






前言
聚类分析的研究成果主要集中在基于距离(或者称为基于相似度)的聚类方法,用距离来作为相似性度量的优点是十分直观,从我们对物体的识别角度来分析,同类的数据样本是相互靠近的,不同类样本应该相聚较远。k-means聚类算法是划分聚类方法中最常用、最流行的经典算法,许多其他的算法都是k-means聚类算法的变种。其主要思想是通过迭代过程将数据集划分为不同类别,使评价聚类性能的准则函数达到最优,使生成的每个聚类类内紧凑,类间独立。
本文用到的数据来自我的一门数据分析课程,是一个包括了286名NBA球员数据的csv表格。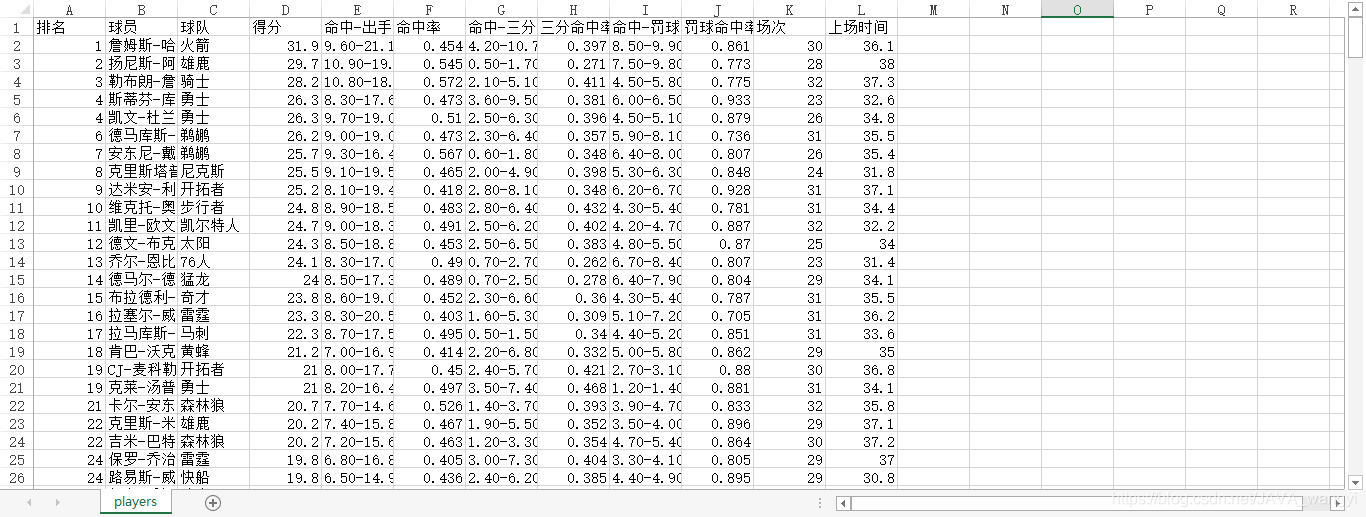
本章工具
- Anaconda3下的Jupyter Notebook编译器
- python3.7环境
在jupyter notebook读取数据:
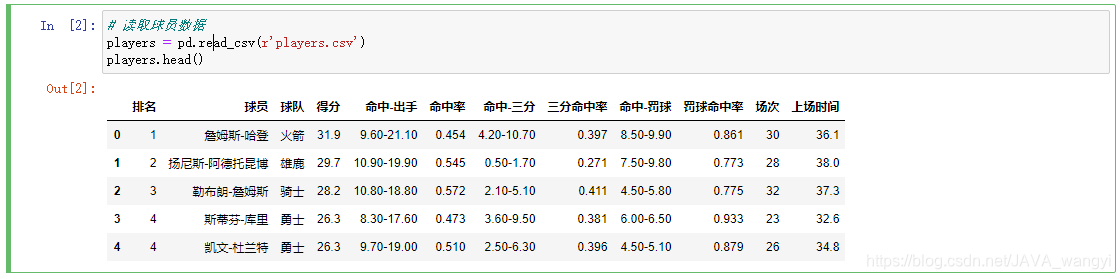
通过seaborn包中的lmplot函数绘出散点图,可以看到数据的大致分布: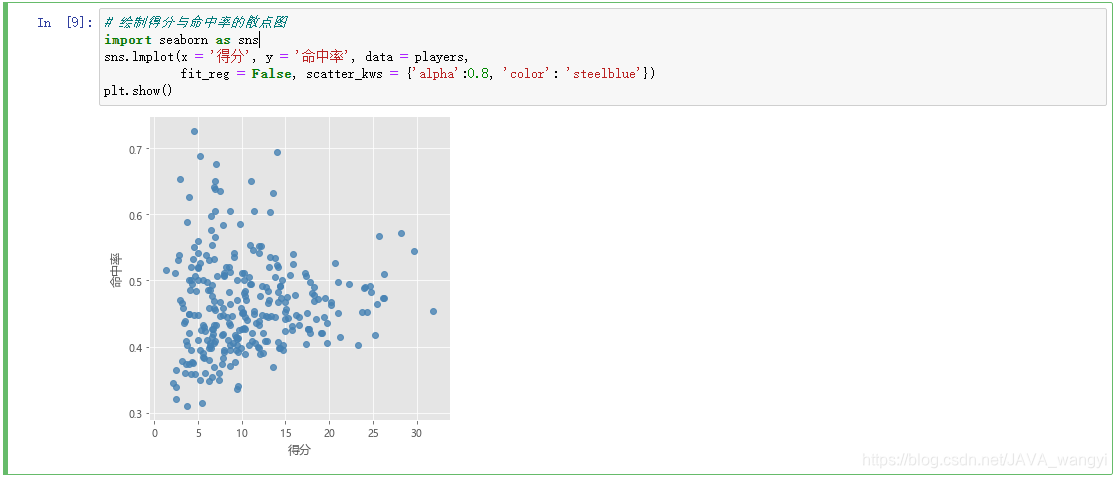
k-means介绍
k-means原理
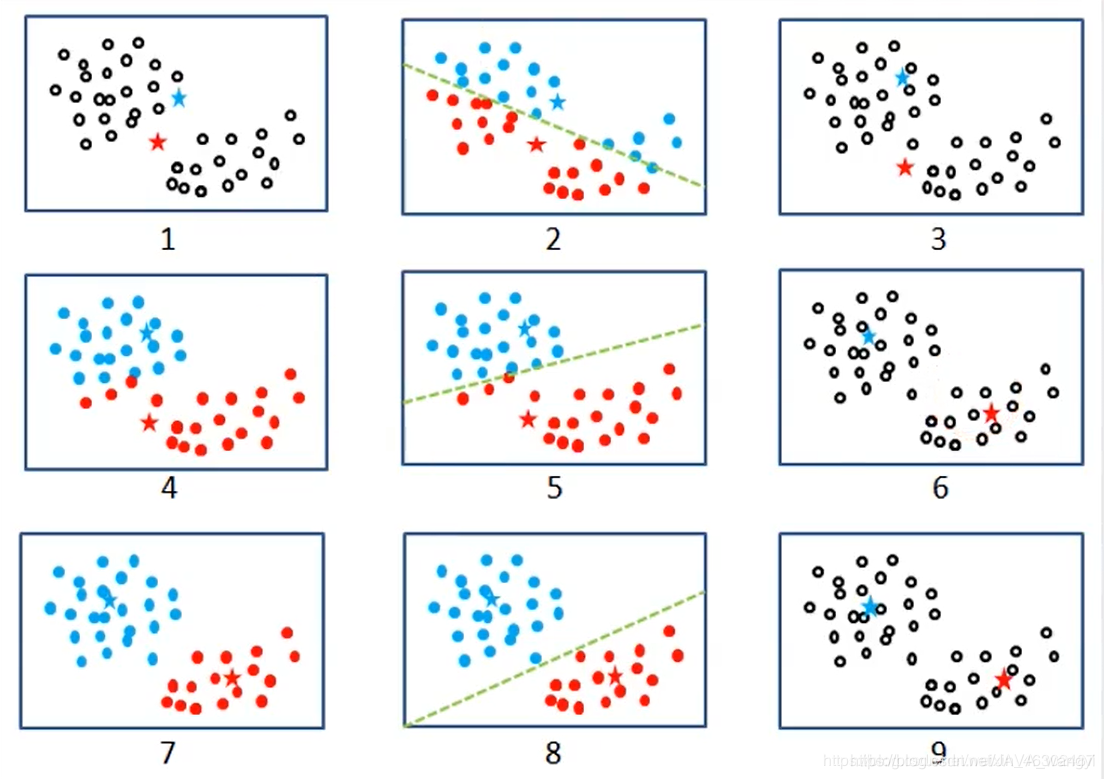
Kmeans聚类算法的思路通俗易懂,通过不断计算各样本点与簇中心的距离,直到收敛为止,具体步骤如下:
1.从数据中随机挑选k个样本点作为原始的簇中心
2.计算剩余样本与簇中心的距离,并把各样本标记为离k个簇中心最近的类别
3.重复计算各簇中样本点的均值,并以均值作为新的k个簇中心
4.重复2、3步骤,直到簇中心的变化趋势趋于稳定,形成最终的k个簇
如下图所示
Python提供了实现该算法的模块——sklearn,我们只需要调用其子模块cluster中的Kmeans类即可,该“类”的语法和参数含义如下:
Kmeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001,
precompute_distances='auto', verbose=0, random_state=None,
copy_x=True, n_jobs=1, algorithm='auto')
- n_clusters:用于指定聚类的簇数
- init:用于指定初始的簇中心的设置方法,如果为’k-means++’,则表示设置的初始簇中心相距较远;如果为’random’则表示从数据集中随机挑选k个样本作为初始簇中心;如果为数组,则表示用户指定具体的初始簇中心
- n_init:用于指定Kmeans算法的运行次数,每次运行时都会选择不同的初始簇中心,目的是防止算法收敛于局部最优,默认为10
- max_iter:用于指定单次运行的迭代次数,默认为300
- tol:用于指定算法的收敛阈值,默认为0.0001
- precompute_distances:bool类型参数,是否在算法运行之前计算样本之间的距离,默认为’auto’,表示当样本量与变量个数的乘积大于1200万时不计算样本之间的距离
- verbose:通过该参数设置算法返回日志信息的频度,默认为0,表示不输出日志信息;如果为1,就表示每隔一段时间返回日志信息
- random_state:用于指定随机数生成器的种子
- copy_X:bool类型参数,当参数precompute_distances为True时有效,如果该参数为True,就表示提前计算距离时不改变原始数据,否则会修改原始数据
n_jobs:用于指定算法运行时的CPU数量,默认为1,如果为-1,就表示使用所有可用的CPU - algorithm:用于指定Kmeans的实现算法,可以选择’auto’‘full’和’elkan’,默认为’auto’,表示自动根据数据特征选择运算的算法
最佳k值的确定
本文使用了两种常用的评估方法,用于确定最佳k值:“簇内离差平方和拐点法”、“轮廓系数法”
拐点法
在不同的k值下计算簇内的离差平方和,然后通过可视化的方法找到“拐点”所对应的k值。
# 构造自定义函数,用于绘制不同k值和对应总的簇内离差平方和的折线图
def k_SSE(X, clusters):
# 选择连续的K种不同的值
K = range(1,clusters+1)
# 构建空列表用于存储总的簇内离差平方和
TSSE = []
for k in K:
# 用于存储各个簇内离差平方和
SSE = []
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
# 返回簇标签
labels = kmeans.labels_
# 返回簇中心
centers = kmeans.cluster_centers_
# 计算各簇样本的离差平方和,并保存到列表中
for label in set(labels):
SSE.append(np.sum((X.loc[labels == label,]-centers[label,:])**2))
# 计算总的簇内离差平方和
TSSE.append(np.sum(SSE))
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
# 绘制K的个数与GSSE的关系
plt.plot(K, TSSE, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('簇内离差平方和之和')
# 显示图形
plt.show()
from sklearn import preprocessing
# 数据标准化处理
X = preprocessing.minmax_scale(players[['得分','罚球命中率','命中率','三分命中率']])
# 将数组转换为数据框
X = pd.DataFrame(X, columns=['得分','罚球命中率','命中率','三分命中率'])
k_SSE(X, 15)

通过离差平方和的折线图我们能发现k值最好取在3、4、5之间,但还是很难通过观察找到最佳的k值。于是我们可以用下文的第二个方法:轮廓系数法。
轮廓系数法
该方法综合考虑了簇的密集性与分散性两个信息,如果数据集被分割为理想的k个簇,那么对应的簇内样本会很密集,而簇间样本会很分三,轮廓系数的计算公式如下:
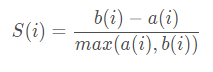
其中,a(i)体现了簇内的密集性,代表样本i与同簇内其他样本点距离的平均值;b(i)反映了簇间的分散性,其计算过程是:样本i与其他非同簇样本点距离的平均值,然后从平均值中挑选出最小值。
有关轮廓系数的计算,我们可以直接调用sklearn子模块metris中的函数silhouette_score。该函数接受的聚类簇数必须大于或等于2,下面基于该函数重新自定义一个函数,用于绘制不同k值下对应轮廓系数的折线图,具体代码如下所示:
# 构造自定义函数,用于绘制不同k值和对应轮廓系数的折线图
def k_silhouette(X, clusters):
K = range(2,clusters+1)
# 构建空列表,用于存储个中簇数下的轮廓系数
S = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_
# 调用字模块metrics中的silhouette_score函数,计算轮廓系数
S.append(metrics.silhouette_score(X, labels, metric='euclidean'))
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
# 绘制K的个数与轮廓系数的关系
plt.plot(K, S, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('轮廓系数')
# 显示图形
plt.show()
k_silhouette(X, 10)
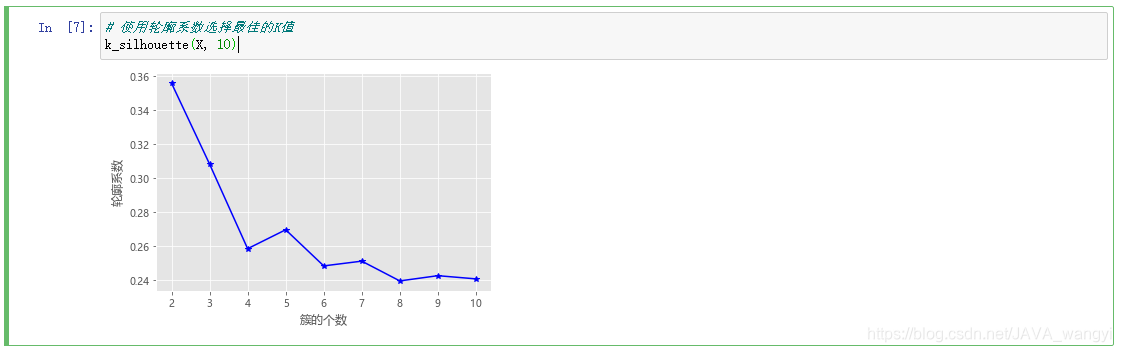
观察不同k值轮廓系数折线图,我们能发现k=2时轮廓系数最大,总体随k值增大而递减,但是最大也只有0.36左右,并不能达到约等于1的理想值,所以我们综合轮廓系数法和拐点法,在之前的结论3、4、5中选出最合适的k值:3。
聚类运算
在上面的结论下,我们把该数据聚集为三类:
# 将球员数据集聚为3类
kmeans = KMeans(n_clusters = 3)
kmeans.fit(X)
# 将聚类结果标签插入到数据集players中
players['cluster'] = kmeans.labels_
# 构建空列表,用于存储三个簇的簇中心
centers = []
for i in players.cluster.unique():
centers.append(players.loc[players.cluster == i,['得分','罚球命中率','命中率','三分命中率']].mean())
# 将列表转换为数组,便于后面的索引取数
centers = np.array(centers)
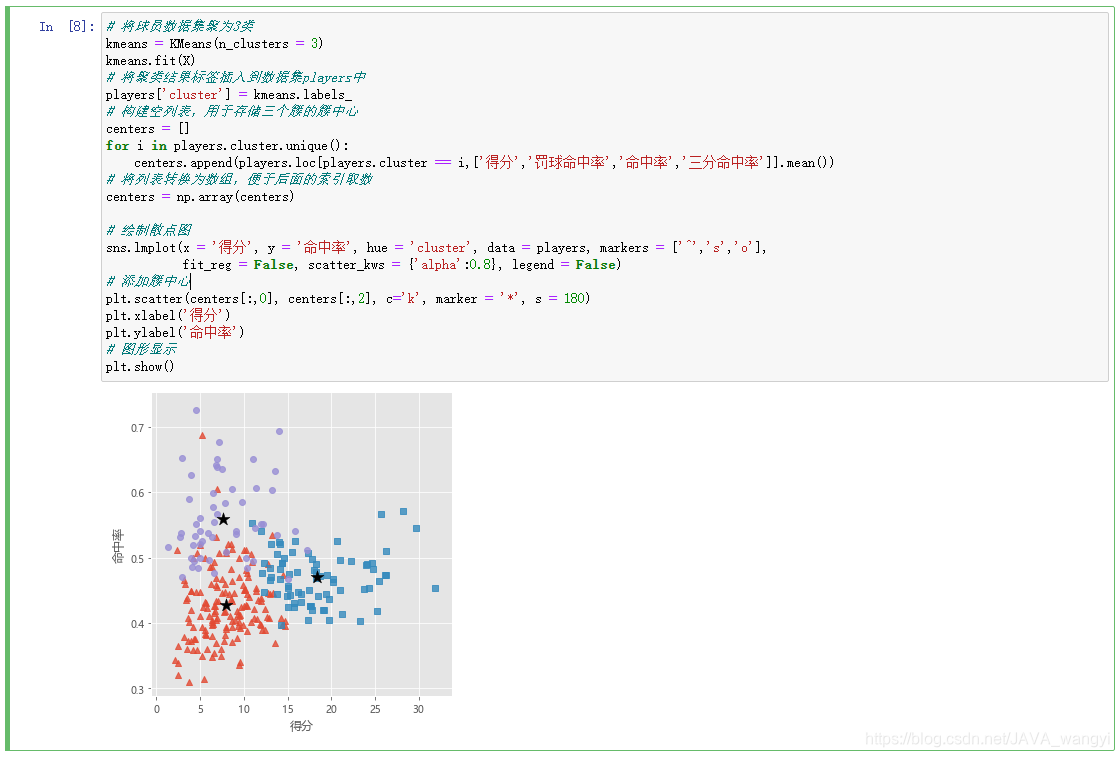
# 绘制散点图
sns.lmplot(x = '得分', y = '命中率', hue = 'cluster', data = players, markers = ['^','s','o'],
fit_reg = False, scatter_kws = {'alpha':0.8}, legend = False)
# 添加簇中心
plt.scatter(centers[:,0], centers[:,2], c='k', marker = '*', s = 180)
plt.xlabel('得分')
plt.ylabel('命中率')
# 图形显示
plt.show()
结果分析
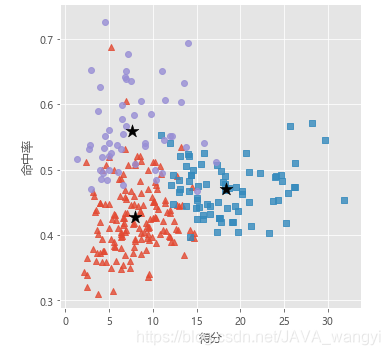
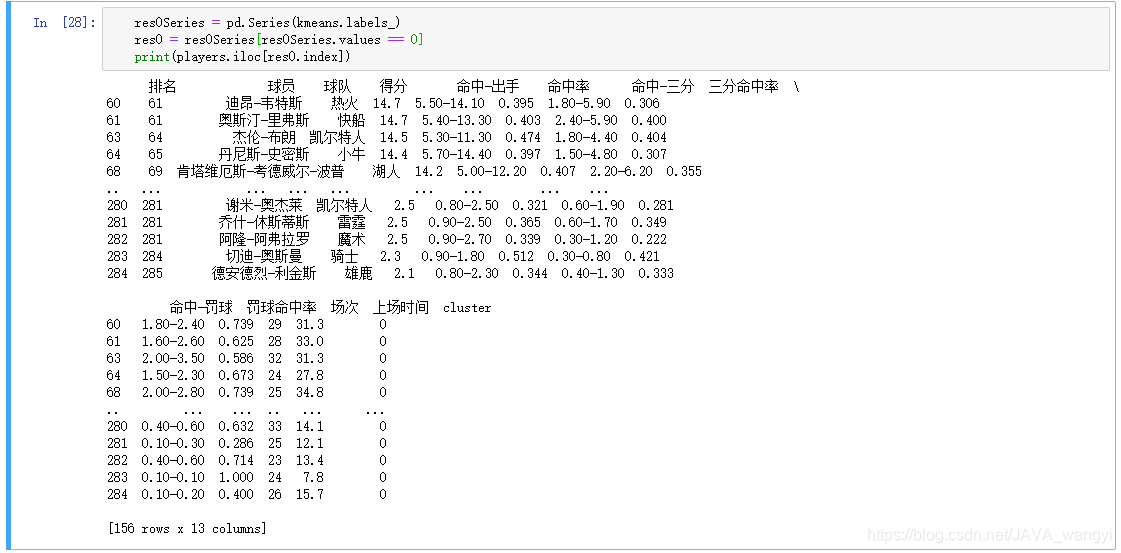
 从最终的结论图中我们不难发现,第一类红色部分表示该球员得分相对较低且命中率也较低,我们可以总结为得分能力不强的组织型球员,总样本中占156人。以下是此类球员名单:
从最终的结论图中我们不难发现,第一类红色部分表示该球员得分相对较低且命中率也较低,我们可以总结为得分能力不强的组织型球员,总样本中占156人。以下是此类球员名单:
res0Series = pd.Series(kmeans.labels_)
res0 = res0Series[res0Series.values == 0]
print(players.iloc[res0.index])
第二类用紫色圆点表示,其得分低但命中率很高,我们可以归类为上场及进攻次数较少的新秀球员,占54人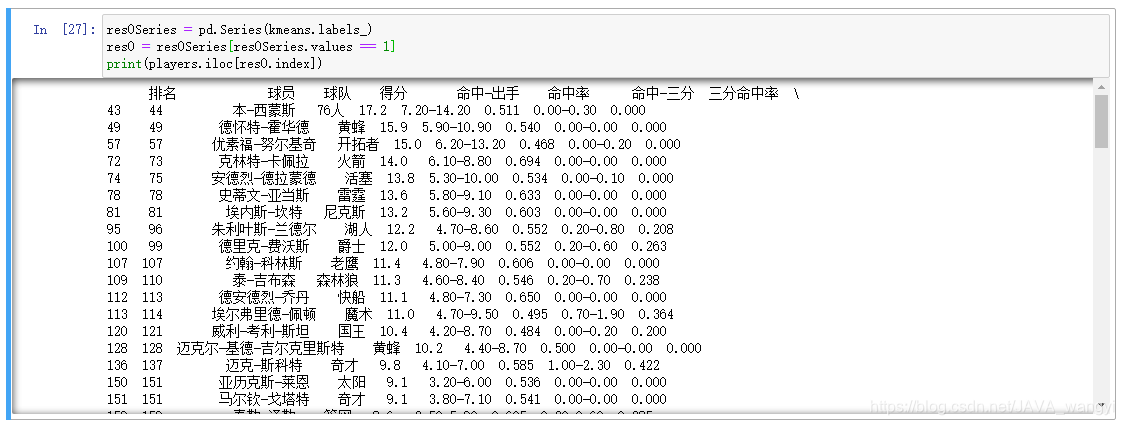
蓝色正方形表示的球员属于第三类,特点是得分高、命中率高,我们总结其为职业生涯巅峰球员,各个球队的得分机器,样本中有76人。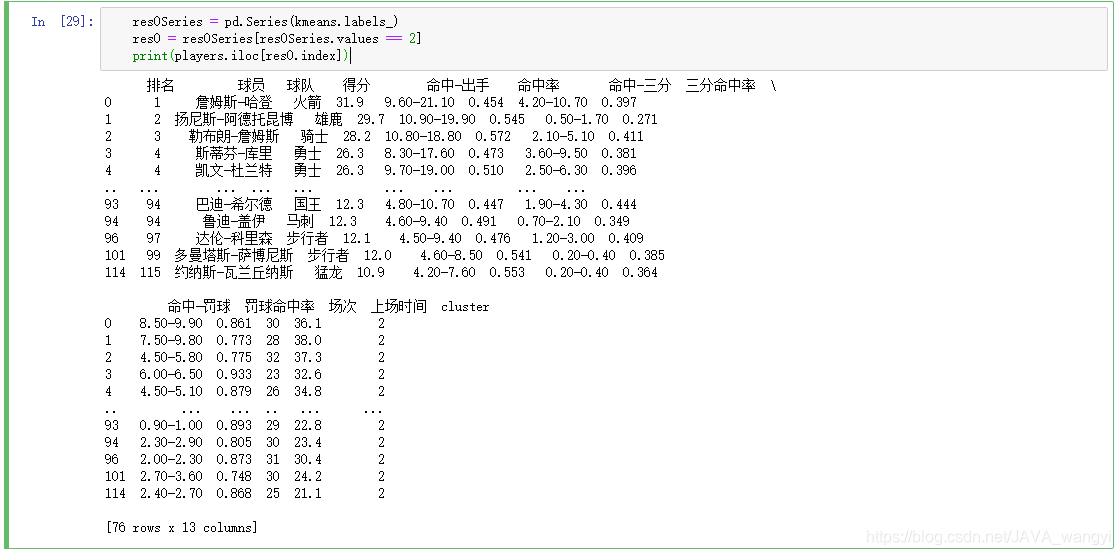
小结
本篇介绍并实践了一种无监督的聚类算法——Kmeans聚类,在对NBA球员数据集进行聚类之后,我们通过观察聚类的结果,可以对比球员的好坏,在实际应用中可以帮助我们进行人才的挑选。
参考文献
- 《数据仓库与数据挖掘》陈志泊主编 清华大学出版社
- 《从零开始学数据分析与挖掘》 刘顺祥著 清华大学出版社
- 还要感谢博客上大神们的帖子,我从中学到了很多,帮助我解决了很多问题














 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









