







机器学习之K-means聚类分析NBA球员案例
本次案例利用k-means算法分析NBA球员球队实力,具体采用2种方式实现案例,一种为自己实现,一种为调用sklearn库,数据来源nba_2013.csv。
k-means的计算理解过程:
1.从集合D中随机选取k个元素,作为k个簇的各自的中心;
2.分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇;
3.根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有的元素各自维度的算术平均数;
4.将D中全部元素按照新的中心重新聚类;
5.重复第4步,直到聚类结果不再变化;
6.将结果输出。
2.数据处理及分析
2.1.数据导入
导入数据集
Player-球员名称
Age–年龄
Bref_team_id–战队名
程序编写:
数据集内容输出截图:

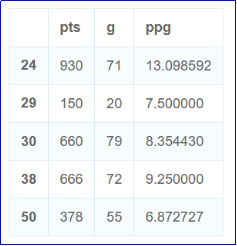
2.2取出后卫的数据
程序编写:

结果截图:
2.3定义失误次数及助攻次数
程序编写:

结果图展示:

使用K-means聚类时,
第一步:当k=5时,他会随机选取5个点作为中心点,然后计算所有点到这5个点的距离
第二步:将每一个点划到不同的簇
第三步:将每一个簇中的点计算横纵坐标的均值,计算出新的中心点(可以是不是实际的点)
第四步:重新计算每一个点到中心点的距离,重新划分属于不同的簇
第五步:不断的更新中心点,不断的重新划分簇,直到再怎么更新中心点,簇里的元素都不再发生变化了
2.4 随机选出5个点并选出中心点
程序编写:

2.5 编写程序输出初始化后的中心点

点位图

2.6将中心点的信息保存再字典里:

结果截图:

2.7计算距离 程序编写

输出距离值

2.8对所有数据选择自己的中心点,进行分类

2.9对每行的数据进行比较,得出这一行数据最近的中心点,属于这一簇

2.10将结果显示出来

将分类的数据显示出来

2.11重新计算中心点

2.12重新计算中心点,对所有点进行重新划分中心点,并将分类的数据显示出来

3、利用库函数实现
导入数据:
from sklearn.cluster import KMeans
调用sklearn的库函数,只需指定需要分类的个数

结果点位图
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









