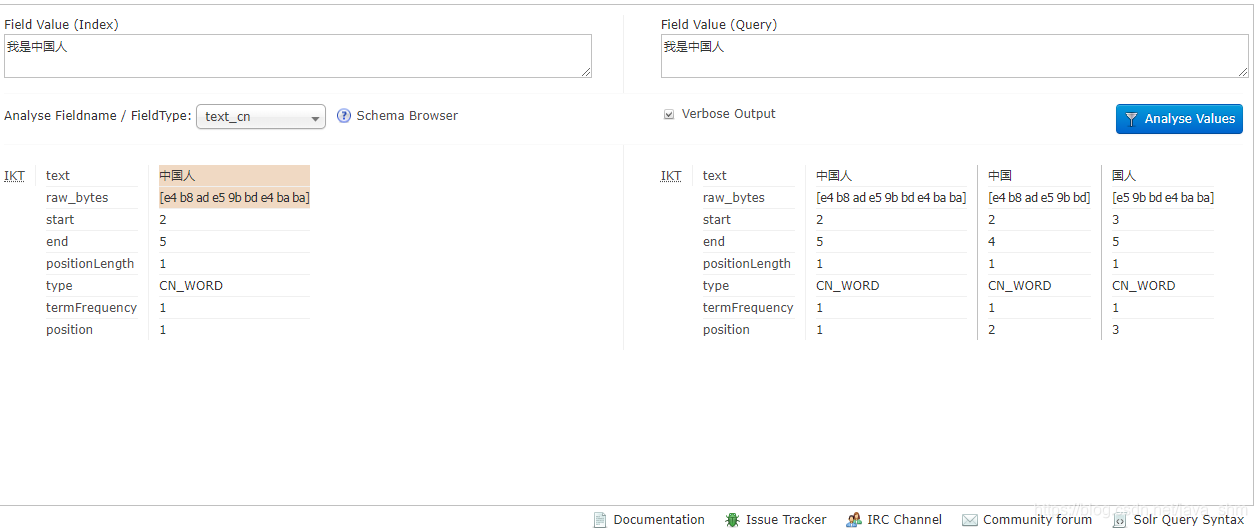
3.3 查看分词
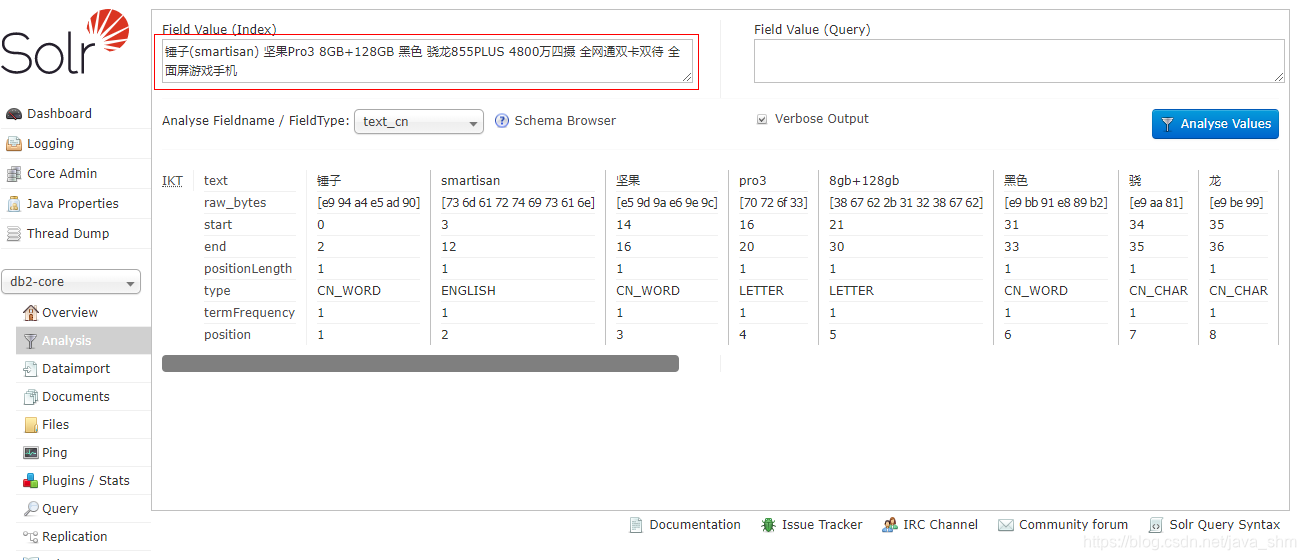
3.4 查询测试
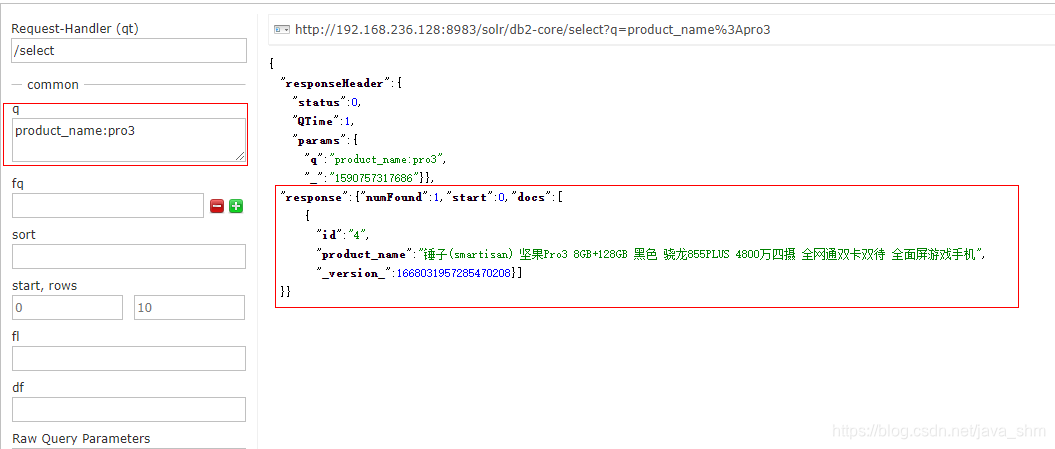
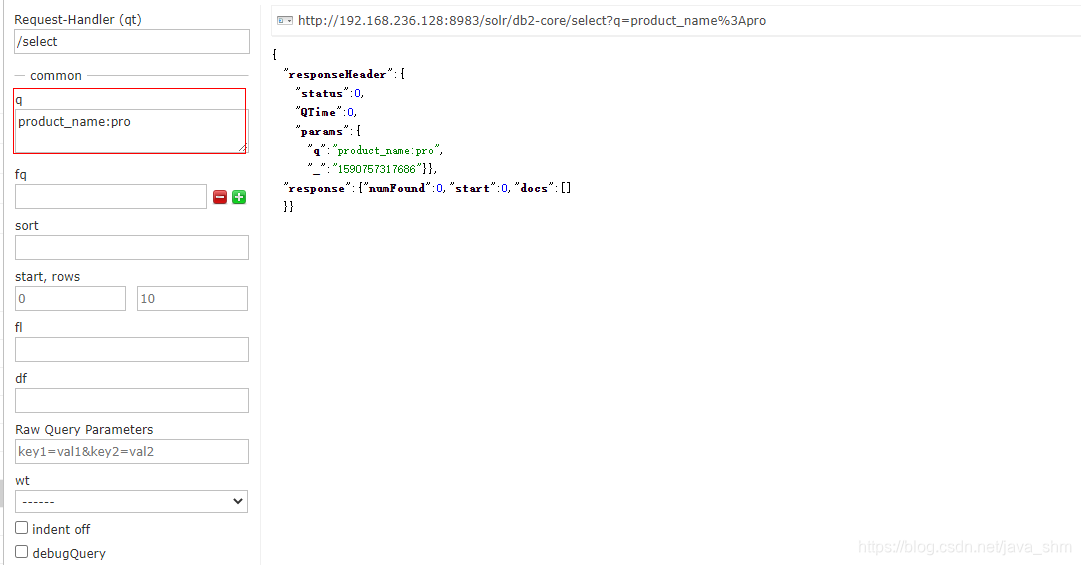
为什么pro3有 pro没有 因为ik分词时认为pro3是一个词 而pro不是词
4. 自定义分词
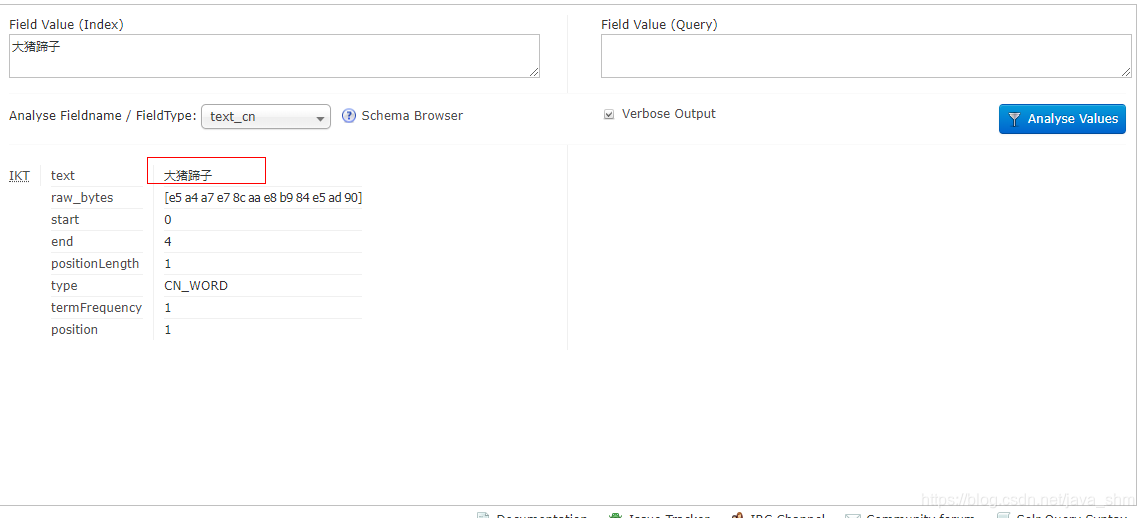
如:“大猪蹄子”默认并不是一个词
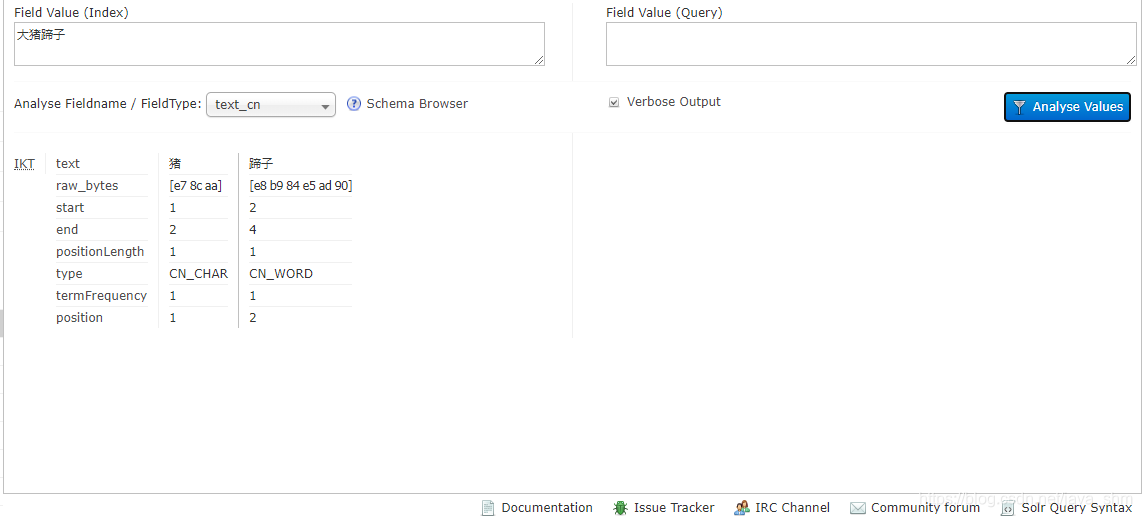
在ext.dic里添加一个自定义的词
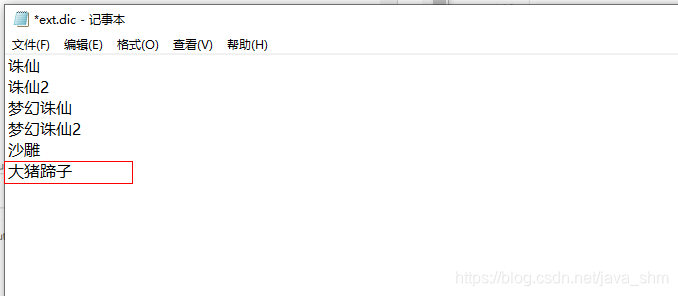
重启测试
申明:内容来自网络,仅供学习使用

















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









